Big Data i sztuczna inteligencja (SI) stają się fundamentami współczesnej medycyny, oferując ogromne możliwości oraz nowe wyzwania. Elektroniczne kartoteki pacjentów (EHR), modele predykcyjne oparte na uczeniu maszynowym oraz zdalne konsultacje lekarskie to tylko niektóre z innowacji, które zmieniają oblicze opieki zdrowotnej. Prognozy wskazują, że globalny rynek informatyki zdrowotnej osiągnie wartość ponad 100 miliardów dolarów do 2032 roku, co podkreśla znaczenie tych technologii w poprawie jakości i efektywności usług medycznych. Jakie są korzyści i zagrożenia związane z cyfryzacją zdrowia oraz jak zadbać o bezpieczeństwo danych medycznych?
Big Data – możliwości i wyzwania
Termin Big Data odnosi się do bardzo dużych zbiorów danych, które charakteryzują się dużą różnorodnością, często spowodowaną między innymi pochodzeniem z różnych źródeł. Obszerność tych zbiorów powoduje, że przetwarzanie ich ręcznie jest niemalże niemożliwe, dlatego w tym celu stosowane są metody sztucznej inteligencji (SI). Wykorzystywanie SI w coraz większej liczbie aspektów życia codziennego, z jednej strony niesie wiele możliwości i korzyści, a z drugiej strony budzi wiele kontrowersji. Zaletą Big Data niewątpliwie jest przetwarzanie nieporównywalnie większej ilości danych niż mógłby to zrobić człowiek, dzięki czemu z tych samych danych można otrzymać więcej informacji. Innym aspektem, który można nazwać zarówno zaletą, jak i wadą, jest mechaniczne działanie sztucznej inteligencji. Każdy człowiek popełnia błędy, a korzystając ze sztucznej inteligencji, można zminimalizować liczbę pomyłek wynikających z błędu ludzkiego. Z drugiej strony, w wielu przypadkach potrzebna jest indywidualna, ludzka analiza danego problemu, a nie tylko działanie na podstawie schematów. Z tego powodu nie można powierzyć wszystkich zadań wyłącznie sztucznej inteligencji, warto jednak używać jej jako narzędzia wspomagającego.
Dziedziną, w której Big Data i sztuczna inteligencja z roku na rok odgrywają coraz większą rolę, jest zdrowie publiczne oraz medycyna. Można to zaobserwować między innymi poprzez cyfryzację opieki zdrowotnej, zwłaszcza od czasów pandemii COVID-19. Według raportu globalny rynek informatyki zdrowotnej ma stale rosnąć. Do 2032 roku ma on osiągnąć wartość ponad 100 miliardów dolarów, ze średniorocznym wzrostem 12,3%, co świadczy o dynamicznym rozwoju tego sektora.
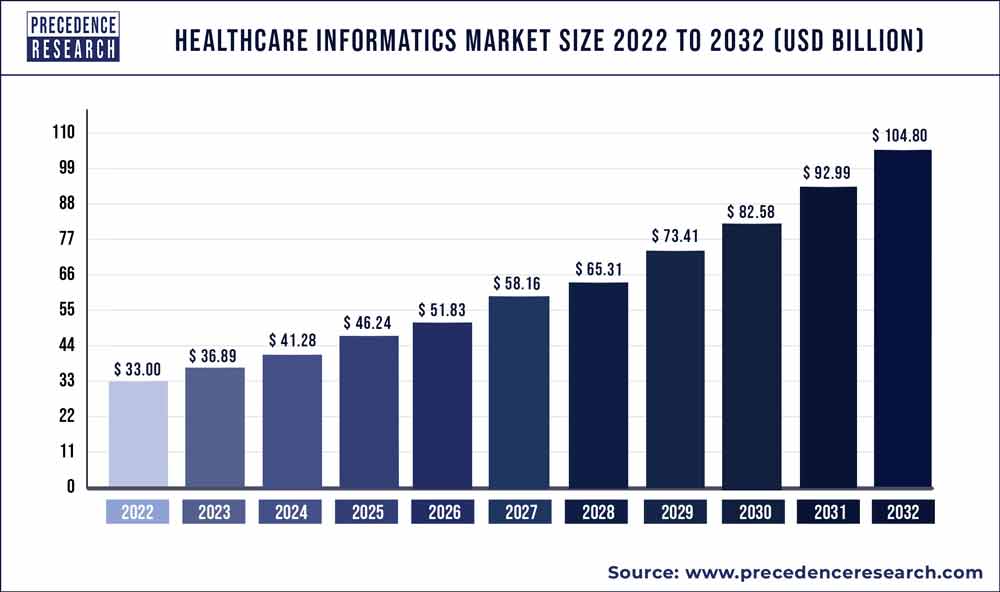
Szacowane wartości rynku informatyki zdrowotnej w latach 2022-2032
Cyfrowa opieka zdrowotna
Najczęstszym źródłem big data w opiece zdrowotnej są elektroniczne kartoteki pacjenta, szerzej znane jako EHR (ang. Electronic Health Records), które zawierają historię chorób pacjenta, diagnozy oraz zabiegi wykonywane przez lekarzy, specjalistów, chirurgów itp. W przeszłości takie informacje były zapisywane w ręcznie pisanych aktach, które łatwo było zgubić, trudno było udostępniać i często były nieczytelne. Dziś EHR umożliwiają pracownikom służby zdrowia łatwy dostęp do istotnych informacji medycznych pacjenta, co pozwala na świadczenie najlepszej możliwej opieki. Integrując big data generowane przez EHR z zaawansowanymi technikami analitycznymi, takimi jak uczenie maszynowe, badacze medyczni mogą tworzyć predykcyjne modele uczenia maszynowego o różnych zastosowaniach, takich jak przewidywanie powikłań pooperacyjnych, niewydolności serca czy nadużywania substancji. Według Enterprise Apps Today w 2023 sztuczna inteligencja zdecydowanie największą rolę odgrywała w radiologii (75,2%) oraz kardiologii (10,9%).
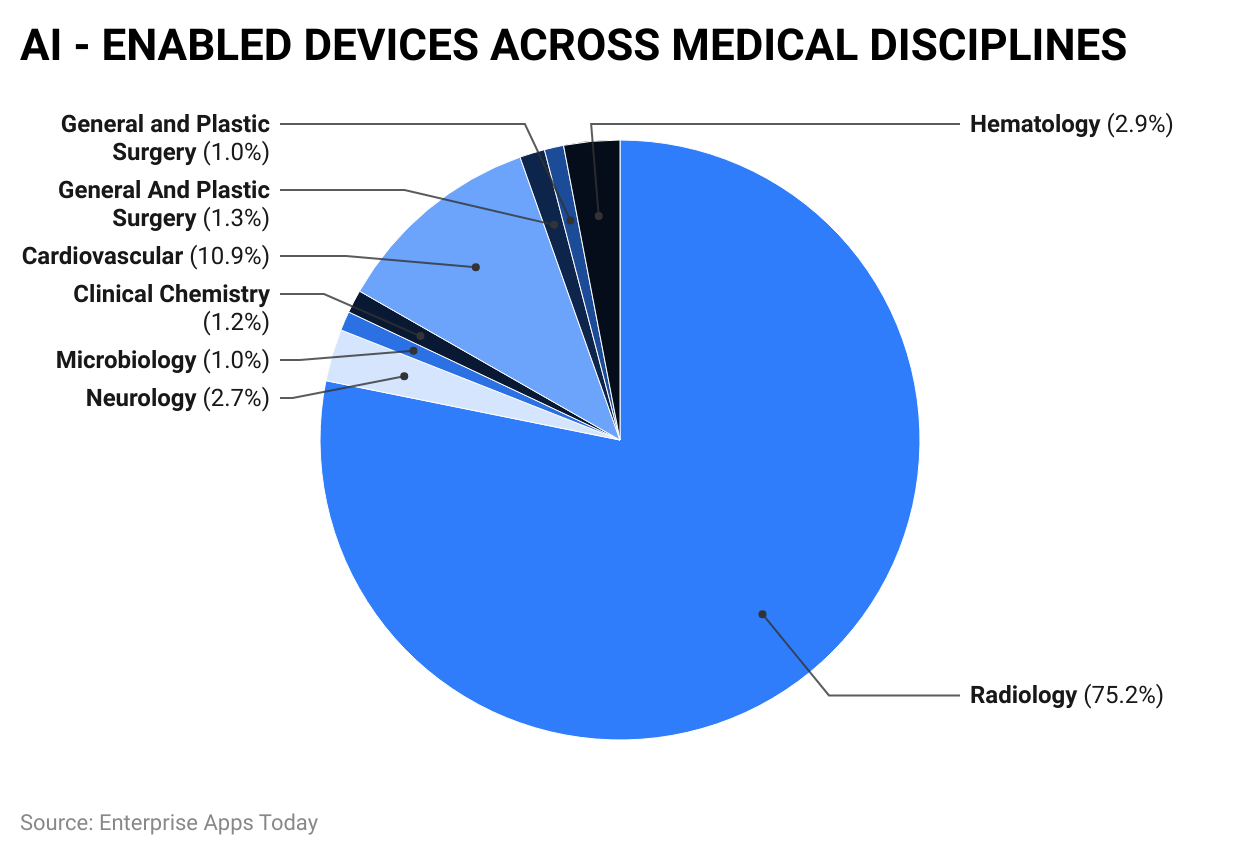
Urządzenia wspomagane sztuczną inteligencją wśród dyscyplin medycyny
Zalety systemu EHR obejmują:
- aktualizację dokumentacji w czasie rzeczywistym,
- pełną dokumentację obejmującą parametry zdrowotne (np. ciśnienie krwi), wyniki badań laboratoryjnych, alergie, wyniki badań obrazowych (RTG, TK, MR),
- możliwość korzystania z danych przez różnych specjalistów, laboratoria, zakłady obrazowania, apteki, jednostki pogotowia ratunkowego i za granicą.
System EHR ma na celu usprawnienie przebiegu wizyty u lekarza i pomaga minimalizować czas potrzebny na formalności, co pozwala lekarzom poświęcić więcej uwagi pacjentom. EHR umożliwia dostęp do danych pacjenta nie tylko w placówce, w której tworzona jest dokumentacja, ale wszędzie niezależnie od typu placówki. Lekarz, mając dostęp do pełnej historii choroby pacjenta w systemie EHR, może szybciej i efektywniej pomóc pacjentowi, co jest szczególnie ważne w nagłych przypadkach, gdy pacjent trafia do szpitala nieprzytomny lub nie pamięta kluczowych informacji zdrowotnych. System EHR umożliwia również konsultacje i ocenę wyników badań z innymi lekarzami, niezależnie od ich lokalizacji.
W Polsce obecna jest elektroniczna dokumentacja medyczna (EDM). Według definicji pacjent.gov.pl, gdy pacjent trafia do lekarza, do dentysty czy do szpitala i ma kontakt z systemem opieki zdrowotnej, to powstaje zdarzenie medyczne. Zdarzenia medyczne są odnotowywane w systemie e-zdrowie, a obywatel może je zobaczyć na swoim Internetowym Koncie Pacjenta (IKP), a także w aplikacji mojeIKP. Każdy lekarz i gabinet od 1 lipca 2021 roku mają obowiązek raportowania zdarzeń medycznych, również w przypadku leczenia prywatnego. Na tym samym koncie znajduje się również osobiste EDM. Wgląd do niego ma jego właściciel, lekarz POZ (podstawowa opieka zdrowotna), a także lekarz specjalista, któremu nada się do niego dostęp.
Cyfryzacja opieki zdrowotnej sprawiła, że w niektórych przypadkach wizyta z lekarzem niekoniecznie musi odbywać się personalnie. W okresie pandemii, w celu zapobiegania niepotrzebnych kontaktów, zaczęła pojawiać się możliwość umówienia na teleporadę. Ze względu na wygodę takiego rozwiązania, nadal jest ono powszechne, chociaż ma również przeciwników. Raport firmy Accenture z 2020 roku pokazuje podejście ludzi z różnych pokoleń do wirtualnych wizyt lekarskich. Można zauważyć, że 81% ankietowanych woli wizyty osobiste niż zdalne. Starsze pokolenia są sceptycznie nastawione do wizyt online, podczas gdy wśród coraz młodszych widać tendencję wzrostową wizyt zdalnych.
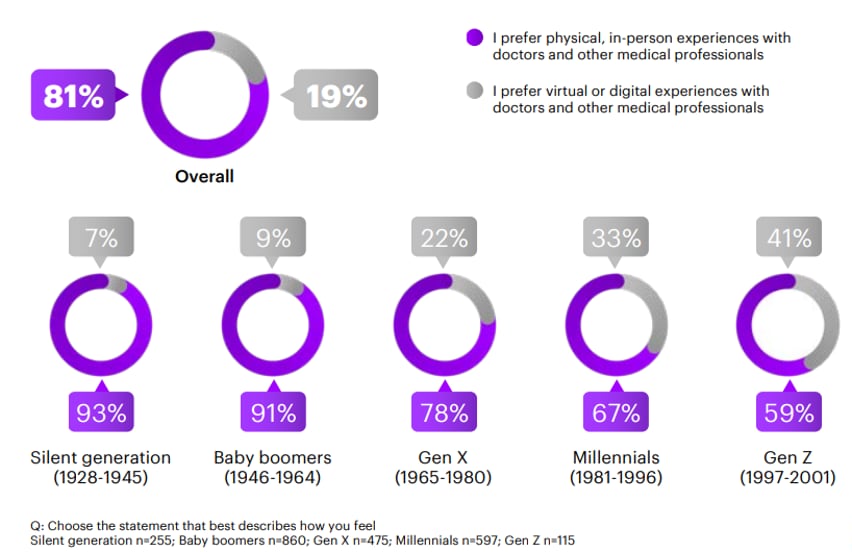
Preferencje dotyczące osobistych i zdalnych wizyt lekarskich z podziałem na grupy wiekowe
Nowa era medycyny
Według artykułu z 2018 roku, 30% danych z całego świata było generowane przez branżę opieki zdrowotnej. Szacowało się, że wartość ta do końca 2025 roku wzrośnie do 36%. Znaczna większość danych z opieki zdrowotnej jest nieustrukturyzowana, co jest spowodowane tym, że 80% całych danych klinicznych stanowią obrazowania medyczne. Nie jest to takie szokujące, jeśli zdamy sobie sprawę z faktu, że przeciętne zdjęcie rentgenowskie zajmuje kilkanaście megabajtów, a plik cyfrowej patologii może mieć rozmiar kilku gigabajtów. Według artykułu z 2019 roku z World Economic Forum, 97% tych danych nie było wykorzystywane w żaden sposób. Obecnie ten trend się zmienia, co ma ogromny potencjał na podniesienie jakości opieki zdrowotnej, głównie za sprawą coraz częstszego stosowania algorytmów uczenia maszynowego oraz tworzenia aplikacji znacznie przyspieszających pracę personelu medycznego.
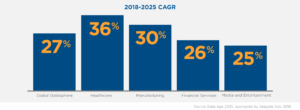
Wszystkie te dane mogą zostać wykorzystane do wielu istotnych zadań. Najczęściej pojawiającymi się pomysłami wykorzystania data science w sektorze medycznym to:
Wynajdywanie leków
Stworzenie nowego i w pełni sprawdzonego leku może kosztować miliardy dolarów i trwać kilkanaście lat. Dzięki symulacjom reakcji białek oraz komórek ludzkich na dany lek, czas ten może być zredukowany nawet do dwóch lat.
Zapobieganie oraz wykrywanie chorób
Jednym z kluczowych zastosowań big data w medycynie jest prewencja i wczesne wykrywanie chorób. Dzięki analizie danych z różnych źródeł, takich jak elektroniczne kartoteki pacjentów, wyniki badań laboratoryjnych, czy nawet informacje ze smartwatchy, możliwe jest identyfikowanie wzorców wskazujących na wczesne stadia chorób. Algorytmy uczenia maszynowego mogą wykrywać subtelne zmiany w zdrowiu pacjentów, które mogłyby zostać przeoczone przez lekarzy.
Personalizacja leczenia
Big data pozwala na personalizację leczenia, czyli dostosowanie terapii do indywidualnych potrzeb pacjenta. Analiza genetyczna oraz wykrywanie pewnych biomarkerów umożliwia tworzenie spersonalizowanych planów leczenia, które są bardziej skuteczne i mają mniej skutków ubocznych. Na przykład, dane z badań genetycznych mogą pomóc w przewidywaniu, jak pacjent zareaguje na określony lek, co pozwala lekarzom na lepsze dostosowanie terapii.
Monitorowanie i zarządzanie chorobami przewlekłymi
W przypadku chorób przewlekłych, takich jak cukrzyca, choroby serca czy astma, big data umożliwia stałe monitorowanie stanu zdrowia pacjentów i szybką interwencję w razie potrzeby. Dane z urządzeń noszonych przez pacjentów, jak glukometry, czy ciśnieniomierze, są przesyłane do systemów analizujących, które na bieżąco oceniają stan zdrowia i sugerują podjęcie odpowiednich działań.
Przykłady data science w opiece zdrowotnej
IBM Watson for Oncology
Oprogramowanie jako usługa (SaaS) wykorzystujące sztuczną inteligencję, wspomagające onkologów w podejmowaniu świadomych decyzji dotyczących leczenia raka. Watson dostarcza spersonalizowane rekomendacje leczenia, uwzględniając unikalny genotyp pacjenta, co zwiększa precyzję opieki onkologicznej oraz przyspiesza proces decyzyjny.
Przetwarzanie języka naturalnego w Mayo Clinic
Wykorzystywanie przetwarzania języka naturalnego (NLP) do wydobywania cennych informacji z nieustrukturyzowanych notatek klinicznych. Algorytmy NLP analizują notatki napisane przez personel medyczny, wyodrębniając istotne dane, takie jak diagnozy, plany leczenia i wyniki pacjentów. Te dane, po ustrukturyzowaniu, wspierają podejmowanie decyzji klinicznych i pozwalają na lepsze zrozumienie historii pacjentów.
Google Health
Analizując duże zbiory danych medycznych, Google Health identyfikuje wzorce i czynniki ryzyka związane z różnymi chorobami i pomaga wykrywać je na wczesnym etapie. Są to między innymi wykorzystanie widzenia komputerowego do analizy obrazów siatkówki ludzkiego oka w celu wczesnego wykrywania zdarzeń sercowo-naczyniowych, jak zawał serca czy udar oraz wykorzystanie uczenia głębokiego do wykrywania raka piersi.
Przypadki naruszenia prywatności
Reidentyfikacja danych medycznych Williama Welda jest jednym z najbardziej znanych przypadków naruszenia prywatności w historii ochrony danych medycznych. Ten przypadek miał miejsce w latach 90. XX wieku i jest często cytowany jako przykład ryzyka związanego z udostępnianiem „anonimowych” danych medycznych. Latanya Sweeney, doktorantka na MIT pokazała, w jaki sposób można zreidentyfikować dane przy użyciu ogólnodostępnych informacji, mając dostęp do teoretycznie zanonimizowanych danych medycznych. Zanonimizowane dane medyczne, udostępnione w celach naukowych, zawierały szczegóły wizyt szpitalnych, takie jak diagnozy, procedury, wiek pacjentów, płeć i kod pocztowy. Publicznie dostępne rejestry wyborców zawierają natomiast imiona, nazwiska, adres, datę urodzenia i płeć wyborców z danego regionu. Na podstawie informacji wspólnych z obu zbiorów, możliwe było zidentyfikowanie, które dane medyczne dotyczą gubernatora Welda, ponieważ był jedynym pacjentem z jego kodem pocztowym, datą urodzenia oraz płcią.

Zilustrowanie przypadku reidentyfikacji danych Williama Welda
W 2022 roku Indie doświadczyły poważnego ataku cybernetycznego na jedną z najważniejszych placówek medycznych w kraju – All India Institute of Medical Sciences (AIIMS) w Nowym Delhi. Atak rozpoczął się 23 listopada i sparaliżował operacje szpitala na prawie dwa tygodnie. W wyniku tego pacjenci nie mogli rejestrować się na wizyty, a lekarze nie mieli dostępu do kartotek medycznych, co znacząco wpłynęło na jakość i efektywność opieki zdrowotnej. Szacuje się, że w wyniku tego incydentu mogły zostać naruszone dane ponad 30 milionów pacjentów. Sytuacja ta uwypukliła luki w cyberbezpieczeństwie indyjskiego systemu opieki zdrowotnej, szczególnie w kontekście szybko postępującej cyfryzacji danych medycznych. Chociaż szpital współpracował z władzami federalnymi, aby przywrócić systemy i wzmocnić swoje zabezpieczenia, incydent ten podkreślił pilną potrzebę wdrożenia bardziej zaawansowanych środków ochrony danych w sektorze zdrowia.
Wyzwania związane z prywatnością danych
Wraz z rozwojem i wdrażaniem innowacji opartych na sztucznej inteligencji w opiece zdrowotnej, pojawiają się istotne obawy związane z ochroną danych. Mimo że dane są często deidentyfikowane, istnieje ryzyko, że nowe metody analizy mogą umożliwić ponowną identyfikację tych danych. Przykładowo badanie z 2018 roku wykazało, że algorytm mógł ponownie zidentyfikować znaczną część uczestników badania, pomimo usunięcia danych identyfikacyjnych. AI w opiece zdrowotnej korzysta zarówno z chronionych informacji zdrowotnych, jak i z danych generowanych przez użytkowników, takich jak śledzenie zdrowia na urządzeniach smart czy historia wyszukiwania w Internecie. Usunięcie identyfikatorów zgodnie z przepisami może nie być wystarczające, jeśli dane te mogą zostać ponownie zidentyfikowane przez powiązanie z innymi zestawami danych.
Naruszenia prywatności mogą mieć konsekwencje zarówno mierzalne, takie jak dyskryminacja w miejscu pracy czy wyższe składki ubezpieczeniowe, jak i niemierzalne, wynikające z poczucia utraty kontroli, co może prowadzić do traumy psychicznej. Problemy pojawiają się również przy udostępnianiu danych między różnymi jurysdykcjami, gdzie obowiązują różne przepisy dotyczące ochrony danych. Ponadto, dane używane do szkolenia algorytmów mogą być źródłem różnych uprzedzeń. Dane pochodzące z elektronicznych kartotek mogą być bardziej reprezentatywne dla osób z wyższej klasy społeczno-ekonomicznej, co może prowadzić do niedopasowanych rekomendacji dla marginalizowanych grup społecznych.
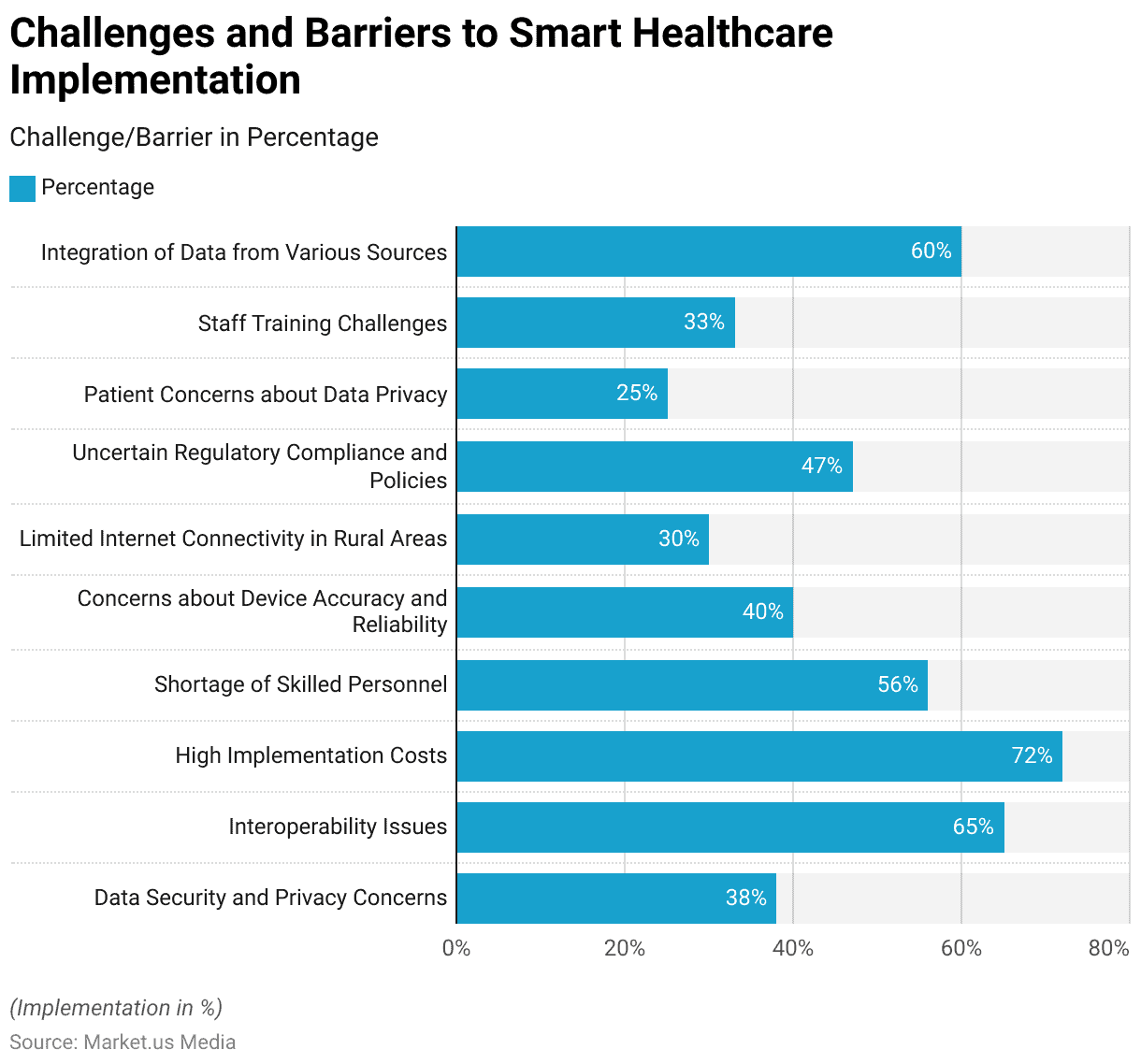
Wyzwania i bariery związane z Big Data w zdrowiu publicznym
Głównymi wyzwaniami związanymi z prywatnością danych są:
Zwiększone ryzyko naruszeń danych
Ogromna ilość danych zdrowotnych czyni je atrakcyjnym celem dla cyberprzestępców. Naruszenia danych mogą prowadzić do nieautoryzowanego dostępu, kradzieży tożsamości i naruszenia poufności pacjentów.
Problemy etyczne
Zrównoważenie korzyści płynących z big data z etycznymi rozważaniami jest skomplikowanym zadaniem. Pojawiają się pytania o to, kto jest właścicielem danych, jak są one wykorzystywane i czy pacjenci mają kontrolę nad ich wykorzystaniem.
Zgodność z przepisami
Dostawcy opieki zdrowotnej muszą przestrzegać różnych przepisów dotyczących ochrony danych, takich jak HIPAA w Stanach Zjednoczonych RODO w Unii Europejskiej. Nieprzestrzeganie tych przepisów może skutkować poważnymi karami.
Źródła
- EDM: https://pacjent.gov.pl/elektroniczna-dokumentacja-medyczna
- EHR: https://synappsehealth.com/pl/articles/i/elektroniczna-dokumentacja-medyczna-systemy-emr-i-ehr/
- Dane 2018-2025: https://www.seagate.com/files/www-content/our-story/trends/files/idc-seagate-dataage-whitepaper.pdf
- World Economic Forum i 97% danych: https://www.weforum.org/agenda/2019/12/four-ways-data-is-improving-healthcare/
- Wpływ data science na opiekę zdrowotną: https://datascientest.com/en/data-science-and-healthcare-the-impact-on-medicine
- Wyzwania związane z prywatnością: https://www.linkedin.com/pulse/data-privacy-healthcare-ensuring-confidentiality-while-leveraging-3gsnf
- Cyberatak na AIIMS: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10718098/
- Badanie z 2018 roku: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6324329/
- Digital Health’s Role in Improving Patient Engagement: https://www.transperfect.com/blog/digital-healths-role-improving-patient-engagement
- A. Alabdulatif, N. N. Thilakarathne, K. Kalinaki, A Novel Cloud Enabled Access Control Model for Preserving the Security and Privacy of Medical Big Data
- Healthcare Informatics Market: https://www.precedenceresearch.com/healthcare-informatics-market
- How can leaders make recent digital health gains last?: https://www.accenture.com/us-en/insights/health/leaders-make-recent-digital-health-gains-last
- Smart Healthcare Statistics 2024 By Technology, Healthcare, AI: https://media.market.us/smart-healthcare-statistics/
- D. C. Barth-jones, The „Re-identification” of Governor William Weld’s Medical

[…] poprzednim artykule skupiliśmy się na seks robotach w ogólności, a także na najpopularniejszej formie tego […]