Poczynając od analizy artykułów naukowych, poprzez klasyfikację danych doświadczalnych, aż do wyciągania z tych danych wzorców stanowiących podstawę nowych odkryć naukowych – sztuczna inteligencja zaczyna być obecna na każdym etapie pracy naukowej. Nowe generacje wyszukiwarek naukowych opartych na modelach językowych takich jak GPT-3 pozwalają na coraz szybszą analizę dużej ilości artykułów, a osiągnięcia w dziedzinie AI być może pozwolą im stać się ‘sztuczną muzą’ inspirującą naukowców do nowych badań. Czy modele sztucznej inteligencji będą jednak w stanie wyjść poza tę rolę i w sposób fundamentalny przyczynić się do pozyskania nowego zrozumienia naukowego?
Wyszukiwarki bibliograficzne i naukowe
Google Scholar
Zbieranie materiałów i informacji jest najczęściej jednym z pierwszych kroków podczas analizy problemu badawczego. Zadanie to znacząco ułatwiły, a wręcz zrewolucjonizowały wyszukiwarki bibliograficzne i naukowe, takie jak uruchomiona w 2004 roku Google Scholar.
Google Scholar działa na zasadzie wyszukiwarki, umożliwiając użytkownikom przeszukiwanie internetu w poszukiwaniu publikacji naukowych, takich jak artykuły, książki, prace doktorskie, konferencje naukowe, raporty itp. Serwis zawiera linki do tych publikacji, które są darmowe lub są dostępne po opłaceniu subskrypcji, lub opłacie jednorazowej.

Wyszukiwarka oferuje wiele funkcji, w tym narzędzia do filtrowania wyników, sortowania według daty publikacji lub liczby cytowań, a także możliwość śledzenia cytatów dla określonych publikacji. Google Scholar umożliwia również tworzenie profilu naukowego, gdzie autorzy mogą prezentować swoje publikacje i śledzić cytowania swoich prac.
Rekordy zwracane przez Google Scholar są pozyskiwane za pomocą tzw. robotów indeksujących (web crawlers), przeszukujących m.in. bazy danych uniwersytetów i instytucji naukowych. Następie rekordy są pozycjonowane zgodnie z algorytmem biorącym pod uwagę m.in. liczbę cytowań, reputację autora pracy, miejsce i datę publikacji pracy oraz jej język.
Ponieważ Google Scholar wyżej pozycjonuje prace z dużą liczbą cytowań (Beel & Gipp, 2009), trudniej będzie za jej pomocą znaleźć ‘nieodkryte diamenty’ bądź prace idące ‘pod prąd’ w danym temacie. Może również wzmacniać tzw. efekt św. Mateusza – najwyżej pozycjonowane prace, a więc te z największą ilością cytowań, będą jeszcze częściej czytane i cytowane, i stale umacniane na pozycji lidera.
Dodatkowo algorytm nie uwzględnia synonimów, co z jednej strony wymusza odpowiedni dobór słów kluczowych przez wyszukującego, jak i wymaga od autora pracy zawarcia możliwie jak największej liczby synonimów w tekście swojej pracy, celem większej szansy uwzględnienia jej przez Google Scholar.
Wyszukiwarki wykorzystujące AI – Elicit
Innym typem narzędzia do poszukiwania publikacji są narzędzia wspomagane sztuczną inteligencją, takie jak Elicit, Iris czy Semantic Scholar. Poza dopasowywaniem słów kluczowych z zadanego pytania, wyszukiwarki AI analizują wyszukiwane artykuły, zwiększając jakość wyników.
Elicit to asystent badawczy wykorzystujący modele językowe takie jak GPT-3 do automatyzacji części prac badawczych (WEB1). Obecnie, jego głównym narzędziem jest przegląd literatury. Jeśli zadamy pytanie, Elicit wyświetli odpowiednie artykuły i podsumowania kluczowych informacji na temat tych artykułów w łatwej do użytku tabeli. Do niedawna był narzędziem płatnym, ale obecnie jest darmowe, publicznie dostępne.
Elicit jest w stanie znajdować odpowiednie artykuły nawet jeśli nie odpowiadają one słowom kluczowym. Używa w tym celu podobieństwa semantycznego, więc przykładowo, przy zastosowaniu słowa kluczowego meditation może również zwrócić artykuły związane z terminem mindfulness. Dzięki regulacji tego, jak ‘podobne’ słowa kluczowe mają być wyszukiwane oraz filtrom słów kluczowych i dziedzin, użytkownik ma wpływ na to jak szeroką bazę artykułów uzyska.
Dla każdego wyniku wyszukiwania Elicit przetwarza abstrakt i generuje spersonalizowane podsumowanie, które jest odpowiednie do naszego pytania. Takie podsumowanie może pomóc użytkownikowi we wstępnym zrozumieniu badań oraz upraszcza złożone abstrakty.
Jeśli użytkownik oznaczy artykuł ‘gwiazdką’, czyli w zamyśle uzna go za pomocny, Elicit dokona przeszukania grafu cytowań tego artykułu w celu znalezienia podobnych prac oraz aktualizacji wyników wyszukiwania. Co znamienne, przeszukiwane będą zarówno prace cytowane w ‘gwiazdkowym’ artykule, jak i te cytujące ten artykuł.
Dokładne działanie Elicit przedstawione jest na grafie poniżej:
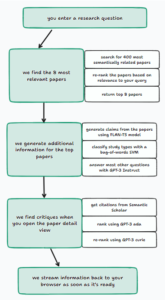
Należy zwrócić uwagę na zastosowanie sztucznej inteligencji, nieobecnej w przypadku Google Scholar: modeli językowych FLAN-T5 i GPT-3, oraz Support Vector Machine (SVM). Dodatkowo korzysta z innego narzędzia do wyszukiwania literatury naukowej – Semantic Scholar, również korzystającego z narzędzi do przetwarzania języka naturalnego.
Elicit posiada obecnie pewne ograniczenia, przykładowo przetwarza tylko prace w języku angielskim, co utrudnia pracę badawczą z zastosowaniem tekstów w innych językach.
Dodatkowo, modele językowe, z których korzysta Elicit są stosunkowo nowe (powstały po 2019 roku), i choć nie można odmówić im użyteczności, to nadal powinny być traktowane jako technologia na wczesnym etapie rozwoju. Przykładowo GPT-3, używany w Elicit, mimo bycia jednym z najlepszych dostępnych modeli, może mieć trudności z przetwarzaniem niezwykle rzadkich lub specjalistycznych terminów, lub zrozumieniem ironii i sarkazmu w tekście.
Elicit nie ma możliwości sprawdzenia, czy dana praca jest wiarygodna – dla każdej pracy zostanie zwrócony pewien zestaw metryk, takich jak liczba cytowań czy to gdzie artykuł został opublikowany, ale stwierdzenie tego, czy zawartym w niej wynikom badań można ufać, pozostaje w gestii użytkownika. Jak każde narzędzie komputerowe, Elicit nie jest idealne i może zawierać błędy lub nieprawidłowe wyniki, dlatego każdy rezultat należy sprawdzić samodzielnie.
Porównanie obu narzędzi na przykładzie
Jak sprawują się wspomniane narzędzia, gdy mamy do rozwiązania konkretny problem? Załóżmy, że chcemy się wyszukać materiałów na temat symulacji śniegu. Wyszukujemy frazę Snow simulation method.
Patrząc na pierwsze wyniki z Google Scholar:
- A material point method for snow simulation – dobry wynik w temacie
- Lidar snowfall simulation for robust 3d object detection – wykrywanie obiektów w zaśnieżonych warunkach. Spełnia słowa kluczowe, jednak nie o to chodziło.
- Real-time particle-based snow simulation on the GPU – dobry wynik w temacie.
- A methodology for snow data assimilation in a land surface model – przewidywania meteorologiczne.
- How well can simulation predict protein folding kinetics and thermodynamics? – używanie metod stworzonych do symulacji cząsteczkowej do symulacji białek. Nie związane z tematem.
- Parallel Methods for Real-Time Visualization of Snow – dobry wynik
- An objective snow profile comparison method and its application to SNOWPACK – metoda porównywania wyników. Też nie jest tym, o co pytaliśmy.
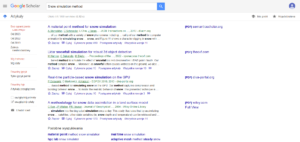
W kolejnych 9 wynikach tylko 5 było na temat, który poszukiwaliśmy. Daje to 50% trafności wyszukiwania. Można zwrócić uwagę, że zapytanie nie było dokładne i wszystkie podane artykuły zawierały słowa kluczowe, ale zobaczmy jak poradzi sobie Elicit
- A material point method for snow simulation – ten sam wynik co w Google Scholar na pierwszym miejscu
- Parallel Methods for Real-Time Visualization of Snow – ten sam wynik co Google Scholar na 6 miejscu.
- Synthesis method for simulating snow distribution utilizing remotely sensed data for the Tibetan Plateau – Symulowanie zaśnierzenia używając ograniczonych danych. Nie do końca właściwy wynik.
- A Simulation System of Snow Based on Particle System – dobry wynik.
- Computer simulation of wind speed, wind pressure and snow accumulation around buildings (SNOW-SIM) – dobry wynik.
- Particle System Based Snow Simulating in Real Time – dobry wynik
- An implicit compressible SPH solver for snow simulation – dobry wynik.
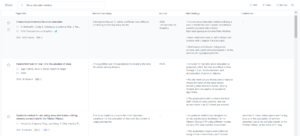
Na 7 kolejnych wyników, 5 było trafnych. Ponadto każdy zwrócony artykuł opatrzony był małym streszczeniem abstraktu, napisanym przez AI, które pozwala w krótkim czasie ocenić przydatność danego wyniku. Opis ten nawiązuje do zadanego wyszukiwania, przedstawia kluczowe punkty, cytowania w innych źródłach i cytuje możliwą krytykę. Google Scholar nie daje takiej możliwości i wymaga przejścia na stronę publikacji.
Elicit pozwala również na wyszukiwanie bardziej szczegółowych informacji w samym artykule, takich jak czasopismo, w którym został on opublikowany czy główne odkrycia dokonane w pracy. Na uwagę zasługuje fakt, że można wyciągnąć dowolną informację o artykule w formie pytania 'What was the …?’, co potencjalnie może pomóc zawęzić liczbę artykułów do głębszej analizy.
Inne narzędzia sztucznej inteligencji w pracy naukowej
Wyszukiwarki naukowe i bibliograficzne są tylko jednym z aspektów, w których sztuczna inteligencja wykorzystywana jest w narzędziach pracy naukowej. Dość powszechne jest stosowanie jej również na kolejnych etapach badań, na przykład podczas analizy i klasyfikacji wyników doświadczalnych.
Czymś nowym jest jednak wykorzystanie AI do postulowania trzeciego, obok znanych obserwacji i symulacji, sposobu poznawania wszeświata – modelowania generatywnego. Istota działania takiego modelu może być przedstawiona następująco (WEB2):
Generative modeling takes sets of data (typically images, but not always) and breaks each of them down into a set of basic, abstract building blocks — scientists refer to this as the data’s “latent space.” The algorithm manipulates elements of the latent space to see how this affects the original data, and this helps uncover physical processes that are at work in the system.
Astrofizyk Kevin Schawinski użył modelu generatywnego w eksperymencie mającym sprawdzić zmiany zachodzące podczas ewolucji galaktyk na poziomie fizycznym. Istota tego eksperymentu brzmiała:
Let’s erase everything we know about astrophysics. To what degree could we rediscover that knowledge, just using the data itself?
Model wykrył pewne procesy zachodzące podczas ewolucji galaktyk, ale nie był w stanie odpowiedzieć na pytanie, jakie zjawiska fizyczne je spowodowały – do tego nadal potrzebny był człowiek. Model generatywny stanowi w pewnym sensie odwrotność symulacji – nie mamy już ‘przepisu’ na to, jak zachowują się elementy środowiska, ale zamiast tego chcemy się dowiedzieć, co się dzieje w danym systemie wyciągając informacje tylko z danych.
Narzędzia wykorzystujące sztuczną inteligencję można również traktować jak ciężko pracujących ‘asystentów’ (WEB2). Są w stanie przeanalizować o wiele większy zbiór danych, niż ich ludzkie odpowiedniki, zostawiając “ciekawszą” naukę prawdziwym naukowcom. Przykładem wykorzystania takiego ‘asystenta’ może być losowe testowanie łączenia różnych związków chemicznych przez robota, eksperyment przeprowadzony przez Lee Cronin’a. Dzięki dostępowi do systemu monitoringu robot uczył się, które związki najmocniej ze sobą reagują, tworząc coraz lepsze kombinacje. Mimo że eksperyment nie doprowadził do nowych odkryć, Cronin postulował, że podobne rozwiązania zwiększą szybkość pracy naukowców-chemików nawet o 90%.
Innym podobnym testem była przeprowadzona w Zurichu próba wywnioskowania praw fizyki z samych danych przez robota AI. Maszyna z powodzeniem odkryła na nowo heliocentryczny układ słoneczny, tory ruchu innych planet oraz zasady zachowania energii.
W pracy On scientific understanding with artificial intelligence wymienione zostały trzy wymiary, w jakich sztuczna inteligencja może służyć naukowcom (Krenn et al., 2022).
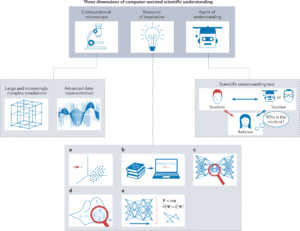
Pierwszy typ narzędzia, nazwany mikroskopem obliczeniowym, umożliwiałby badanie obiektów i procesów, których nie da się zwizualizować ani próbkować w inny sposób, na przykład ze względu na skalę czasową, w jakiej należałoby przeprowadzić eksperyment. Takie komputerowo generowane dane mogłyby być generalizowane w innym kontekście, prowadząc do nowych wyników. Symulacje oparte na takich założeniach doprowadziły już do odkryć w zakresie chemii i biologii molekularnej.
Sztuczna inteligencja może się również okazać źródłem inspiracji dla naukowców, na przykład poprzez wykrywanie wzorców w danych eksperymentalnych. W tej dziedzinie zastosowanie mogą znaleźć również wspomniane wcześniej modele językowe, które poprzez analizę artykułów mogą wyabstrahowywać nowe kierunki badań. Może to stanowić w przyszłości ciekawe rozszerzenie działania wyszukiwarek naukowych.
Najbardziej zaawansowanym narzędziem, obecnie istniejącym tylko w sferze spekulacji, miałby być agent zrozumienia (agent of understanding), czyli obiekt potrafiący w sposób autonomiczny pozyskiwać zrozumienie naukowe nieznane dotąd człowiekowi, oraz mu je przekazywać.
Jak sztuczna inteligencja zmienia naukę?
Wpływ wyszukiwarek naukowych
Obecny bezprecedensowy w historii ludzkości szeroki dostęp do szkolnictwa wyższego, a co za tym idzie rosnąca liczba publikacji naukowych czyni próbę samodzielnego przeglądu publikacji na dany temat zadaniem praktycznie niemożliwym. Nieocenioną pomoc okazują tutaj wcześniej wymienione wyszukiwarki naukowe, takie jak Google Scholar czy Elicit, pozostawiając jednak zauważalny wpływ na sposób pisania prac naukowych oraz ich cytowalność.
Jednym ze źródeł tego wpływu są algorytmy pozycjonujące wyniki wyszukiwaniu, co jak wcześniej wspomniano w przypadku Google Scholar, może powodować marginalizację prac spoza ‘głównego nurtu’ w danej dziedzinie i prowadzić do bardzo dużego wzrostu cytowań dla wysoko pozycjonowanych prac. Ponieważ algorytmy takie opierają się najczęściej na liczbie cytowań, można spotkać się z negatywnym zjawiskiem samocytowania (Beel & Gipp, 2009).
Udowodniono, że Google Scholar nie jest odporny na pewien rodzaj spoofingu – ocena prac zwracanych w rezultatach jest powierzchowna, mogą się tam dostać prace napisane przez boty albo nieistniejących autorów (Ike Antkare był w pewnym momencie swojego (nie)istnienia dwudziestym pierwszym najwyżej cytowanym naukowcem Google Scholar, wyprzedzając nawet Einsteina) (WEB3).
Innym problemem jest brak uwzględniania kolejności autorów prac. W dobie istnienia ogromnych zespołów badawczych, kiedy nowe odkrycia rzadko są dokonywane przez jednostki, a prace naukowe mogą mieć nawet ponad 5 tys autorów, takie rozwiązanie może się okazać problematyczne.
Brakuje również rozróżnienia rodzaju cytowań – taką samą wagę będzie mieć cytowanie typu ‘autor tego artykułu całkowicie się pomylił’ i ‘całą moją pracę opieram na tym, co zrobił ten autor’. Tutaj pomocne może w przyszłości okazać się wykorzystanie sztucznej inteligencji, która mogłaby na podstawie tekstu wyciągać kontekst cytatu.
Dodatkowy problem stanowi faworyzowanie prac pisanych w języku angielskim. W przypadku wyszukiwania prac w kilku językach, Google Scholar podczas zwracania wyników na wyższych miejscach plasuje prace napisane w języku angielskim (Rovira et al., 2021). Inne rozważane narzędzie, Elicit, umożliwia tylko i wyłącznie wyszukiwanie prac w języku angielskim, przy czym pojawiają się sugestie, że znacznie niżej pozycjonowane są prace autorów, dla których angielski nie jest ich pierwszym językiem. Może to prowadzić do pomijania prac naukowych pisanych w innych językach, niezależnie od ich wartości naukowej.
Czy roboty zastąpią naukowców?
Używanie sztucznej inteligencji staje się nieodłączną częścią pracy naukowca również na innych etapach badawczych, przykładowo podczas analizy ogromnej ilości danych doświadczalnych. Dyskusyjna pozostaje jednak kwestia tego, czy sztuczna inteligencja będzie w stanie przyczynić się na poziomie fundamentalnym do pozyskania nowego zrozumienia naukowego.
Wspomniany wcześniej model generatywny jest przez niektórych określany jako wyrafinowany sposób do wyciągania wzorców z danych, a nie nowy sposób poznawania wszechświata (WEB2).
Metody sztucznej inteligencji takie jak sieci neuronowe są czasami krytykowane za brak transparencji – uzyskujemy odpowiedź na pytanie bez jasnego wyjaśnienia, skąd ta odpowiedź się bierze. Uznaje się też, że wyniki uzyskiwane za pomocą sieci neuronowych powinny być dostarczane razem z pewnym zakresem błędu.
Często słyszanym argumentem jest również aspekt kreatywności, której na razie nie potrafimy zaprogramować. Astroinformatyk Kai Polsterer stwierdził, że:
Coming up with a theory, with reasoning, I think demands creativity. To be creative, you have to dislike being bored. And I don’t think a computer will ever feel bored.
Potencjalnie, naukowców mógłby zastąpić wspomniany wcześniej agent zrozumienia, z tym że jego istnienie wymagałoby modelu uczenia maszynowego będącego w stanie przekazać nową wiedzę człowiekowi, na przykład za pomocą dyskusji prowadzonej w języku naturalnym za pośrednictwem GPT-3. Taki obiekt pozostaje obecnie jedynie w sferze teoretycznej.
Podsumowanie
Nie ulega wątpliwości, że stosowanie sztucznej inteligencji w pracy naukowej, czy to na etapie wstępnej analizy dziedziny problemu, czy podczas klasyfikacji i opracowywania danych doświadczalnych staje się niezbędne ze względu na rosnącą ilość informacji, niemożliwej do przetworzenia przez człowieka. Ważna jest jednak świadomość ograniczeń tych narzędzi, a co za tym idzie odpowiednia weryfikacja uzyskanych za ich pomocą wyników.
Literatura
Strona główna projektu Elicit: https://elicit.org/
Beel, J., & Gipp, B. (2009, July). Google Scholar’s ranking algorithm: an introductory overview. In Proceedings of the 12th international conference on scientometrics and informetrics (ISSI’09) (Vol. 1, pp. 230-241).
Falk, D., & Magazine, Q. (2019). How Artificial Intelligence is Changing Science. Quanta Magazine, 11.
Coiffait, L. (2019). Criticisms of the Citation System, and Google Scholar in Particular. Social Science Space (blog).
Rovira, C., Codina, L., & Lopezosa, C. (2021). Language bias in the Google Scholar ranking algorithm. Future Internet, 13(2), 31.
Krenn, M., Pollice, R., Guo, S. Y., Aldeghi, M., Cervera-Lierta, A., Friederich, P., … & Aspuru-Guzik, A. (2022). On scientific understanding with artificial intelligence. Nature Reviews Physics, 4(12), 761-769.

[…] poprzednim artykule skupiliśmy się na seks robotach w ogólności, a także na najpopularniejszej formie tego […]