Klonowanie głosu to jedna z najbardziej fascynujących, ale i niepokojących innowacji w dziedzinie sztucznej inteligencji. Jeszcze niedawno traktowane jako ciekawostka technologiczna, dziś znajduje zastosowanie w filmach, grach wideo i dubbingu, a nawet pozwala artystom „śpiewać” pośmiertnie nowe utwory. Jednak wraz z rozwojem tej technologii pojawiły się także ciemne strony – coraz częściej słyszymy o oszustwach finansowych, fałszywych nagraniach politycznych czy deepfake’ach wykorzystywanych do manipulacji opinią publiczną. Czy potrafimy jeszcze odróżnić prawdziwy głos od jego cyfrowej imitacji? A może wkraczamy w epokę, w której nie będziemy mogli ufać nawet własnym uszom?
Technologia klonowania głosu, umożliwia tworzenie syntetycznych kopii personalnej barwy i tembru głosu, które są niemal nie do odróżnienia od oryginału. Proces tworzenia klona głosowego składa się zazwyczaj z kilku etapów [1]:
Próbkowanie głosu: Zebranie danych audio od osoby, której głos ma być sklonowany. Im więcej zebranych próbek, tym dokładniejszy będzie efekt końcowy.
Analiza i ekstrakcja cech: Analiza nagrań w celu zidentyfikowania unikalnych cech głosu, takich jak tembr (barwa głosu). Cechy często związane są z tagami lub kategoriami takimi jak wiek czy płeć mówcy.
Trenowanie modelu AI: Wykorzystanie wyodrębnionych cech do nauczenia modelu uczenia maszynowego, który potrafi naśladować specyficzne właściwości głosu.
Synteza mowy: Generowanie nowej wypowiedzi sklonowanym głosem, nawet zdań, których pierwotny mówca nigdy nie wypowiedział.
Podczas klonowania głosu kluczowe jest oddzielenie cech charakterystycznych dla danej osoby (takich jak ton, intonacja, akcent, barwa głosu) od treści wypowiedzi. Proces ten opiera się na zaawansowanych technikach przetwarzania sygnału i sztucznej inteligencji. Zamiast analizować znaczenie wypowiadanych słów, system koncentruje się na akustycznych właściwościach dźwięku. W tym celu stosuje się analizę częstotliwościową, w której głos jest przekształcany w zestaw parametrów opisujących jego fizyczne właściwości. Nowoczesne modele oparte na sztucznej inteligencji, takie jak autoenkodery wariacyjne (VAE) i transformery (np. VALL-E od Microsoftu [4]), uczą się separować styl mowy (czyli unikalne cechy głosu) od treści językowej (czyli samych słów). Sieci te analizują tysiące próbek i identyfikują wzorce specyficzne dla danej osoby.
Po ekstrakcji cech system zapisuje je w wektorze charakterystycznym dla danej osoby. Następnie, gdy dostarczymy nowy tekst do wypowiedzenia, syntezator mowy (np. Tacotron 2 [5] lub WaveNet [6]) generuje nowe nagranie, ale z zastosowaniem sklonowanych cech głosu. Starsze technologie, używały wcześniej nagranych fragmentów mowy i łączyły je w nowe zdania. To jednak ograniczało naturalność i ekspresję mowy. Nowoczesne systemy natomiast wykorzystują sieci neuronowe do generowania sygnału mowy od podstaw. Modele akustyczne (np. Tacotron 2) uczą się odwzorowywać strukturę głosu, w tym intonację, akcenty i melodię mowy.
Potencjalne zastosowania technologii klonowania głosu są różnorodne:
- Rozrywka: Tworzenie głosów postaci w filmach, grach wideo i animacjach, co umożliwia realistyczne dubbingowanie bez konieczności fizycznej obecności aktorów głosowych.
- Asystenci głosowi: Personalizacja wirtualnych asystentów, takich jak Siri czy Alexa, pozwalająca użytkownikom wybrać preferowany głos, co sprawia, że interakcja jest bardziej spersonalizowana.
- Medycyna: Pomoc osobom z zaburzeniami mowy lub tym, którzy stracili głos z powodu choroby, oferując możliwość odtworzenia ich naturalnego głosu.
- Obsługa klienta: Tworzenie realistycznych i interaktywnych odpowiedzi głosowych, oferujących bardziej spersonalizowane doświadczenie dla klientów.
Niemniej jednak, technologia ta niesie ze sobą potencjalne zagrożenia i wyzwania etyczne. Klonowanie głosu może być wykorzystane do tworzenia fałszywych nagrań (tzw. deepfake audio), które mogą służyć do oszustw, wyłudzeń czy rozpowszechniania dezinformacji. Przykładem jest zjawisko „vishingu” (phishing głosowy), gdzie przestępcy podszywają się pod zaufane osoby, aby wyłudzić poufne informacje lub środki finansowe.
W związku z tym, istotne jest opracowanie odpowiednich regulacji i standardów branżowych, które zapewnią etyczne wykorzystanie technologii klonowania głosu, chroniąc jednocześnie prywatność i bezpieczeństwo użytkowników.
Etyczne Aspekty Klonowania Głosu
Rozważając etyczność użycia technologii klonowania głosu należy odpowiedzieć na 3 podstawowe pytania [2]:
Kto usłyszy i będzie używał mojego sklonowanego głosu? Zgodnie z decyzją właściciela głosu, tożsamość jego sklonowanego głosu może być udostępniona odbiorcom, od kameralnych (np. używany tylko przez samego siebie i/lub wybranych bliskich krewnych), przez bardziej ogólne, ale zdefiniowane kontekstem (np. głos wykładowcy używany tylko przez jego uniwersytet), po całkowicie rozpowszechnione (np. głos przekazany do ogólnodostępnej bazy danych do użytku przez każdego).
Jak mój głos będzie używany? Dana osoba może być zadowolona z tego, że jej głos jest używany jako lektor audiobooków dla dzieci, ale nie do czytania książek opisujących drastyczną przemoc; może być zadowolona z bycia głosem raportów pogodowych Amazon Echo, ale nie jako osobisty chatbot w tym samym urządzeniu.
Jak długo mój głos będzie używany? Wykładowca uniwersytecki może preferować, aby jego pracodawca zaprzestał tworzenia nowych treści jego głosem po jego rezygnacji lub przejściu na emeryturę; osoba sporządzająca testament może woleć nałożyć ograniczenia na to, jak jej spadkobiercy będą używać klonu jej głosu po jej śmierci.
Uchwalone w 2024 roku Rozporządzenie Parlamentu Europejskiego i Rady UE w sprawie sztucznej inteligencji [3] wprowadza przepisy dotyczące technologii generujących treści syntetyczne, w tym klonowania głosu. Głos oraz “właściwości mowy” uznawane są jako część profilu biometrycznego człowieka, który to profil powinien podlegać szczególnej ochronie przez niewłaściwym wykorzystaniem w systemach AI. Chociaż wprost nie ma wzmianki o klonowaniu głosu w deepfake’ach, przepisy dotyczące przejrzystości w Artykule 50 mogą mieć zastosowanie także w kontekście technologii generujących syntetyczne głosy, które mogą być użyte do manipulacji lub oszustw. Podobnie jak w przypadku deepfake’ów, jeśli system AI jest wykorzystywany do generowania lub manipulowania treściami audio, twórcy lub użytkownicy tych systemów są zobowiązani do ujawnienia, że zawartość jest sztucznie wygenerowana lub zmodyfikowana. Oznacza to, że gdy klonowanie głosu jest wykorzystywane w publicznych nagraniach, reklamach, filmach lub innych mediach, użytkownicy muszą jasno informować odbiorców, że dany głos jest wygenerowany przez sztuczną inteligencję.
Czy jest jeszcze miejsce na muzyczny geniusz w świecie generatywnej AI?
W kwietniu 2024 roku mogliśmy zaobserwować intrygujące zjawisko. Na kilka tygodni przed premierą najnowszego albumu Taylor Swift, zatytułowanego „The Tortured Poets Department”, w sieci pojawił się rzekomy przeciek pierwszego singla – piosenki „Fortnight” z gościnnym udziałem Post’a Malone. Nagranie to szybko zyskało popularność, wzbudzając duże zainteresowanie zarówno wśród oddanych fanów artystki, jak i szerszego grona słuchaczy.
Jak się jednak później okazało, fragment utworu był dziełem sztucznej inteligencji. Mimo to wielu słuchaczy uwierzyło w jego autentyczność. Co więcej, po premierze prawdziwej wersji „Fortnight” pojawiły się komentarze, w których fani przyznawali, że wersja wygenerowana przez AI była według nich bardziej chwytliwa, a nawet rzucali w eter prośby o wygenerowanie pełnej wersji piosenki. Ich życzenie zostało spełnione, bo kilka tygodni później Max Lange – autor kawałka ze sklonowanymi głosami Taylor Swift i Post Malone, wyprodukował pełnowymiarową piosenkę, będącą przedłużeniem viralowego fragmentu (tym razem piosenka była śpiewana przez prawdziwych ludzi).
To wydarzenie otworzyło ciekawą dyskusję na temat roli sztucznej inteligencji w przemyśle muzycznym oraz percepcji autentyczności w sztuce. Pokazało ono również, jak istotne dla odbioru dzieł artystycznych są subiektywna interpretacja i oczekiwania słuchaczy. Według zeszłorocznych badań [2] uprzednia znajomość mówcy ma duży wpływ na odbiór nagrania wygenerowanego przez AI. Znalazło to też potwierdzenie w wyżej przytoczonej sytuacji – najwięksi fani Taylor Swift z łatwością rozpoznali brak autentyczności, podczas gdy osoby mniej zaznajomione z jej twórczością były bardziej skłonne uznać sztuczny fragment za prawdziwy i wyrażały wobec niego pozytywne opinie. To podkreśla, że w erze zaawansowanych technologii granice między twórczością ludzką a generowaną przez maszyny stają się coraz mniej wyraźne. Dotarliśmy do momentu, gdy przy pomocy jednego prostego prompta, ChatGPT jest w stanie napisać dla nas tekst piosenki z uwzględnieniem stylu wskazanego artysty, a modele generatywne są w stanie tą piosenkę dla nas wykonać. Pytanie, czym jest prawdziwa sztuka nigdy nie było bardziej aktualne.
Co na to artyści?
W kwietniu 2024 roku organizacja Artist Rights Alliance udostępniła list otwarty, wzywający do ochrony muzyków przed nadużyciami wynikającymi z posługiwania się sztuczną inteligencją. Podpisało się pod nim ponad 200 artystów m.in. Billie Eilish, J Balvin, Nicki Minaj, a także legendy, takie jak Stevie Wonder czy REM. List apeluje do firm technologicznych o zaprzestanie tworzenia narzędzi AI, które mogą zastąpić lub podważyć twórczość ludzkich artystów oraz zniszczyć budowaną latami artystyczną tożsamość wielu z nich.
„Ten atak na ludzką kreatywność musi zostać powstrzymany. Musimy chronić się przed niestosownym wykorzystaniem AI do kradzieży głosów i wizerunków profesjonalnych artystów, naruszania praw twórców i niszczenia ekosystemu muzycznego” – czytamy w liście.
Choć list nie wzywa do całkowitego zakazu stosowania AI w muzyce, podkreśla potrzebę odpowiedzialnego i etycznego podejścia do tej technologii. Zaznacza również, że niektóre z największych i najbardziej wpływowych firm wykorzystują pracę muzyków bez ich zgody do trenowania modeli AI. Te działania bezpośrednio zmierzają do zastępowania pracy ludzkich wykonawców ogromnymi ilościami dźwięków i obrazów generowanych przez AI, co bezpośrednio wpływa na zmniejszenie tantiemów wypłacanych artystom. Dla wielu mniejszych artystów oznacza to katastrofalne problemy z utrzymaniem.
W odpowiedzi na rosnące obawy, Tennessee jako pierwszy stan USA wprowadziło prawo nazwane „ELVIS Act”, mające na celu ochronę artystów przed nieautoryzowanym wykorzystywaniem ich głosu przez AI w celach komercyjnych. Prawo weszło w życie 1 lipca 2024 r. i uczyniło nielegalnym replikowanie głosu artysty bez jego zgody.
Poza powyższymi obawami natury etycznej i finansowej, pojawia się też ostra krytyka w kontekście samej filozofii i estetyki. Nick Cave, zapytany o wygenerowaną przez AI piosenkę w jego stylu, odpowiedział:
„Ten utwór to bzdura, groteskowa parodia tego, co znaczy być człowiekiem.”
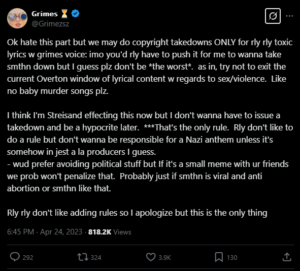
Choć widać, że zdecydowania większość jest nieprzychylna użyciu AI w przemyśle muzycznym, znaleźli się również artyści, którzy są na to otwarci. Przykładem jest kanadyjska piosenkarka i autorka tekstów znana pod pseudonimem Grimes. W 2023 roku wprowadziła w życie projekt „GrimesAI voiceprint”. W ramach tej inicjatywy we współpracy z firmą CreateSafe stworzona została platforma Elf.Tech. Dzięki modelowi wytrenowanemu na próbkach głosu Grimes, twórcy mogą stworzyć oryginalne utwory, w których GrimesAI będzie figurować jako główny lub gościnny artysta. W przypadku zatwierdzenia współpracy, Grimes otrzyma 50% udziału w tantiemach, jednak nie rości sobie praw własności do nagrania ani kompozycji, chyba że jest to cover jej utworu.
Artystka podkreśliła, że podoba jej się idea open source w sztuce i zakończenia praw autorskich, co wywołało gorącą debatę. Ponadto wiele osób wytknęło jej, że ogromna swoboda, na którą przyzwala w swoim projekcie może doprowadzić do sytuacji, gdzie jej głos zostanie użyty w piosence o nieodpowiednich treściach, np. rasistowskich. W odpowiedzi artystka przyznała we wpisie na platformie X, że utwory o “bardzo, bardzo toksycznych słowach” zostaną zdjęte.
https://x.com/grimezsz/status/1650541506925670428
Podsumowanie
Sztuczna inteligencja we wszystkich dziedzinach życia ma swoich przeciwników i zwolenników, nie inaczej jest również w przypadku technologii klonowania głosu. Dzisiaj stoimy przed wieloma pytaniami oraz posiadamy niewiele odpowiedzi, a zalet wydaje się być równie wiele jak zagrożeń. Nadchodzące lata zapowiadają się na czas intensywnych debat i regulacji, gdzie celem będzie znalezienie złotego środka pomiędzy innowacją a ochroną praw twórców.
Źródła
[1] R, Piotr. Deepfakes audio – jak działa? | Bitdefender – program antywirusowy. 15 luty 2024, https://bitdefender.pl/deepfakes-audio-jak-dziala-i-dlaczego-jest-niebezpieczny/.
[2] McGettigan, C., Bloch, S., Bowles, C., Dinkar, T., Lavan, N., Reus, J., & Rosi, V. (2024). Voice cloning: Psychological and ethical implications of intentionally synthesising familiar voice identities.
[3] Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 Laying down Harmonised Rules on Artificial Intelligence and Amending Regulations (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 and (EU) 2019/2144 and Directives 2014/90/EU, (EU) 2016/797 and (EU) 2020/1828 (Artificial Intelligence Act) (Text with EEA Relevance). 13 czerwiec 2024, http://data.europa.eu/eli/reg/2024/1689/oj/eng.
[4] „VALL-E”. Microsoft Research, https://www.microsoft.com/en-us/research/project/vall-e-x/. Dostęp 17 marzec 2025.
[5] „Tacotron 2”. PyTorch, https://pytorch.org/hub/nvidia_deeplearningexamples_tacotron2/. Dostęp 17 marzec 2025.
[6] „WaveNet: A Generative Model for Raw Audio”. Google DeepMind, 12 marzec 2025, https://deepmind.google/discover/blog/wavenet-a-generative-model-for-raw-audio/.
[7] https://artistrightsnow.medium.com/200-artists-urge-tech-platforms-stop-devaluing-music-559fb109bbac
[9] https://www.theguardian.com/technology/2024/apr/02/musicians-demand-protection-against-ai