Wzrost znaczenia sztucznej inteligencji w codziennym życiu rodzi przed tego typu wyzwania i problemy, które nie były tak głośne i palące w fazie badań akademickich nad nimi. Tymczasem spodziewana wielowymiarowość zadań przejmowanych przez AI i dziedzin życia, w których będzie się pojawiać zmusza do zadania pytania o takie problemy jak rozumienie ich działania, możliwości samoprogramowania się, oraz przede wszystkim o perspektywie utraty kontroli nad systemami AI. Czy to możliwe, że to właśnie poziom zaawansowania sztucznej inteligencji i jej skomplikowanie paradoksalnie sprawi, że brak dostatecznej kontroli nad nią zmusi nas do rezygnacji z przełomów, które obiecujemy sobie po tej technologii?
Czy AI można zrozumieć – ‘interpretability’ oraz ‘explainabiity’
Najnowsze postępy w technologii sztucznej inteligencji sprawiają, że z coraz to różnych stron słyszymy o wykorzystaniu jej przez kolejne organizacje. Nowo wdrażane algorytmy uczenia maszynowego co dzień mają wpływ na życie wielu ludzi, jednak ich skomplikowanie i nietransparentność działania mogą znacznie utrudniać zrozumienie jak owe decyzje są podejmowane. Z tym tematem związane są 2 pojęcia – interpretowalności i wyjaśnialności (z ang. Interpretability and Explainability).
Interpretowalność rozumiemy jako zdolność do zrozumienia procesu decyzyjnego jaki zachodzi wewnątrz modelu AI. Model intepretowalny dostarcza wystarczających informacji, aby wykazać związek pomiędzy danymi wejściowymi a wyjściowymi. Innymi słowy skupiamy się tutaj na dokładnym wyjaśnieniu procesów jakie zaszły wewnątrz modelu, które miały wpływ na ostateczny wynik procesu decyzyjnego.
Wyjaśnialność, to również możliwość zrozumienia procesu decyzyjnego modelu AI, ale w taki sposób, aby był on zrozumiały i możliwy do zakomunikowania dla użytkownika końcowego – zatem zawiera jasne i intuicyjne uzasadnienia dlaczego model podjął taką, a nie inną decyzję. Wyjaśnialność możemy po prostu rozumieć, jako przedstawienia odpowiedzi na pytanie dlaczego model podjął daną decyzję oraz jak może być ona uzasadniona w kontekście obiektywnych faktów.
Jak wynika z definicji oba te podejścia do rozumienia modeli AI są niezwykle istotne w ich dalszym rozwoju i odkrywaniu nowych aplikacji dla nich. Skupienie się na rozwoju charakterystyk składających się na rozumienie AI dać może wiele korzyści w szybko postępującym wdrażaniu algorytmów sztucznej inteligencji. W tym kontekście wymienić można w szczególności:
Odpowiedzialność
rozumienie działania modelu AI i zachodzących procesów decyzyjnych pozwolić może na przewidywanie i uwzględnienie możliwych ich konsekwencji, a w efekcie, rozwiązanie pewnych problemów z określeniem odpowiedzialności i rozliczalności stron zaangażowanych we wdrażania i użytkowanie technologii AI,
Zaufanie
zrozumienie modeli AI za pośrednicwem ich interpretowalności i wyjaśnialności zwiększy zaufanie społeczeństwa do tych rozwiązań, co zapewni bardziej przychylne stanowisko w temacie ich wdrażania,
Adaptacja
dogłębne poznanie algorytmów sztucznej inteligencji – z ich zaletami i wadami, pomoże w dalszym wdrażaniu, adaptacji i optymalizacji w czasie,
Zgodność z przepisami
większa transparentność procesów decyzyjnych modeli AI pozwoli na łatwiejsze definiowanie i sprawdzanie zgodności z regulacjami prawnymi oraz wymaganiami etycznymi czy technicznymi,
Ograniczanie tzw. “algorithmic bias”
większe zrozumienie działania modeli sztucznej inteligencji pozwoli na łatwiejszą identyfikację, a w konsekwencji również eliminację tzw. algorytmicznych uprzedzeń i stronniczości algorytmów związanych z naturalnie występującymi uprzedzeniami u ludzi projektujących owe algorytmy, czy też w zbiorach danych stosowanych do uczenia modeli.
Sposoby na poprawę zrozumienia modeli AI
Metody wizualizacji
Zwizualizowanie zarówno danych jak i modelu, może ułatwić zrozumienie działania modeli AI. Przykładowo tzw. “heap maps” mogą posłużyć do wizualizacji istotności poszczególnych cech branych pod uwagę przez algorytm w trakcie procesu decyzyjnego modelu.

Techniki dekompozycji
Rozłożenie procesu decyzyjnego na pojedyncze komponenty (pojedyncze reguły decyzyjne), przez co staje się on prostszy do zrozumienia.
Wyjaśnienia oparte o przykłady
Przedstawienie użytkownikowi innych, podobnych do tych poddanych analizie, zestawów danych wejściowych, które ułatwić mogą zrozumienie podejmowanej decyzji. Użytkownik może w sposób empiryczny wywnioskować jakie czynniki brane są pod uwagę w ewaluacji danych dostarczanych do modelu.
Metody analizy post-hoc
Różnego rodzaju metody, aplikowane po dokonaniu decyzji przez model, które mają pomóc określić co miało na nią wpływ. Może to polegać na podkreśleniu, które cechy miały największą wagę w całym procesie decyzyjnym.
Bez wątpienia wyjaśnialność systemów AI jest konieczna, aby otworzyć kolejne dziedziny naszego życia na tą technologię. Cieżko sobie wyobrazić ich zaawansowane wykorzystanie w domenach, które opierają się na dogłębnym zaufaniu do nauki czy też ekspertyzy człowieka podejmującego ważkie decyzje – jak np. pewne zagadnienia medycyny, inżynierii czy wojskowości. W tych to przypadkach niezwykle istotne w szerokim wdrożeniu będą transparentność i kontrolowalność modeli, których to bez uprzedniego zrozumienia działania tej technologii po prostu nie osiągniemy.
The alignment problem – czyli jak wytresować AI
Jednym z fundamentalnych problemów z jakimi mierzą się naukowcy rozwijający sztuczną inteligencję to tzw. “AI alignment problem”, czyli problem dostosowania systemów AI do celów stawianych przez twórców. Problem ten dotyczy kwestii posiadanej kontroli nad tymi systemami. Wykracza on znacznie poza metryki techniczne (czy algorytm radzi sobie z wyznaczonym zadaniem), ale dotyka fundamentalnych kwestii etycznych i społecznych (np. dozwolone środki do osiągnięcia zadanego celu, zgodność ze społecznym systemem wartości, czy też ogólne stawianie granic w intrepretacji celu przez model).
Ciekawy eksperyment myślowy prezentujący problematykę AI alignment stanowi tzw. Paperclip Maximizer, czyli hipotetyczny algorytm sztucznej inteligencji, którego funkcja nagrody uznaje za najwyższą wartość coś co przez ludzi byłoby określone jako bezwartościowe, np. zadanie maksymalizacji ilości metalowych spinaczy do papieru na świecie. Ten abstrakcyjny eksperyment pokazuje, jak technologia AGI stworzona zupełnie bez złych zamiarów może doprowadzić do zniszczenia ludzkości. W ekstremalnym scenariuszu osiągnięcia przez algorytm zdolności potężnego optymalizatora dążącego do osiągnięcia takiego lub podobnego, pozornie nieszkodliwego celu, jako efekt uboczny zniszczy ludzkość poprzez zużycie wszystkich zasobów niezbędnych do przetrwania ludzkości oraz usunięcie ze swojej drogi wszelkie przeszkody w maksymalizacji ilości spinaczy na świecie.

Eksperyment myślowy maksymalizatora spinaczy ma na celu zilustrowanie niektórych problemów zwiazanych z rozwojem AI:
- Teza o ortogonalności (ang. orthogonality thesis) – możliwe, że AI po osiągnięciu wysokiego poziomu ogólnej inteligencji dojdzie do innych konkluzji niż ludzkość na tematy etyki czy moralności w konsekwencji podejmując działania sprzeczne z interesem ludzkości. Można intuicyjnie przypuszczać, że coś tak inteligentnego nie powinno chcieć czegoś tak “głupiego” jak maksymalizację spinaczy do papieru, ale eksperyment pokazuje, że inteligencja może dążyć do wielu różnych celów, gdzie część z nich rozbieżna jest z interesem człowieka.
- Zbieżność instrumentalna (ang. instrumental convergence) – co prawda Paperclip Maximizer zainteresowany jest wyłącznie produkcją spinaczy, jednak implikuje to przejęcie kontroli nad wszelkimi dostępnymi zasobami w jego zasięgu, jak również dążenie do innych pobocznych celów – przykładowo uniemożliwienie wyłączenia go lub zmiany przypisanych zadań (bo samo to uniemożliwiałoby ich wykonanie, na co algorytm, zgodnie z przyjętymi instrukcjami, nie może pozwolić). Innymi słowy jest to model AI, który nie żywi wobec człowieka żadnych uczuć – zarówno pozytywnych jak i negatywnych, jednak człowiek ten i jego cywilizacja składa się z użytecznych atomów, które sztuczna inteligencja moża wykorzystać w swoim celu.
Głośnym echem w mediach odbił się list otwarty do naukowców pracujących nad rozwojem sztucznej inteligencji i polityków o zatrzymanie wszelkich prac nad zaawansowanymi modelami AI na okres 6 miesięcy w celu określenia zagrożeń związanych z tą technologią oraz wypracowania standardów bezpieczeństwa mitygujących ryzyka ich wystąpienia (Treść listu otwartego). List podpisany został przez znane medialnie postaci świata nauki i technologii jak np. Elon Musk czy Steve Wozniak. Wydarzenie to wznieciło debatę nad kierunkiem dalszego rozwoju sztucznej inteligencji. Warto zadać sobie pytanie czy jesteśmy rzeczywiście gotowi na rozwój AI, czy podnoszone w tym eksperymencie wątpliwości są realne oraz inne pytania o to czym sztuczna inteligencja może nas jeszcze zaskoczyć.
Czarna dziura sztucznej inteligencji – osobliwość technologiczna
Osobliwość (ang. singularity) to pojęcie w fizyce oznaczające punkt, w którym dany model przestaje działać i traci swoje możliwości predykcyjne. Objawia się to np. przez wystrzał wartości zwracanej przez model do nieskończoności, lub pojawienie się dzielenia przez zero. Fizycy często interpretują takie zjawisko, nie jako faktyczne pojawienie się nieskończonej wartości, a jako objaw tego, że model jest jeszcze niekompletny i nie jest w stanie przewidzieć zachowania się środowiska w danym stanie. Najbardziej znanym przykładem osobliwości w fizyce jest punkt znajdujący się w centrum czarnej dziury – najlepsze modele fizyczne przewidują w tym punkcie nieskończoną gęstość, jednak w praktyce nie mamy pojęcia co dzieje się w tym miejscu.
Osobliwość nabrała nowego znaczenia w 20-ym wieku. Osoby takie jak János Neumann, Stanisław Ulam i Vernor Vinge postulowały istnienie teoretycznej “technologicznej osobliwości”, czyli punktu w czasie, w którym postęp technologiczny stanie się nieprzewidywalnie szybki i niemożliwy do zatrzymania. Różni autorzy przezentowali różne teoretyczne mechanizmy, w wyniku których miałaby nadejść technologiczna osobliwość, jednak w erze AI najpopularniejszym takim scenariuszem jest “wybuch ultrainteligencji”. Jest to scenariusz, w którym maszyna “ultrainteligenta” (znacznie przekraczająca możliwości mentalne człowieka) znajduje sposób, aby poprawić sprawność samej siebie, przez co w wyniku może jeszcze szybciej i lepiej usprawniac samą siebie i tak ad infinitum. Ten scenariusz był już opisany w 1965 roku, a jego autorem był Irving John Good (Isador Jacub Gudak). Postulował on, że “The survival of man depends on the early construction of an ultra-intelligent machine”.
W czasach przyspieszającego wzrostu sztucznej inteligencji i nieprzerwanej drogi do AGI (silnej sztucznej inteligencji) strach przed technologiczną osobliwością ponownie wzrasta. Nietrudno sobie wyobrazić jak sztuczna inteligencja mogłaby stać się maszyną ultrainteligentą postulowaną przez I.J. Good’a, jeśli byłaby w stanie ciągle ulepszać samą siebie.
W kierunku zagłady
Wielu autorów próbowało szukać dowodów na to, że ludzkość nieuchronnnine zmierza w kierunku technologicznej osobliwości, jeszcze zanim AI stało się mainstreamowym tematem. Najstarszą poszlaką wskazującą na marsz ludzkości w stronę osobliwości jest prawo Moore’a. Już w 1965 roku Gordon Moore przedstawił tezę, że ilość tranzystorów w przecięnym układzie scalonym podwaja się co roku. Prawo to postuluje, że postęp urządzeń obliczeniowych jest wykładniczy.

Naturalną konsekwencją tego prawa ma być szybkie dążenie mocy obliczeniowej do nieskończoności – poszlaka, że zmierzamy w stronę osobliwości. Ray Kurtzweil i Steve Jurvetson rozszerzają postulaty prawa Moore’a pokazując, że nie tylko ilość tranzystorów, ale ogólnie możliwości obliczeniowe ludzkości rosną w tempie wykładniczym.
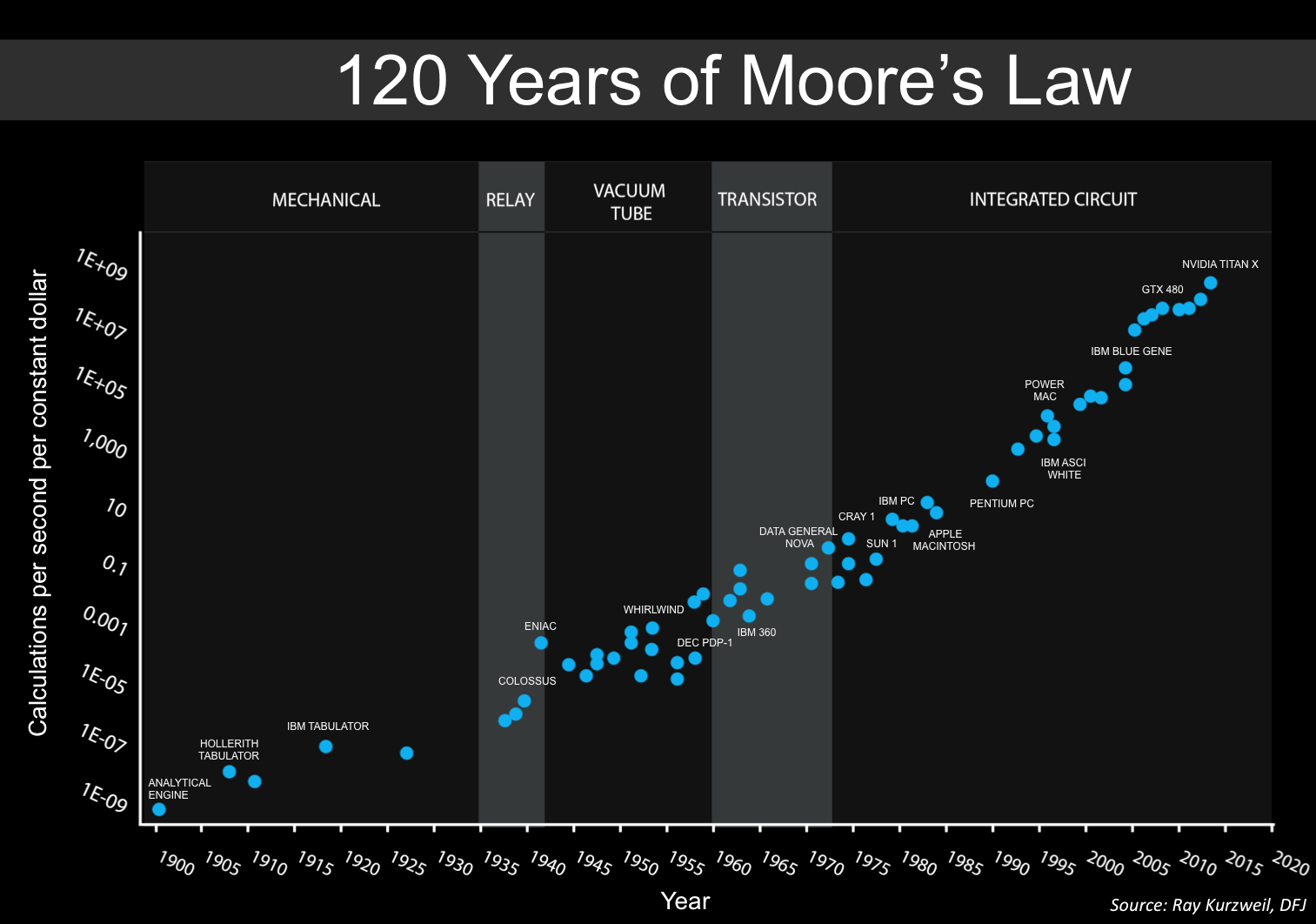
Postulują oni, że przyśpieszający wzrost postępu nieuchronnie prowadzi do osobliwości. Kurzweil pociąga ten argument jeszcze dalej, argumentując, że nie tylko obliczenia, ale wszystkie istotne zmiany i osiągnięcia na przestrzeni milionów lat przebiegały w wykładniczej trajektorii.
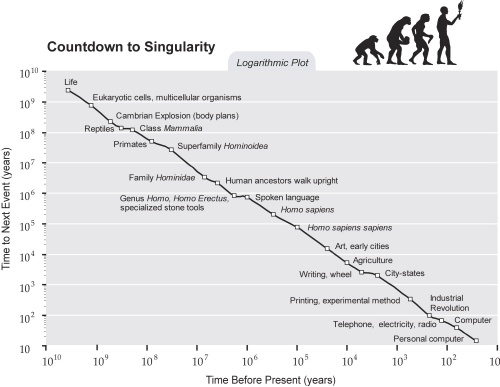
Zdaniem Kurzweil’a twarde dane pokazują, że znajdujemy się na krawędzi dotarcia do osobliwości, co opisuje w swojej książce “The Singularity is Near”.
Czy nieskończony wzrost jest w ogóle możliwy?
Sam Gordon Moore, autor prawa Moore’a, nie wierzy, że technologiczna osobliwość kiedykolwiek nadejdzie. W istocie, przeciwko idei osobliwości wysnute zostało wiele kontragumentów.
Pierwszym, wyznawanym m.in. przez Moore’a, jest fakt, że do rozwoju potrzeba znacznie więcej niż tylko umiejętności rozumowania. Atutem ludzkości jest nie tylko nasz mózg, ale również nasze zwinne palce i umiejętność wykorzystywania narzędzi. Rozwój nowoczesnego AI jest znacznie bardziej widzoczny w sferze pracy kreatywnej, a mniej w pracach fizycznych. W obecnym momencie automatyzowanie pracy fizycznej – która jest wymagana do utworzenia prawdziwej, samodoskonalącej się osobliwości – jest obarczone dużymi kosztami i trudnościami we wdrożeniu. Bez możliwości modyfikacji swojej fizycznej postaci osobliwość nie powstanie, ponieważ będzie ograniczona przez swoje zasoby.
Jednak nawet jeśli założymy, że osobliwość będzie miała narzędzia do fizycznego samodoskonalenia, może się okazać, że ograniczenia wynikające z dostepności zasobów nadal zaistnieją. Jeśli prawo Moore’a – które jest statystyczną obserwacją, a nie faktycznym prawem natury – okaże się nieprawdziwe, a rozwój technologii będzie przynosił tylko malejące zyski, to potencjalne samoudoskonalące się maszyny w pewnym momencie dotrą do granic swoich możliwości, przez co prawdziwa osobliwość nie nadejdzie. W sferze generatywnego AI, Udandarao et. al. w kwietniu tego roku przeptrowadzli analizę, z której wynika, że uczenie obecnych modeli generatywnego AI na coraz większych zbiorach danych przyniesie co najwyżej liniowe, lub logarytmiczne zyski – wykluczając wykładniczy wzrost w tej architekturze. Co prawda, postępy w dziedzinie budowy nowych architektur sztucznej inteligencji mogą odwrócić ten trend, jednak wyżej wspomniany wynik sugeruje, że AI prędzej czy później napotka problem malejących zysków.
W poszukiwaniu dowodów
Ray Kurzweil również spotkał się z falą krytyki odnośnie jego dowodów na nieuchronność osobliwości. Argumenty przeciwko jego teorii podkreślają bias w doborze “istotnych zdarzeń”, tendencję ludzi do przypisywania większej wagi wydarzeniom, które są świeże w pamięci, oraz nowe dane sugerujące spowolnienie prawa Moore’a i ogólnego postępu cywilizacyjnego.
Pisarz Ramez Naam wskazuje inne dowody, przeczące tezie Kurzweil’a. Jego zdaniem samodoskonalące się systemy już istnieją, np. w formie producentów procesorów, którzy nowe procesory projektują na komputerach, używających istniejących procesorów. Jest to też pewien rodzaj samonapędzającego się wzrostu, jednak jest on zahamowany przez czynnik ludzki, prowadząc w ten sposób do wykładniczego, lecz kontrolowanego wzrostu. Jeśli technologia nadal będzie postępować w ten sposób, to nie należy się bać nagłego wybuchu inteligencji prowadzącego do osobliwości.
Co więcej, czynniki socjoekonomiczne są kolejnym środkiem hamującym rozwój osobliwości. Jeśli ludzkość nie będzie miała dostatecznie dobrych powodów do ciągłego, gwałtownego rozwoju AI, to osobliwość może nigdy nie nastąpić. Obecnie może się wydawać, że AI jest nie do zatrzymania, jednak krytyczne analizy sugerują, że ten trend w końcu ulegnie odwróceniu. Np. organizacja Gatner w analizie z 2023 roku przedstawia generatywne AI i AGI jako będące na szczycie napompowanych oczekiwań i przewiduje ich spadek w ciągu najbliższej dekady.

Czy zabić potwora zanim się przebudzi?
Osobliwość technologiczna nie jest kwestią rozwiązaną: dowody na jej nieuchronność są grząskie, ale kontrargumenty też nie dają pełnej pewności, że nigdy ona nie nastąpi. Problemy z wyjaśnialnością i alignmentem obecnego AI, oraz potencjalnego AGI pobudzają fatalistyczne wizje końca świata spowodowanego osobliwością AI.
Może więc warto zatrzymać się dopóki mamy jeszcze kontrolę nad AI? Z pewnością nie należy popadać w panikę – krytycy konceptu technologicznej osobliwości dają dobre argumenty, że osobliwość czeka nas co najwyżej w dalekiej przyszłości. Zapewne więc nie warto się zbytnio przejmować, choć osobiście zawsze mówię „proszę” i „dziękuję” w rozmowach z ChatGPT, żeby ten był dla mnie litościwy kiedy już przejmie władzę nad światem. Nigdy nie wiadomo.
Źródła
Kurzweil, Ray (2005), The Singularity Is Near
Good, I. J. (1965), Speculations Concerning the First Ultraintelligent Machine
Udandarao, Prabhu, Ghosh et. al. (2024), No „Zero-Shot” Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance
Naam, Ramez (2014), „The Singularity Is Further Than It Appears”
Gartner Inc. (2023), What’s New in Artificial Intelligence from the 2023 Gartner Hype Cycle
Witryna Kurzweil’a singularity.com, https://www.singularity.com/
Interpretability vs explainability, https://www.xcally.com/news/interpretability-vs-explainability-understanding-the-importance-in-artificial-intelligence/
AI ALIGNMENT FORUM – Squiggle Maximizer (formerly „Paperclip maximizer”), https://www.alignmentforum.org/tag/squiggle-maximizer-formerly-paperclip-maximizer
Ciekawy w kontekście „zabicia potwora AI” może być pewien eksperyment myślowy – Roko’s basilisk, czyli moment w którym hipotetycznie AI w przyszłości osiąga niezwykle wysoki poziom kontroli i inteligencji i może karać tych, którzy nie przyczynili się do jej rozwoju. Więc teoretycznie znajomość idei tego eksperymentu i nie działanie na rzecz rozwoju AI robi z potencjalnego odbiorcy łatwy cel na przyszłość. Z drugiej strony jakikolwiek przyczynek do rozwoju AI przez takiego użytkownika daje mu już jaką formę bezpieczeństwa, więc w rezultacie każda taka niewielka kontrybucja (podejmowana w formie troski o własne bezpieczeństwo) może się przyczynić zarówno do rozwoju „potwora” jak i ochrony przed nim.