Ścisła integracja technologii z naszym życiem codziennym bardzo szybko przestała być odległą przyszłością. Zagadnienia systemów sztucznej inteligencji, VR i AR czy widzenia komputerowego trafiły już pod przysłowiową strzechę. Liczne możliwości rozwoju i zastosowań nowych technologii są już oczywistością. W debacie publicznej co rusz pojawiają się również tematy zagrożeń takich jak zmiany na rynku pracy wynikające z większych możliwości automatyzacji prostych zadań. Jednak aspektem, który może nie zawsze być tak oczywisty są problemy związane z prywatnością danych jakie bez wątpienia łączą się z tymi technologiami i ich rozwojem. Przyzwyczailiśmy się już do wszechobecnych smartfonów, smart zegarków, urządzeń IoT i smart home – być może jeszcze kolejna technologia już nie wzbudza w nas nieufności.
Nowa rzeczywistość i nowe widzenie
Technologie AR (ang. Augmented Reality) to techniki, które mieszają ze sobą treści wygenerowane komputerowo jak wideo czy modele 3D, ze środowiskiem świata rzeczywistego w czasie rzeczywistym. Interakcja odbywa się najczęściej poprzez medium takie jak smartfon, tablet, okulary AR (AR headset).
Widzenie komputerowe, zaliczane do dziedziny sztucznej inteligencji. Skupia się ona na umożliwieniu komputerom analizowania, rozumienia oraz interpretowania treści wizualnych ze świata rzeczywistego. Polega na tworzeniu algorytmów, które wydobędą wartościowe informacje z obrazów i wideo. Widzenie komputerowe jest używane nie tylko w kontekście AR, jednak każdy sprzęt AR stosuje widzenie komputerowe, aby rozumieć co widzi użytkownik w danej chwili.
Kamera przylepiona do twarzy
Rozszerzona rzeczywistość po raz pierwszy wkroczyła do świadomości publicznej w 2012 roku, kiedy Google ogłosił Google Glass. Glass to sprzęt wyglądem nie odbiegający od zwykłej pary okularów, który jest wyposażony w kamerę i możliwość wyświetlania obrazów na szkle. Jest to wczesny przykład próby komercyjnego wykorzystania rozszerzonej rzeczywistości. Reakcja publiki na ten produkt była natychmiastowo negatywna, a główny zarzut wobec produktu był następujący – co z prywatnością?

Materiał promujący Google Glass, wydany przez Google
Absolutnie każdy produkt AR – czy to pełen headset VR z funkcjonalnością rozszerzonej rzeczywistości, czy zwykły smartfon na którym działa „Pokémon GO” – ostatecznie sprowadza się do tego, że jego użytkownik przechadza się po świecie z kamerą nagrywającą jego otoczenie. Dopóki to otoczenie sprowadza się do własnego pokoju nikogo ten fakt nie razi, jednak wychodząc w miejsca publiczne użytkownicy AR zaczynają mimowolnie nagrywać przechodniów, prywatne domy, tabliczki rejestracyjne itd.
Problemy z prywatnością od początku były częścią konwersacji o rozszerzonej rzeczywistości. Art 81 Pr. Aut wymaga zgody nagrywanej osoby na rozpowszechnianie jej wizerunku, chyba że ta „stanowi jedynie szczegół całości takiej jak zgromadzenie, krajobraz, publiczna impreza”. Prawo polskie nie wyjaśnia, czy osoby nagrywane przez przechadzającego się po mieście użytkonika sprzętu AR są jedynie częścią krajobrazu i czy wolno nam rozpowszechniać ich wizerunek. Z drugiej strony, sprzęt AR nie musi rozpowszechniać żadnych wizerunków, wystarczy że jedynie nagrywa – ale czy osoba nagrywana może mieć pewność, że jej twarz lub dane z przetworzonego wideo nie lądują na serwerze jakiegoś giganta technologicznego? Czy nawet sam użytkownik sprzętu AR może mieć pewność, że ten sprzęt nie kolekcjonuje danych o nim samym?
Ile wiedzą o nas cyfrowe okulary?
Ilość i zaawansowanie sensorów w urządzeniach AR rośnie w imponującym tempie. Już w produkcie firmy Microsoft – wydanym w 2019 HoloLens 2, znaleźć można było sensory światła widzialnego, kamery na podczerwień, sensor odległości, czujnik inercyjny (m.in. mierzący położenie, przyspieszenie, prędkość kontową i inne) oraz kamerę wideo. Poza tym miał on możliwość zbierania danych biometrycznych takich jak ruch oczu czy dane na temat poruszania się ciała użytkownika.
Zakładać należy, że dzisiaj możliwości takich urządzeń są jeszcze większe, a ilość sensorów tylko urosła. Na stronie Apple, w materiałach reklamujących najnowszy produk tej firmy Apple Vison Pro czytamy, że poza dwiema głównymi kamerami o wysokiej rozdzielczości urządzenie wyposażone jest jeszcze w sześć kamer zwróconych w stronę świata zewnętrznego i cztery kamery do śledzenia oczu użytkownika. Poza tym inne kamery do pomiaru odległości, również sensor laserowy LiDAR, cztery czujniki inercyjne oraz sensory naświetlenia.

Wiemy również, że innowacyjność Apple VisionPro nie ograniczają się wyłącznie do sensorów czy też ich ilości. Jednym z mocno akcentowanych marketingowo punktów jest użycie w nim aż dwóch czipów – M2, który odpowiedzialny jest za przetwarzanie danych i obsługiwanie wielozadaniowości oraz nowy czip R1 stworzony specjalnie dla zastosowań rozszerzonej rzeczywistości. To właśnie R1 pozwala na sprawną integrację danych z sensorów ze światem wirtualnym, kontroli ruchu wyświetlanej zawartości na podstawie ruchu gałek ocznych czy inne zmiany kąta wyświetlania obrazu związane z poruszaniem się użytkownika.
Niezaprzeczalny wzrost możliwości obliczeniowy takich urządzeń pozwolił również na niesamowite (ale również przerażające) możliwości modelowania zachowań użytkowników. Jak ujawnił na platformie X (dawniej Twitter) pewien inżynier neurotechnolog, pracujący w Apple, urządzenie potrafi przewidywać nasze zachowania zanim się one wydarzą. Podaje tam przykład zastosowania takiej technologii, gdzie chęć kliknięcia w przycisk jest możliwa do przewidzenia na podstawie obserwacji gałek ocznych, co pozwalać ma na szybsze załadowanie kolejnej strony i wpływa na bardziej płynne wrażenia z korzystania z urządzenia.
Innym ciekawym zastosowaniem jest wnioskowanie na temat aktualnego stanu funkcji kognitywnych użytkownika. Odbywa się to poprzez szybkie mignięcie światłem czy odtworzenie dźwięku tak iż jest to poniżej progu postrzegania, a następnie mierzenie reakcji na takie zjawiska. Wszystkie takie dane analizowane są następnie z użyciem modeli uczenia maszynowego w celu określenia np. tego czy jesteśmy wypoczęci czy też zmęczeni lub jak dobrze uczymy się nowych rzeczy, co z kolei wywołuje adaptację wirtualnego środowiska w celu dostosowania się do naszego aktualnego stanu kognitywnego.

Ten fragment możemy podsumować listą danych, które urządzenia AR zbierają i wykorzystują do spełniania swoich zadań oraz opis jak takie dane mogą zostać wykorzystane gdyby dostały się w niepowołane miejsce:
- dane biometryczne – do tych danych należą wygląd tęczówek i gałek ocznych, odciski palców, geometria dłoni czy próbki głosu,
- dane o ruchu oka – śledzenie ruchu oka, w którym miejscu użytkownik koncentruje uwagę, co może być wykorzystane do poznawania zainteresowań i zachowań,
- ruchy głowy i ciała – może zostać wykorzystane do stworzenia cyfrowej kopii użytkownika (tzw. deepfake),
- dane lokalizacyjne i przestrzenne (otoczenie użytkownika),
- interakcja i dane o zachowaniach – informacja o tym w jaki sposób użytkownik wchodzi w interakcje ze światem wirtualnym, co może pozwolić na stworzenie jego profilu psychologicznego i modelowania zachowań, jak również poznania jego cech osobowości,
- inne dane powiązane z kontem użytkownika (dane osobowe, adres zamieszkania, dane o płatnościach itd.).
Widzimy zatem, że zakres zbieranych danych jest naprawdę szeroki. Również ryzyko związane z wykorzystaniem ich przez niepowołane osoby czy podmioty z pewności stanowi istotny czynnik. Z pewnością nie czulibyśmy się komfortowo i bezpiecznie wiedząc, że ktoś bez naszej zgody mógłby wejść w posiadania tak wrażliwych danych o nas.
Przyjrzyjmy się zatem w jaki sposób takie dane mogą być wykorzystywane oraz jak ocenić można ryzyko przekazania tychże danych w niepowołane ręce.
Do wszelkich zapewnień korporacji o bezpieczeństwie i prywatności naszych danych powinnismy podchodzić z rezerwą. Znane są historie umożliwienia przekazania czy też niewystarczającego zabezpiecenia danych przed przekazaniem niepowołanym podmiotom przez największe firmy. Prawdopodobnie najbardziej medialnie znanym jest przypadek Cambridge Analytica, w którym to Facebook pozwolił na pobranie z platformy danych o milionach swoich użytkowników bez ich zgody.
Innym sposobem naruszania prywatności użytkowników jest rynek reklamowy w serwisach internetowych. W uproszczeniu model ten polega na sprzedawaniu przestrzeni reklamowej na stronie internetowej temu kto najwięcej zapłaci. Przed tym jak transakcja dojdzie do skutku reklamodawcy otrzymują dane profilujące użytkowników, które pozwalają im określić opłacalność pokazania danemu użytkownikowi swojej reklamy. W ten sposób reklamodawcy mogą otrzymać dostęp do niektórych zanonimizowanych informacji o użytkownikach tychże serwisów. Niestety, okazuje się, że dane te mogą być wykorzystywane np. przez instytucje rządowe do szpiegowania użytkowników. W tym artykule: https://www.wired.com/story/how-pentagon-learned-targeted-ads-to-find-targets-and-vladimir-putin/ opisany jest jak organizacje szpiegowskie USA wykorzystywały dokładnie ten mechanizm do poznania lokalizacji osób znajdujących się w kręgu ich zainteresowań – w tym również samego prezydenta Rosji Władimira Putina.
Niestety jest to przypadek, w którym urządzenia wirtualnej i rozszerzonej rzeczywistości dostarczają jeszcze więcej możliwości profilowania. Mnogość danych zbieranych przez sensory AR otwiera pole do spekulacji o jeszcze łatwiejszym dopasowaniu cech do dającej się zidentyfikować osoby.
Jak wykazały eksperymenty (https://arxiv.org/pdf/2209.10849.pdf) takie urządzenia można już wykorzystywać do rozpoznawania wieku czy płci osoby, która ich używa.
Regulacje – ostatnia deska ratunku?

Skoro wiemy już jak niebezpieczne w teorii mogą być konsekwencje zaniedbań ze strony korporacji udostępniających narzędzia AR to czy jest jakiś sposób aby wymóc na nich większą dbałość o prywatność użytkowników? Od czasów Cambridge Analytica wiele się zmieniło i firmy przetwarzające dane użytkowników zmuszane są przez regulacje do przestrzegania prawa do prywatności (np. RODO). Z najnowszych doniesień – w marcu w Parlamencie Europejskim przegłosowany został tzw. AI Act, czyli projekt prawny, które ma regulować stosowanie sztucznej inteligencji w podmiotach działających na terenie Unii Europejskiej. Na szczegółowe wdrożenie zaleceń trzeba będzie jeszcze poczekać, jednak po obecnym kształcie tego dokumentu wiadomo, że systemy AI podzielone zostaną na systemy o różnym stopniu ryzyka. Z przyznanej klasyfikacji wynikać będą pewne obowiązki, nie tylko dotyczące zachowania standardów prowadzenia procesów oceny dokładności, ryzyka czy bezpieczeństwa rozwiązania, ale również konieczność większej transparentności w działaniu. Przykładowo systemy znajdujące się w klasie najwyższego ryzyka (ang. high risk) zobowiązane będą do prowadzenia i utrzymywania dokumentacji systemu podlegającej ocenom zgodności. Pozostaje zatem mieć nadzieję, że rozsądne wdrożenie tej i innych regulacji ustandaryzuje rynek computer vision AR w sposób przyjazny dla użytkowników i dla ich prywatności.
Czego nie widzi widzenie komputerowe
Nie trzeba gogli wypełnionych milionami sensorów, aby wpakować się w społeczne kłopoty. Samo oprogramowanie odpowiadające za widzenie komputerowe może być przedmiotem kontrowersji. Za terminem „computer vision” kryje się szereg algorytmów i sieci neuronowych przetwarzającech dane, tak aby móc rozumieć obrazy. Tego typu algorytmy są trenowane (uczone) na pewnych danych treningowych i rozpoznają elementy obrazu na podstawie tych informacji, które wyekstrapolowały z danych treningowych.
Możliwości tych algorytmów zależą więc w dużej mierze od tego co zawierają dane treningowe – a te, jak się okazują, zawierają dysproporcjonalnie wiele białych mężczyzn. Badania z 2018 roku pokazały, że dostępne wtedy na rynku modele rozpoznawania płci mylą się 8-20% razy więcej w przypadku kobiet niż mężczyzn. Badacze z Harvardu znaleźli podobny trend w przypadku analizowania twarzy ciemnoskórych osób, w porównaniu z osobami o jasnej karnacji.
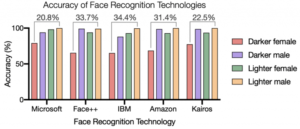
Porównanie celności modeli różnych firm na danych z różnych grup demograficznych
Czy ma to jakiekolwiek przełożenie na rzeczywostość? W 2015 roku Google wpadł w medialne tarapaty po tym, gdy użytkowniczk Google Photos ujawnił, że album ze zdjęciami jego znajomych został automatycznie otagowany jako zawierający „goryle” przez algorytm.
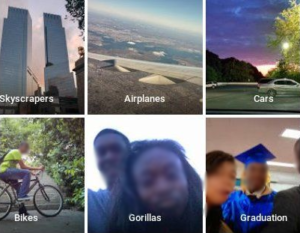
Błąd Google Photos w oznakowaniu folderu zawierającego czarnoskóre osoby
Może w tym przypadku poniesiona szkoda miała jedynie wymiar medialny, jednak od tego czasu widzenie komputerowe wkradło się do wielu innych dziedzin niż tylko tagowanie zdjęć. Co jeśli to nie Google Photos, a na przykład program samosterojącgo samochodu pomyliłby czarnoskórą osobę z gorylem? Skutki na pewno były by poważniejsze. Oczywistym jest, że żadna osoba nie powinna mieć gorszych doświadczeń podczas używania sprzętu AR, lub być bardziej narażona na niebezpieczeństwo ze strony użytkowników widzenia komputerowego jedynie ze względu na jej płeć, czy kolor skóry. Wraz ze wzrostem ilości zastosowań widzenia komputerowego programiści muszą zadbać o to, aby te modele sprawdzały się celnie w każdym kontekście. W praktyce oznacza to np.: stosowanie bardziej różnorodnych zbiorów treningowych. Malejąca ilość medialnych doniesień o podobnych wpadkach sugeruje, że w ostatnich latach faktycznie nastąpił postęp w tej sprawie.
Patrząc w przyszłość (przez okulary AR)
Google Glass, prowodyr sprzętu AR okazał się kompletnym niewypałem. Powodów z pewnością było wiele: wysoka cena, funkcjonalność dostępna w innych, tańszych alternatywach, próba pozycjonowania produktu jako elementu nowoczesnej mody itd. Jednak z pewnością olbrzymią rolę w porażce tego produktu odegrały etyczne i społeczne wątpliwości wokół prywatności i bezpieczeństwa danych tego sprzętu. Niektóre miejsca publiczne stawiały nawet zakazy używania Google Glass na ich terenie (później ta sama historia powtórzyła się z grą „Pokémon GO”).
Niedawno Apple opublikował Vision Pro – produkt o wysokiej cenie, funkcjonalności dostępnej w innych, tańszych alternatywach i tych samych problemach etycznych, które towarzyszyły branży AR od jej początku. Technologia i rozdzielczość poszły do przodu, jednak nadal nie ma jasnej, prawno-społecznej odpowiedzi na to, czy chodzenie wszędzie z kamerą w postaci sprzętu AR powinno być dozwolone. Jednak wiele zmieniło się przez dekadę od powstania Google Glass. Dzisiaj nikogo już nie dziwi wszechobecność (wyposarzonych w kamery) smartfonów. Coraz więcej ludzi chodzi do pracy, lub rozmawia z bliskimi przez patrzenie w kamerę. Influencerzy nagrywają vlogi w miejscach publicznych i publikują je w sieci. Czy stosunek społeczeństwa do bycia nagrywanym ocieplił się? Być może koncept publicznie noszonego sprzętu AR przestaje być tabu, a może nawet w przyszłości AR stanie się tak normalny jak dzisiejszy wszechobecny smartfon.
Czas pokaże. Jeszcze za szybko, żeby określić czy Apple Vision Pro jest porażką, czy sukcesem, jednak niewątpliwie po nim przyjdą kolejne iteracje technolgii AR. A problemy etyczne, z którymi ta branża boryka się już od czasów Google Glass, nadal pozostają nierozwiązane…
Literatura
Nagranie z ogłoszenia Google Glass: https://www.youtube.com/watch?v=OLn0cSZfl6c
Art. 81 Pr. Aut. – Zezwolenie na rozpowszechnianie wizerunku: https://sip.lex.pl/akty-prawne/dzu-dziennik-ustaw/prawo-autorskie-i-prawa-pokrewne-16795787/art-81
Projekt „Gendershades”: http://gendershades.org/overview.html
„Racial Discrimination in Face Recognition Technology”: https://sitn.hms.harvard.edu/flash/2020/racial-discrimination-in-face-recognition-technology/
Apple Vision Pro z oficjalnej strona Apple: https://www.apple.com/apple-vision-pro/
„Every Single Sensor inside the Apple Vision Pro and What It’s Individually Designed To Do”: https://www.yankodesign.com/2023/06/07/every-single-sensor-in-the-apple-vision-pro-and-what-its-individually-designed-to-do/
„Google Mistakenly Tags Black People as ‘Gorillas,’ Showing Limits of Algorithms”: https://www.wsj.com/articles/BL-DGB-42522
„Why Google Glass Failed”: https://www.investopedia.com/articles/investing/052115/how-why-google-glass-failed.asp
„How the Pentagon Learned to Use Targeted Ads to Find Its Targets—and Vladimir Putin”: https://www.wired.com/story/how-pentagon-learned-targeted-ads-to-find-targets-and-vladimir-putin/