W ostatnich latach rozwój sztucznej inteligencji (AI) zrewolucjonizował wiele dziedzin naszego życia, od medycyny po marketing. Systemy AI są coraz bardziej zaawansowane, a ich dostępność i koszty stały się gorącym tematem dyskusji. Jak wygląda obecnie sytuacja z dostępnością do systemów AI? Jakie są metody płatności za te technologie i czy lepsze są rozwiązania open source czy komercyjne? Przyjrzyjmy się temu bliżej.

Systemy AI
Systemy AI to szeroka gama narzędzi i technologii, które wykorzystują algorytmy uczenia maszynowego do analizy danych, rozpoznawania wzorców i podejmowania decyzji. Mogą one przybierać różne formy, od prostych chatbotów po złożone systemy predykcyjne.
Dostępność systemów AI
Obecnie dostępność systemów AI zależy od wielu czynników, takich jak koszty licencji, zasoby obliczeniowe oraz stopień zaawansowania technologii. Wiele firm oferuje swoje rozwiązania AI na zasadzie subskrypcji lub jednorazowych opłat licencyjnych. Są również dostępne platformy oferujące modele AI w chmurze, co pozwala na elastyczne korzystanie z technologii bez konieczności posiadania własnej infrastruktury.
Istnieje wiele czynników, które przyczyniają się do potencjalnej nierówności w dostępie do systemów AI:
- Koszty: Rozwój i utrzymanie systemów AI może być bardzo kosztowne. Małe firmy i osoby prywatne często nie mają środków na zakup lub korzystanie z tych systemów.
- Brak danych: Systemy AI wymagają dużej ilości danych do szkolenia. Dostęp do tych danych może być trudny lub kosztowny, szczególnie dla małych firm i osób prywatnych.
- Monopolizacja rynku: Duże firmy technologiczne kontrolują większość najnowocześniejszych technologii AI. Może to ograniczyć dostępność tych technologii dla innych firm i osób prywatnych.
Sposoby płatności za systemy AI
Sposoby płatności za systemy AI są różnorodne i zależą od modelu biznesowego dostawcy. Oto kilka popularnych modeli:
- Subskrypcje: Użytkownicy płacą miesięczny lub roczny abonament za dostęp do zasobów i narzędzi AI. Subskrypcje mogą być atrakcyjne dla firm, które chcą mieć dostęp do najnowszych technologii bez konieczności dużych jednorazowych inwestycji.
- Opłaty za zużyte zasoby (pay-as-you-go): W tym modelu użytkownicy płacą za faktyczne zużycie zasobów, takich jak liczba przetworzonych zapytań, wykorzystanie mocy obliczeniowej czy ilość przechowywanych danych.
- Licencje jednorazowe: Niektóre oprogramowania AI można zakupić na własność za jednorazową opłatą, co często dotyczy bardziej specjalistycznych rozwiązań. Tego rodzaju płatność jest zwykle wybierana przez firmy, które mają stałe i przewidywalne potrzeby oraz dysponują budżetem na jednorazowy większy wydatek.
- Freemium: Model, w którym podstawowe funkcje są dostępne za darmo, ale za dostęp do zaawansowanych opcji trzeba zapłacić. Freemium jest atrakcyjny dla nowych użytkowników, którzy mogą wypróbować technologię przed podjęciem decyzji o płatnym abonamencie.
Porównanie cen modeli AI
Wraz ze wzrostem popularności sztucznej inteligencji ukazały się strony porównujące modele oferowane na rynku. Przykład takiego porównania biorącego pod uwagę cenę korzystania z danej technologii został zaprezentowany poniżej.
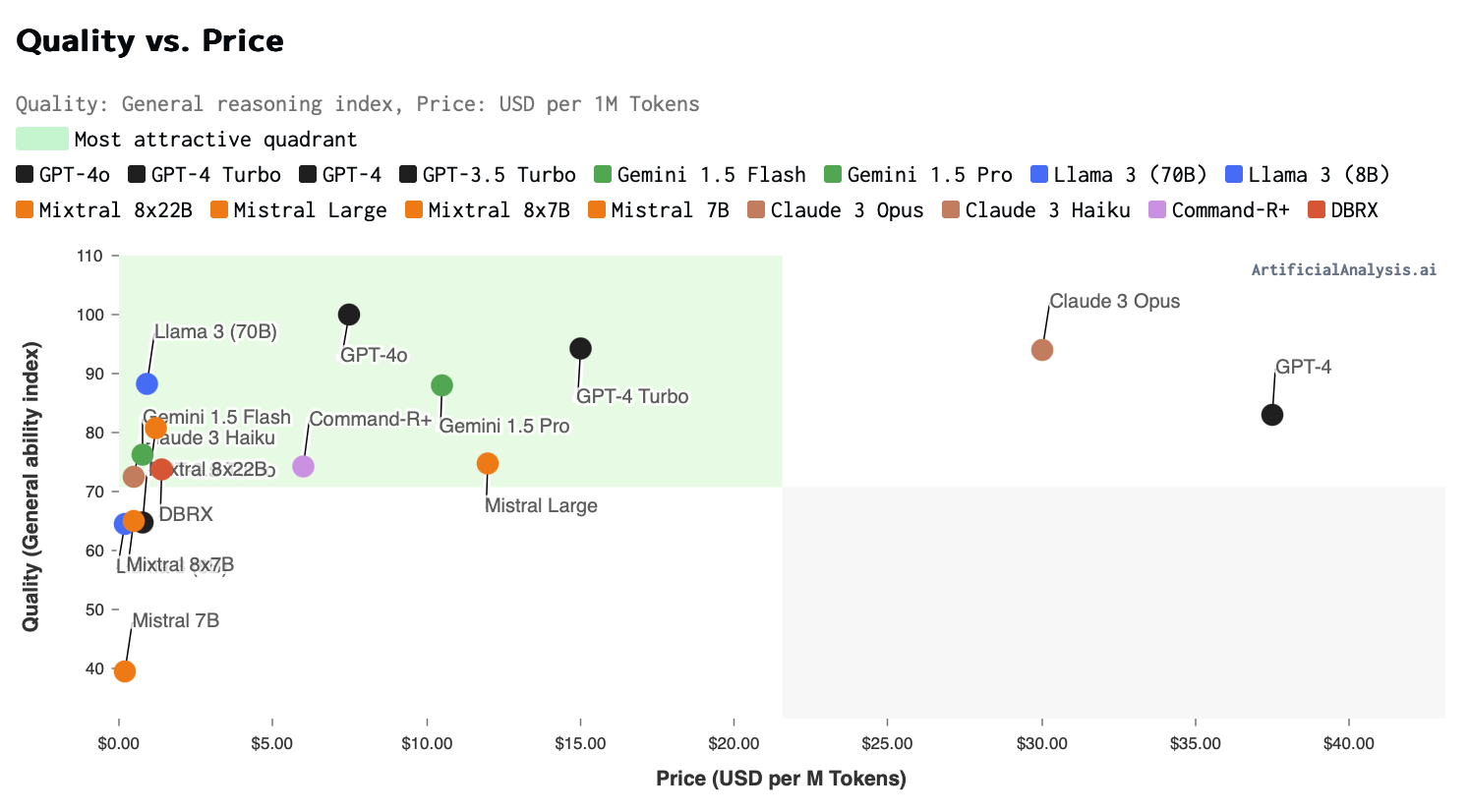
Więcej informacji można znaleźć na stronie: https://artificialanalysis.ai/models/prompt-options/single/short#pricing
Modele płatności oferowane przez najpopularniejsze narzędzia
Poniżej zaprezentowana została lista przykładowych narzędzi sztucznej inteligencji wraz z możliwymi planami subskrypcji (stan na dzień 20.05.2024).
- OpenAI:
- Subskrypcje
- Free: 0$ / miesiąc
- Plus: 20$ / miesiąc
- Team: 30$ / miesiąc
- API
- GPT-4o: Input: 5$ / 1M tokenów – Output: 15$ / 1M tokenów
- Subskrypcje
- Google Gemini
- Subskrypcje
- Gemini: 0$ / miesiąc
- Gemini Advanced: 20$ / miesiąc
- API
- Gemini 1.5 Flash: Input: 0.35$ / 1M tokenów – Output: 1.05$ / 1M tokenów
- Subskrypcje
- Claude AI
- Subskrypcje
- Free: 0$ / miesiąc
- Pro: 20$ / miesiąc
- Team: 30$ / miesiąc
- API
- Haiku: Input: 0.25$ / 1M tokenów – Output: 1.25$ / 1M tokenów
- Sonnet: Input: 3$ / 1M tokenów – Output: 15$ / 1M tokenów
- Opus: Input: 15$ / 1M tokenów – Output: 75$ / 1M tokenów
- Subskrypcje
- Stability AI
- Subskrypcje
- Non-Commercial: 0$ / miesiąc
- Professional: 20$ / miesiąc
- API (10$ / 1000 kredytów)
- Stable Diffusion 3.0: 6.5 kredytów
- SDXL 1.0: 0.2 – 0.6 kredytów
- Stable Video: 20 kredytów
- Subskrypcje
- Midjourney
- Subskrypcje
- Basic: 10$ / miesiąc
- Standard: 30$ / miesiąc
- Pro: 60$ / miesiąc
- Mega: 120$ / miesiąc
- Subskrypcje
- Adobe Firefly
- Subskrypcje
- Free: 0$ / miesiąc
- Premium: 4.99$ / miesiąc
- Single Apps: 9.99$ / miesiąc
- Creative Cloud All Apps: 59.99$ / miesiąc
- Subskrypcje
Open source czy komercjalizacja
Istnieją dwa główne modele rozwoju i dostępu do systemów AI: open source i komercjalizacja.
Open source
Open source to podejście, w którym kod źródłowy oprogramowania jest publicznie dostępny i może być modyfikowany przez każdego. Najbardziej znane projekty open source w dziedzinie AI to TensorFlow, PyTorch czy scikit-learn.
Zalety:
- Dostępność: Oprogramowanie open source jest często dostępne bezpłatnie lub za niską opłatą, co czyni je bardziej dostępnym dla małych firm i osób prywatnych.
- Transparentność: Otwarty kod pozwala na przeglądanie i zrozumienie działania systemu AI, co może zwiększyć zaufanie i bezpieczeństwo.
- Współpraca: Społeczność programistów może wspólnie pracować nad rozwojem i ulepszaniem oprogramowania open source, co może przyspieszyć innowacje.
Wady:
- Brak wsparcia: Oprogramowanie open source może nie mieć oficjalnego wsparcia producenta, co może utrudnić rozwiązywanie problemów.
- Złożoność: Modyfikowanie oprogramowania open source może wymagać wiedzy technicznej, co może być barierą dla niektórych użytkowników.
Często wykorzystywanymi modelami open source są te z rodziny LLaMa, Vicuna i Mistral. Strona HuggingFace prezentuje porównanie otwartych modeli LLM: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard.
Komercjalizacja
Oprogramowanie komercyjne jest rozwijane i sprzedawane przez firmy prywatne.
Zalety:
- Wsparcie: Oprogramowanie komercyjne zazwyczaj ma zapewnione oficjalne wsparcie producenta, co ułatwia rozwiązywanie problemów.
- Łatwość użytkowania: Oprogramowanie komercyjne jest często łatwe w użyciu i nie wymaga wiedzy technicznej.
- Bezpieczeństwo: Oprogramowanie komercyjne jest zazwyczaj bardziej bezpieczne niż oprogramowanie open source, ponieważ podlega rygorystycznym testom bezpieczeństwa.
Wady:
- Koszty: Oprogramowanie komercyjne jest często drogie, co może je czynić niedostępnym dla małych firm i osób prywatnych.
- Brak kontroli: Użytkownicy oprogramowania komercyjnego nie mają kontroli nad kodem źródłowym, co może ograniczać ich możliwości modyfikacji i dostosowania systemu do swoich potrzeb.
- Brak transparentności: Działanie oprogramowania komercyjnego rzadko jest znane użytkownikom, co może budzić obawy o prywatność i bezpieczeństwo.
Badania nad porównaniem modeli open source i closed source
Wraz z rozwojem narzędzi pojawiło się wiele badań porównujących modele open source oraz closed source. W następnych rozdziałach zaprezentowane zostały 3 przykładowe dziedziny, w których przeprowadzono takie eksperymenty.
Konwersja z tekstu na zapytanie SQL
W pracy “Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT – A Text-to-SQL Parsing Comparison” (Sun, S., Zhang, Y., Yan, J., Gao, Y., Ong, D., Chen, B., & Su, J. (2023)) porównano kilka dużych modeli językowych przy bardzo specyficznym zadaniu konwersji z tekstu do zapytań SQL. Dzięki umożliwieniu użytkownikom wyrażania swoich celów w języku naturalnym, takie systemy mogą minimalizować techniczne przeszkody dla mniej doświadczonych użytkowników w interakcji z relacyjnymi bazami danych oraz potencjalnie zwiększać produktywność.
Poniżej zaprezentowana została tabela z wynikami uzyskanymi przez autorów.
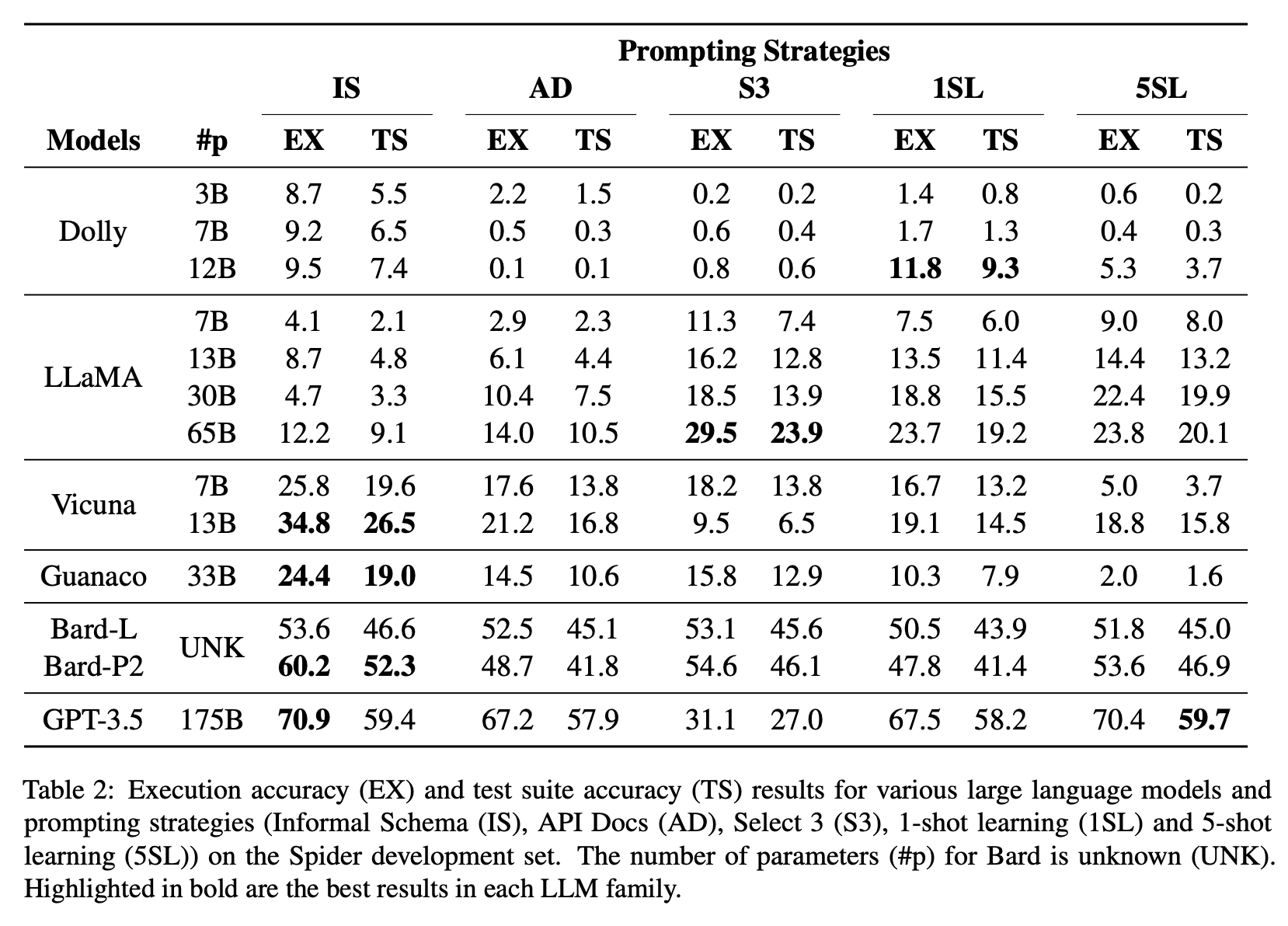
Jeden z wniosków zapisanych w pracy brzmiał następująco:
Modele open-source wykazują znacznie gorszą wydajność w porównaniu do modeli zamkniętych na większości zestawów danych Text-to-SQL.
Klasyfikacja raportów z zdjęć rentgenowskich
Porównanie modeli komercyjnych i modeli open-source przeprowadzono również w ramach pracy “Is open-source there yet? A comparative study on commercial and open-source LLMs in their ability to label chest X-Ray reports.” (Dorfner, F. J., Jürgensen, L., Donle, L., Mohamad, F. A., Bodenmann, T. R., Cleveland, M. C., … & Bridge, C. P. (2024)). Autorzy skupili się na klasyfikacji pełnotekstowych raportów radiologicznych pod kątem listy ważnych wskaźników, co stanowi przykład transformacji tekstu niestrukturyzowanego w dane strukturyzowane.
Obecnie generowanie etykiet z raportów radiologicznych to zadanie wymagające wiedzy ekspertów i dużego nakładu pracy. W konsekwencji, znaczna część badań nad sztuczną inteligencją w medycynie opiera się na ograniczonym wyborze publicznie dostępnych dużych zbiorów danych lub znacznie mniejszych zbiorów danych pochodzących z pojedynczych instytucji. Automatyczne generowanie etykiet z niestrukturyzowanych raportów radiologicznych stanowi efektywne rozwiązanie tych wyzwań.
Badacze wskazali również wady korzystania z komercyjnego modelu z zamkniętym kodem źródłowym, które z ich perspektywy są najważniejsze:
- Prywatność: Wysyłanie danych do zdalnych serwerów podczas przetwarzania tekstu budzi obawy o bezpieczeństwo poufnych informacji, szczególnie w przypadku danych medycznych. Może to być niezgodne z regulacjami prawnymi w niektórych krajach.
- Zmiany w API: Interfejsy API do komunikacji z modelem są regularnie aktualizowane, co może wymagać modyfikacji kodu używanego do przesyłania danych.
- Brak dostępności starszych wersji: Aktualizacje modeli oznaczają, że starsze wersje mogą być niedostępne, co utrudnia badaczom zapewnienie spójności i odtwarzalności wyników badań.
- Koszty: Opłata za korzystanie z modeli OpenAI naliczana jest za każdy token, co może prowadzić do wysokich kosztów przy dużej eksploatacji.
W badaniu wykorzystującym zbiór danych ImaGenome, najlepiej działającym modelem open-source był Llama2-70B, który osiągnął micro-score F1 wynoszące odpowiednio 0,972 i 0,970 dla promptów zero-shot i few-shot. GPT-4 osiągnął micro-score F1 wynoszące odpowiednio 0,975 i 0,984. W przypadku zbioru danych instytucjonalnych, najlepiej działającym otwarto-źródłowym modelem był QWEN1.5-72B, który osiągnął micro-score F1 wynoszące odpowiednio 0,952 i 0,965 dla promptów zero-shot i few-shot. GPT-4 osiągnął micro-score F1 wynoszące odpowiednio 0,975 i 0,973.
Wniosek autorów zawarty w artykule jest następujący:
Podczas, gdy GPT-4 jest lepszy od modeli open-source w etykietowaniu zero-shot, zastosowanie promptowania few-shot pozwala modelom open-source dorównać GPT-4. To pokazuje, że modele open-source mogą być wydajną i zapewniającą ochronę prywatności alternatywą dla GPT-4 w zadaniu klasyfikacji raportów radiologicznych.
Korekta błędów gramatycznych
W artykule “Prompting open-source and commercial language models for grammatical error correction of English learner text” (Davis, C., Caines, A., Andersen, Ø., Taslimipoor, S., Yannakoudakis, H., Yuan, Z., … & Buttery, P. (2024)) oceniono jak dobrze LLM radzą sobie z korekcją błędów gramatycznych mierząc ich skuteczność na zbiorach danych. Ocenione zostało siedem modeli open-source i trzy komercyjne.
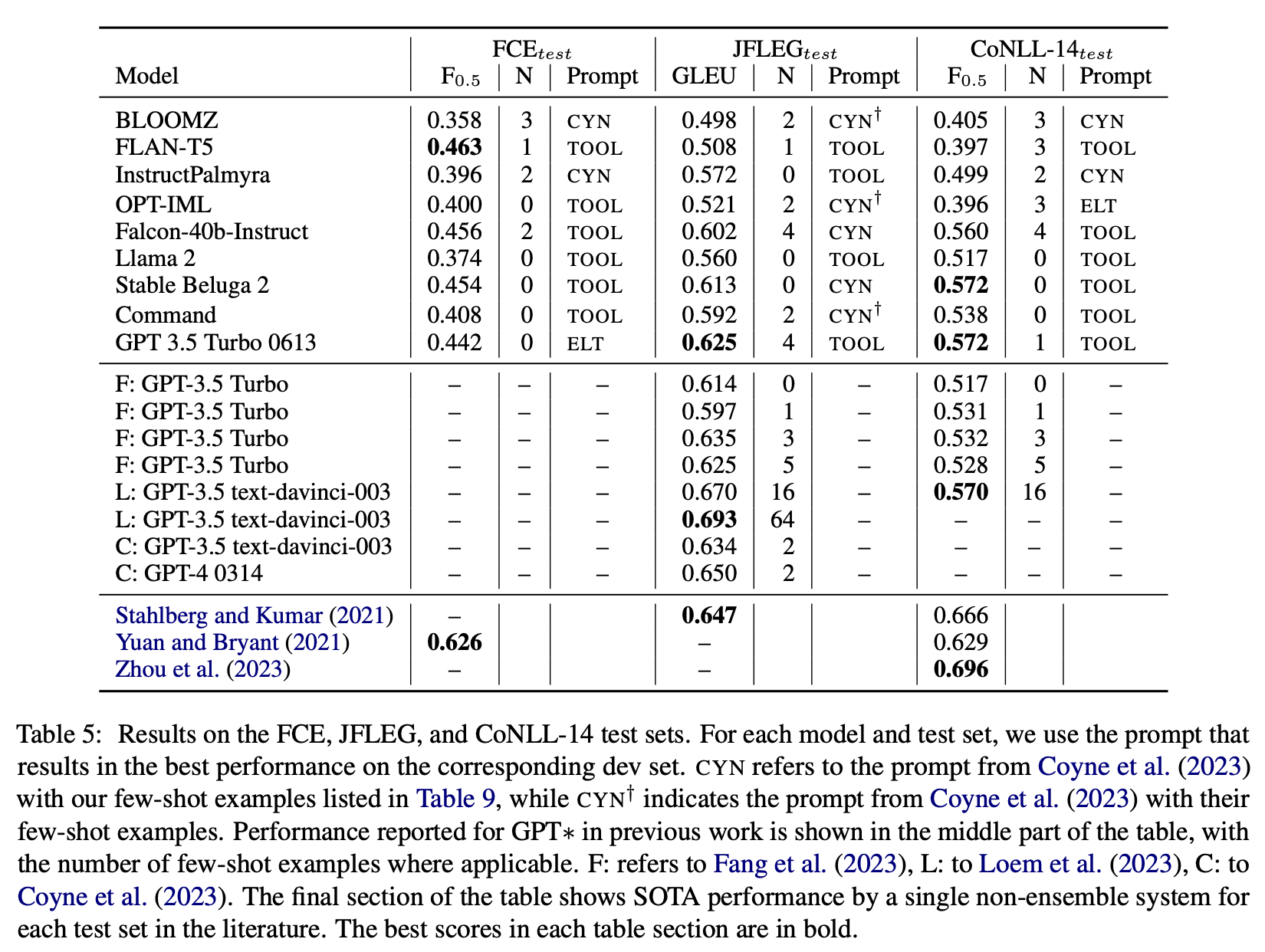
Autorzy stwierdzają, że kilka otwartoźródłowych modeli radzi sobie stosunkowo dobrze – w niektórych testach lepiej niż GPT-3.5.
Perspektywa etyczno-społeczna
Z punktu widzenia etycznego i społecznego, dostępność systemów AI jest kluczowa. Komercjalizacja może prowadzić do wysokich kosztów, ograniczając dostęp do zaawansowanych technologii tylko dla większych firm i zamożniejszych krajów.
Równość dostępu
Jednym z głównych problemów związanych z komercjalizacją AI jest nierówność dostępu do technologii. Duże korporacje i instytucje w krajach rozwiniętych mogą sobie pozwolić na zakup drogich licencji i subskrypcji, podczas gdy mniejsze firmy i organizacje w krajach rozwijających się często nie mają takich możliwości. To prowadzi do technologicznej przepaści, która może pogłębiać istniejące nierówności ekonomiczne i społeczne.
Rozwiązania open source oferują szansę na zmniejszenie tej przepaści, umożliwiając szeroki dostęp do zaawansowanych narzędzi AI bez ponoszenia wysokich kosztów. Dzięki projektom open source, nawet małe firmy i startupy mają szansę na korzystanie z najnowszych technologii, co może przyczynić się do większej innowacyjności i dynamiki na rynku.
Prywatność i odpowiedzialność
Istnieje również problem odpowiedzialności i prywatności. Firmy komercyjne mogą wykorzystywać dane użytkowników do celów marketingowych, co budzi obawy związane z prywatnością. W erze, w której dane są na wagę złota, firmy posiadające dostęp do dużych ilości informacji mogą wykorzystywać je w sposób niejasny dla użytkowników.
Projekty open source, choć bardziej przejrzyste, mogą być podatne na wykorzystanie przez osoby do niewłaściwych celów. Brak centralnego nadzoru i zabezpieczeń może prowadzić do sytuacji, w których technologia AI jest wykorzystywana w sposób niezgodny z jej pierwotnym przeznaczeniem.
Zaufanie i przejrzystość
Zaufanie do systemów AI jest kluczowe dla ich szerokiego przyjęcia i akceptacji społecznej. Komercyjne firmy muszą działać w sposób przejrzysty i zgodny z najwyższymi standardami etycznymi, aby budować zaufanie wśród swoich użytkowników. Ważne jest, aby firmy te były otwarte na audyty zewnętrzne i transparentne w kwestii sposobów zbierania i wykorzystywania danych.
Projekty open source z kolei mogą zyskać na zaufaniu dzięki swojej transparentności. Każdy może przeanalizować kod źródłowy, co zwiększa przejrzystość i umożliwia wykrycie potencjalnych problemów. Jednak brak formalnej odpowiedzialności może być również wadą, ponieważ nie ma centralnej jednostki odpowiedzialnej za jakość i bezpieczeństwo oprogramowania.
Przyszłość
Przyszłość AI prawdopodobnie będzie wymagała znalezienia równowagi między open source a komercjalizacją. Oba podejścia mają swoje unikalne zalety i wady, a ich koegzystencja może przynieść najlepsze efekty.
Przykładem takiej współpracy mogą być modele open-source z rodziny Gemma udostępnione przez firmę Google, powstały one na podstawie badań i technologii wykorzystanej przy tworzeniu Gemini. Wraz z modelami udostępnione zostały również narzędzia pozwalające ułatwiające zapoznanie się z tą technologią:
Więcej informacji dostępnych jest na stronie: https://blog.google/technology/developers/gemma-open-models/
Innowacyjność
Open source może stymulować innowacyjność, umożliwiając szeroki dostęp do technologii i zachęcając do eksperymentów. Komercjalizacja może wspierać rozwój poprzez zapewnienie środków na badania i rozwój oraz profesjonalne wsparcie techniczne.
Dostępność
Dzięki open source technologia AI staje się dostępna dla szerokiego kręgu użytkowników, w tym małych firm i organizacji non-profit. Komercyjne rozwiązania mogą oferować bardziej zaawansowane i stabilne narzędzia, które są kluczowe dla dużych przedsiębiorstw.
Bezpieczeństwo i jakość
Open source pozwala na szeroką inspekcję kodu, co może przyczynić się do wyższego poziomu bezpieczeństwa. Komercjalizacja zapewnia systematyczne testowanie i profesjonalne wsparcie, co przekłada się na jakość i niezawodność systemów.
Współpraca i regulacje
Aby osiągnąć najlepsze rezultaty, konieczna jest współpraca między sektorem prywatnym, publicznym i społecznościami open source. Rządy i organizacje międzynarodowe mogą odgrywać kluczową rolę w tworzeniu regulacji, które zapewnią równy dostęp do technologii AI, ochronę prywatności oraz odpowiedzialne wykorzystanie danych.
Podsumowanie
Rozwój AI niesie za sobą ogromny potencjał, ale także wyzwania związane z dostępnością, kosztem i etyką. Ważne jest, aby znalazło się miejsce zarówno dla modeli komercyjnych i tych open-source. Jednym z największych wyzwań będzie uniknięcie sytuacji, w której postęp w sztucznej inteligencji będzie ograniczony do gigantów technologicznych (z powodu kosztów rozwoju i dostępnych danych). Dobrą prognozą na przyszłość jest chęć rozwijania rozwiązań open-source również przez firmy takie jak Google czy Meta. Niezależnie od wybranego modelu, rozwój AI powinien zawsze uwzględniać dobro społeczne i dążyć do zmniejszania nierówności technologicznych.
Literatura
Podczas pisania tego artykułu wykorzystano następujące źródła:
- Sun, S., Zhang, Y., Yan, J., Gao, Y., Ong, D., Chen, B., & Su, J. (2023). Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT–A Text-to-SQL Parsing Comparison. arXiv preprint arXiv:2310.10190.
- Dorfner, F. J., Jürgensen, L., Donle, L., Mohamad, F. A., Bodenmann, T. R., Cleveland, M. C., … & Bridge, C. P. (2024). Is Open-Source There Yet? A Comparative Study on Commercial and Open-Source LLMs in Their Ability to Label Chest X-Ray Reports. arXiv preprint arXiv:2402.12298.
- Davis, C., Caines, A., Andersen, Ø., Taslimipoor, S., Yannakoudakis, H., Yuan, Z., … & Buttery, P. (2024). Prompting open-source and commercial language models for grammatical error correction of English learner text. arXiv preprint arXiv:2401.07702.
- https://openai.com/chatgpt/pricing/
- https://ai.google.dev/pricing?hl=pl
- https://platform.stability.ai/pricing
- https://docs.midjourney.com/docs/plans
- https://www.adobe.com/pl/products/firefly/plans.html
- https://www.anthropic.com/claude
Świetny komentarz. Jak to często bywa w dyskursie etycznym, nie da się tego problemu rozwiązać zero-jedynkowo. Humaniści jak najbardziej się…