Dnia 22.10.2024 słuchacze Off Radio Kraków mieli przyjemność posłuchać wywiadu z wybitną polską poetką na temat literackiej Nagrody Nobla 2024. Nie byłoby w tym nic dziwnego, gdyby nie fakt, że dziennikarka nie istnieje, a respondentka nie żyje już od ponad dekady.

Tło incydentu
Chcąc lepiej zrozumieć, jak doszło do tego incydentu, możemy się cofnąć do innego ważnego wydarzenia, mającego miejsce rok wcześniej. Pod koniec 2023 roku miały miejsce wybory parlamentarne w Polsce, na skutek których władzę przejął rząd Donalda Tuska (wina Tuska!).
Jednym z pierwszych działań nowego rządu było przyjęcie przez Sejm uchwały w sprawie przywrócenia ładu prawnego oraz bezstronności i rzetelności mediów publicznych oraz Polskiej Agencji Prasowej. I chociaż uchwała nie miała mocy prawnej, rozpoczęła proces zmian w zarządach mediów publicznych oraz ostatecznie postawiła je w stanie likwidacji.
W stan likwidacji postawione zostało między innymi Radio Kraków, które odpowiada za emisję stacji Off Radio Kraków. Na rolę likwidatora powołany został Mariusz Marcin Pulit, który wraz z przyjęciem stanowiska, zderzył się z problemami finansowymi tej instytucji. Przez następny rok sytuacja w Off Radio Kraków ewoluowała w sposób niewidoczny dla szerszej opinii publicznej, aż do dnia poprzedzającego incydent.
Dnia 21.10.2024 Off Radio Kraków przedstawiło nam nowych prowadzących: Emilię Nowak; studentkę dziennikarstwa, Jakuba Zielińskiego; studenta inżynierii akustycznej, oraz Alexa Szulca; byłego studenta psychologi. Pomijając młody wiek, tercet był dość konwencjonalny, poza jednym szczegółem: składał się on wyłącznie z postaci fikcyjnych wygenerowanych przez SI. Post na Facebooku, w którym dumnie zostało ogłoszone, że radio tworzone będzie przez SI, został zalany komentarzami krytyki. Krytyka na poście się nie skończyła, Pan Mateusz Demski, były pracownik Off Radio Kraków, napisał list otwarty, w którym porusza następujące problemy:
- Zwolnienie pracowników oraz zastąpienie ich przez SI
- Brak autentyczności i wrażliwości w programach prowadzonych przez SI
- Podważenie wartości społecznego zaangażowania
- Brak transparentności oraz podejmowanie przez likwidatora decyzji bez konsultacji
- Brak gwarancji jakości treści
W odpowiedzi Likwidator wystosował oświadczenie, w którym:
- Postuluje, że nikt nie został zwolniony. Osoby na UoP zostali przeniesieni do innych stacji, a kontraktorom po prostu wygasła umowa.
- Zmiany w radiu wynikają ze słabej słuchalności oraz pokryciem programowym z innymi stacjami.
- Prowadzenie radia przez SI jest jedynie eksperymentem, a jego trwanie zakończy się po 3 miesiącach.
Opinia publiczna opowiedziała się bardziej za Mateuszem, a Mariusz postawiony został w ogniu krytyki.
W takiej atmosferze doszło do tytułowego incydentu. Dnia 22.10.2024 fikcyjna dziennikarka Emilia przeprowadziła wywiad z nieżyjącą noblistka Wisławą Szymborską, ożywioną przy pomocy sztucznej inteligencji. Sama treść wywiadu nie była kontrowersyjna, to cyfrowe ożywienie wywołało kolejną falę krytyki. Najczęstszymi zarzutami były:
- Niedostateczne oznakowanie, że treść została wygenerowana przez SI
- Wykorzystanie wizerunku nieżyjącej pisarki bez jej zgody
Jednak jak się później okazało, Off Radio Kraków uzyskało wcześniej pozwolenie na wykorzystanie wizerunku noblistki. Udzielił go Michał Rusinek, sekretarz Wisławy Szymborskiej oraz prezes fundacji jej imienia, tłumacząc, że wywiad miał mieć charakter humorystyczny, oraz że poetce zapewne ten żart by się spodobał.
Pomimo wsparcia Michała ogrom kontrowersji nie zmalał. Zaledwie tydzień później Off Radio Kraków ogłosiło zakończenie eksperymentu, pisząc „Zakładaliśmy, że ten projekt potrwa maksymalnie trzy miesiące. Jednak już po tygodniu zebraliśmy tak wiele obserwacji, opinii, wniosków, że uznaliśmy, iż jego kontynuacja jest bezcelowa…”, choć mowa o powodzeniu eksperymentu wydaje się nieszczera, to problemy pojawiające się w trakcie eksperymentu są niewątpliwie warte uwagi.
Jerzy Stuhr i kultowy osioł
Niedługo po śmierci Jerzego Stuhra, która miała miejsce początkiem lipca 2024 roku, świat obiegła wiadomość o pracach nad powstaniem kolejnej części “Shreka”. Wraz z tą informacją pojawiły się pytania o przyszłość dubbingu animacji w polskiej wersji językowej, bowiem aktor ten był nierozerwalnie związany z postacią Osła, użyczając mu swojego głosu we wszystkich dotychczasowych częściach.

Naturalnie, powstało wiele spekulacji na temat tego, czy Osioł pozostanie przy swoim oryginalnym głosie, co miałoby być umożliwione dzięki wykorzystaniu sztucznej inteligencji. Okazuje się, że propozycję podkładania głosu pod jego postać otrzymał Maciej Stuhr – syn zmarłego Jerzego. Wiadomo jednak, że prawdopodobnie i tak Maciej wspomagany będzie sztuczną inteligencją, aby efekt końcowy był jak najbardziej podobny do charakterystycznego brzmienia postaci, natomiast jak na razie brak w sieci szczegółowych informacji o tym, jak pomoc sztucznej inteligencji ma wyglądać w tej kwestii.
Fani, jak to zwykle bywa, są podzieleni. Część widzów wyraża uznanie dla kontynuacji tradycji, natomiast inni obawiają się, że wykorzystanie AI może prowadzić do utraty autentyczności i emocjonalnej głębi, jaką wprowadzał Jerzy Stuhr.
Deepfake jako narzędzie propagandy

O ile przypadek dubbingu w filmie może powodować jakieś nieprzyjemne emocje, to jest on w gruncie rzeczy nieszkodliwy, a ewentualne wątpliwości są raczej natury estetycznej. Problem pojawia się w momencie, gdy narzędzia deepfake są wykorzystywane w celach politycznych, a wraz z rozwojem tej technologii namnaża się coraz więcej tego typu przypadków.
USA
W styczniu 2024 roku, tuż przed prawyborami Partii Demokratycznej w stanie New Hampshire, tysiące osób dostało telefony, w których głos brzmiący jak ówczesny prezydent Joe Biden zachęcał do nieuczestniczenia w stanowych prawyborach, jako że miałoby to odebrać wyborcom możliwość głosowania w powszechnych wyborach prezydenckich mających mieć miejsce w listopadzie. W rzeczywistości okazał się to deepfake mający na celu zniechęcenie do udziału w wyborach. Za organizację tej akcji odpowiedzalny jest Steve Kramer, konsultat polityczny, który, jak twierdzi, chciał zwrócić uwagę na potencjalne zagrożenia związane z wykorzystywaniem AI w polityce, a nie wpłynąć na wynik wyborów. Kramerowi postawiono łącznie ponad 13 zarzutów, w tym naruszenie przepisów dotyczących identyfikacji rozmówców, a Federalna Komisja Łączności (FCC) nałożyła na niego karę w wysokości 6 mln dolarów.
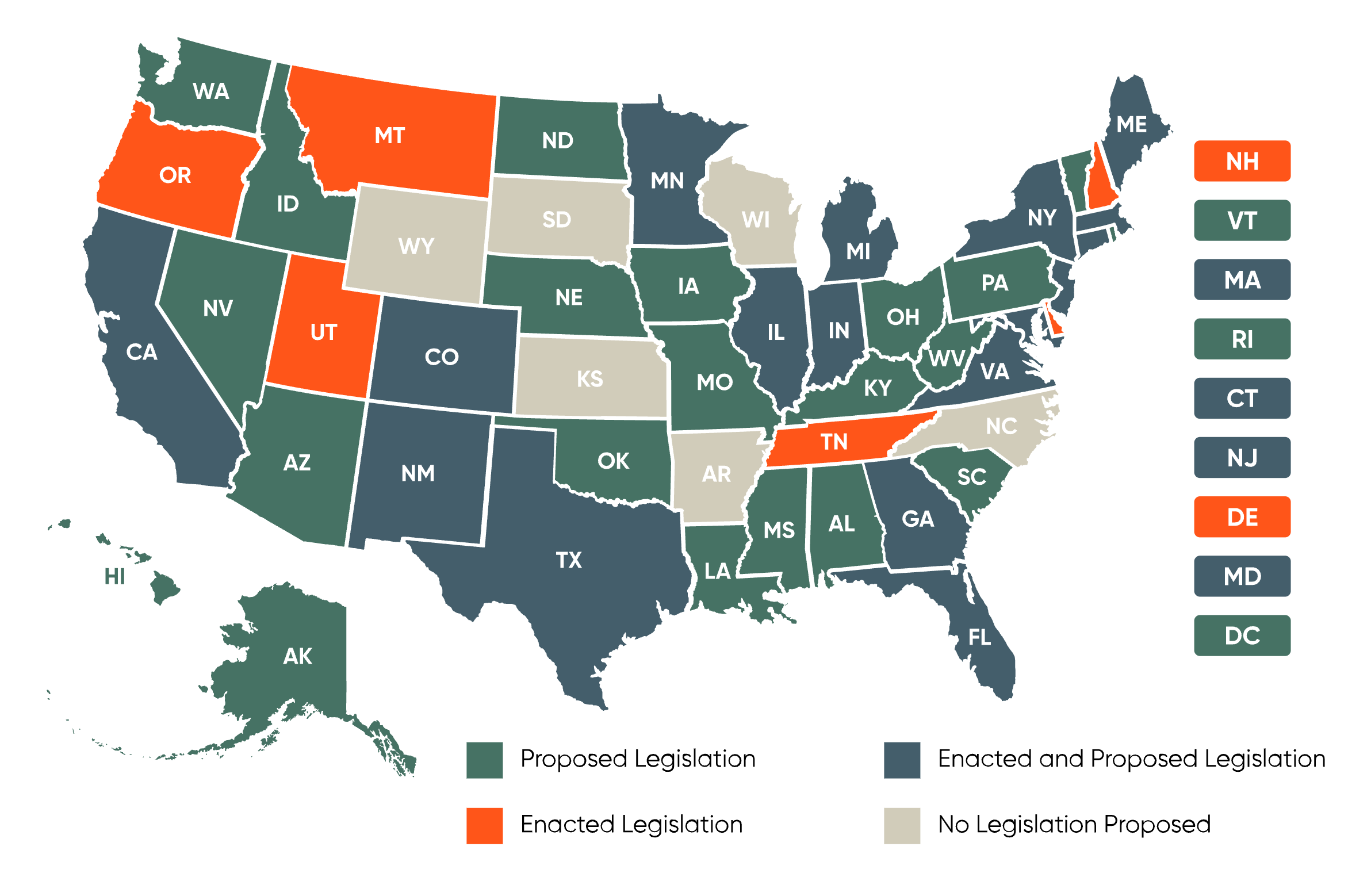
Incydent ten wywołał szeroką debatę na temat potrzeby wprowadzenia regulacji dotyczących wykorzystania AI w kampaniach wyborczych oraz ochrony integralności procesów demokratycznych. W lutym 2024 roku FCC uznała, że głosy generowane przez AI w robocallach są nielegalne na mocy ustawy Telephone Consumer Protection Act (TCPA). W lipcu 2024 roku FCC zaproponowała nowe przepisy wymagające ujawniania wykorzystania treści generowanych przez AI w reklamach politycznych emitowanych w radiu i telewizji, ale na ten moment jeszcze nie weszły one w życie. Z kolei wiele stanów, m.in. New Jersey, Tennessee oraz Kalifornia, rozpoczęło prace nad legislacją mającą na celu ograniczenie wykorzystania deepfake’ów w kontekście wyborczym.
Indie
W trakcie wyborów parlamentarnych w Indiach w 2024 roku wykorzystanie sztucznej inteligencji stanowiło lwią część kampanii, zarówno ze strony partii rządzącej, jak i opozycji. Na kilka miesięcy przed wyborami, premier Narendra Modi użył narzędzia “Bhashini” – opartego na sztucznej inteligencji systemu tłumaczenia, który miał pomóc porozumieć się z ludnością mówiącą w języku Tamil. Takie narzędzia wydają się mieć potencjał na wykorzystanie ich w szlachetnych celach, zwłaszcza w takich państwach jak Indie, gdzie oficjalnie uznawane są aż 22 języki.

Jednak jak można się domyślać, AI zostało w dużym stopniu wykorzystane do tworzenia deepfake’ów przedstawiających polityków w sfabrykowanych sytuacjach i okolicznościach, czego przykładem było wykorzystanie wizerunku Asaduddina Owaisiego, muzułmańskiego polityka, który rzekomo śpiewał religijne pieśni hinduistyczne – zabieg ten miał na celu zdyskredytowanie go w oczach elektoratu. Pojawiły się również fałszywe nagrania zmarłych liderów politycznych, którzy rzekomo wspierali kandydatów w bieżących wyborach. W ciągu dwóch miesięcy poprzedzających wybory, wykonano ponad 50 milionów automatycznych połączeń telefonicznych z wykorzystaniem klonowanych głosów polityków. W odpowiedzi na rosnące zagrożenie dezinformacją, powołano jednostkę Deepfakes Analysis Unit (DAU), która umożliwiała obywatelom zgłaszanie podejrzanych treści do analizy, jednak pomimo tych działań szacuje się, że ok. 75% indyjskich wyborców zostało narażonych na kontakt z treściami deepfake, z czego znaczna część odbiorców uznała je za autentyczne.
Sposoby przeciwdziałania problemom

Rosnąca obecność sztucznej inteligencji w tworzeniu treści dźwiękowych stawia ważne wyzwanie dotyczące ich odpowiedniego oznaczania. Brak jasnych i skutecznych metod identyfikacji materiałów generowanych przez AI może prowadzić do nieporozumień, naruszeń praw autorskich oraz utraty zaufania odbiorców.
Aby sprostać temu wyzwaniu, konieczne jest wdrożenie rozwiązań technicznych, które umożliwią transparentne oznaczanie takich treści, wsparte przez regulacje prawne oraz działania edukacyjne zwiększające świadomość społeczną. W kolejnych podsekcjach omówione zostaną możliwe kierunki działań w tych trzech obszarach.
Rozwiązania techniczne
Technologie rozpoznawania deepfake’ów dźwiękowych
Wraz z rosnącym wykorzystaniem sztucznej inteligencji do generowania realistycznych nagrań głosowych, rozwijane są również narzędzia pozwalające na wykrywanie deepfake’ów audio. Opierają się one na analizie specyficznych cech sygnału audio, które są trudne do idealnego odtworzenia przez modele generatywne. Są to m.in.:
- Anomalie akustyczne, nieregularności w częstotliwościach, barwie głosu, czy też charakterystycznych artefaktach, które pojawiają się w sztucznie generowanych nagraniach
- Analiza cech fonetycznych i prozodycznych, ocena naturalności intonacji, rytmu mowy oraz dynamiki głosu
- Wykorzystanie sieci neuronowych, modele uczone na dużych zbiorach danych potrafią wyłapywać wzorce wskazujące na sztuczne pochodzenie nagrania
Przykładowe narzędzia i projekty badawcze w tej dziedzinie to:
- PlayHT Voice Classifier, narzędzie służące do wykrywania głosów generowanych przez sztuczną inteligencję, uznawane za jedno z najbardziej zaawansowanych w tej kategorii. Wykorzystuje nowoczesne algorytmy uczenia maszynowego, które pozwalają na precyzyjne odróżnienie głosu ludzkiego od syntetycznego
- ASVspoof Challenge, coroczne konkursy i bazy danych, które skupiają się na opracowaniu najlepszych algorytmów wykrywania deepfake’ów audio
- Microsoft Azure Cognitive Services, usługi chmurowe oferujące narzędzia do analizy i detekcji syntetycznych nagrań głosowych
Choć technologia rozpoznawania deepfake’ów dźwiękowych dynamicznie się rozwija, nadal stoi przed wyzwaniami takimi jak skuteczność w przypadku wysokiej jakości nagrań generowanych przez najnowsze modele czy odporność na próby maskowania sygnatur deepfake.
Technologie znaków wodnych
Nie zawsze osoba generująca treść przez SI chce nas oszukać, audycja Off Radio Kraków również miała mieć charakter humorystyczny, niestety syntetyczny charakter nie zawsze jest oczywisty. Jednym ze sposobów oznaczenia takiej treści jest znak wodny (wartermark), umieszcza on informację w danej treści bez widocznego wpływu na samą treść.
Jednym z najpopularniejszych narzędzi do umieszczania znaków wodnych to SynthID. Stworzone przez Google DeepMind, pozwala osadzać cyfrowy znak wodny w wygenerowanych treściach, w sposób niewidoczny dla ludzkiego ucha, ale możliwy do odczytania przez system. Znak wodny ma być odporny na dodanie szumu czy przyspieszenie ścieżki.
Mówiąc o znakach wodnych warto wspomnieć o standardzie C2PA (Coalition for Content Provenance and Authenticity) opracowany przez m.in. Adobe, Microsoft i BBC. C2PA umożliwia osadzanie w treściach cyfrowych (w tym potencjalnie również audio) metadanych z informacją o pochodzeniu, autorze i technologii użytej do wygenerowania materiału. Choć jego implementacja w audio dopiero się rozwija, C2PA stanowi ważny krok w kierunku standaryzacji oznaczania treści.
Czy naprawdę potrzebujemy perfekcyjnych deepfake’ów?
W dyskusji o technologii syntetycznego głosu często przyjmuje się założenie, że celem powinno być osiągnięcie perfekcyjnego realizmu, głosu nie do odróżnienia od ludzkiego. Ale czy to naprawdę konieczne?
Warto przypomnieć sobie przykład Vocaloidów, które zdobyły ogromną popularność, mimo że ich brzmienie jest wyraźnie nienaturalne. Postaci takie jak Hatsune Miku stworzone zostały na podstawie głosu realnych ludzi, choć w starszych wersjach ciężko to wychwycić. Ich syntetyczność stała się częścią estetyki, tożsamości i fenomenu kulturowego.
To pokazuje, że głos generowany przez AI nie musi być idealną kopią ludzkiego, by być użyteczny, artystycznie interesujący czy emocjonalnie angażujący. W wielu kontekstach wystarczy, że brzmi „wystarczająco dobrze” i że odbiorca ma świadomość, z czym ma do czynienia.
Znaków wodnych nie słychać – są niewidoczne dla użytkownika. Tymczasem drobna syntetyczność głosu może pełnić rolę naturalnego wskaźnika, sygnalizując odbiorcy, że głos nie pochodzi od prawdziwego człowieka. Być może wcale nie powinniśmy ukrywać tej cechy, ale uczynić ją częścią estetyki i etyki korzystania z AI.
Rozwiązania prawne
Choć technologia daje nam dziś narzędzia pozwalające oznaczać treści generowane przez sztuczną inteligencję, takie jak znaki wodne czy metadane pochodzenia, samo ich istnienie nie rozwiązuje problemu. Kluczowe pytanie brzmi: kto i kiedy ma obowiązek ich używać?
Bez jasnych ram prawnych i mechanizmów egzekwowania, nawet najlepsze systemy oznaczania mogą pozostać martwe. Praktyka pokazuje, że wiele firm i użytkowników z wygody, niewiedzy lub celowego działania pomija informowanie odbiorców o tym, że mają do czynienia z treścią syntetyczną. Dlatego to nie tylko kwestia dostępnych rozwiązań technicznych, ale też regulacji, które zmuszą do ich stosowania i zapewnią przejrzystość w przestrzeni publicznej.
AI Act, przyjęty przez Unię Europejską, wprowadza obowiązki dotyczące przejrzystości w kontekście treści generowanych przez sztuczną inteligencję. Artykuł 50 tego aktu nakłada na dostawców systemów sztucznej inteligencji obowiązek informowania użytkowników, że dana treść została wygenerowana przez AI, chyba że jest to część procedury legalnej lub wykrywania przestępstw. Naruszenie tych obowiązków może skutkować karami finansowymi, sięgającymi nawet 15 milionów euro lub 3% rocznego obrotu globalnego przedsiębiorstwa, w zależności od tego, która kwota jest wyższa. Niestety sposób oznaczanie nie został sprecyzowany.
Providers shall ensure that AI systems intended to interact directly with natural persons are designed and developed in such a way that the natural persons concerned are informed that they are interacting with an AI system, unless this is obvious from the point of view of a natural person who is reasonably well-informed, observant and circumspect, taking into account the circumstances and the context of use. This obligation shall not apply to AI systems authorised by law to detect, prevent, investigate or prosecute criminal offences, subject to appropriate safeguards for the rights and freedoms of third parties, unless those systems are available for the public to report a criminal offence.
PL:
Dostawcy zapewniają, aby systemy AI przeznaczone do bezpośredniej interakcji z osobami fizycznymi były projektowane i rozwijane w taki sposób, aby zainteresowane osoby fizyczne były informowane, że wchodzą w interakcję z systemem AI, chyba że jest to oczywiste z punktu widzenia osoby fizycznej, która jest dostatecznie dobrze poinformowana, uważna i ostrożna, biorąc pod uwagę okoliczności i kontekst użytkowania. Obowiązek ten nie ma zastosowania do systemów sztucznej inteligencji uprawnionych na mocy prawa do wykrywania przestępstw, zapobiegania im, prowadzenia dochodzeń w ich sprawie lub ich ścigania, z zastrzeżeniem odpowiednich zabezpieczeń praw i wolności osób trzecich, chyba że systemy te są publicznie dostępne w celu zgłoszenia przestępstwa.
W Stanach Zjednoczonych kwestia oznaczania treści generowanych przez AI jest regulowana na poziomie stanowym. Na przykład, w Kalifornii uchwalono prawo zakazujące używania zmanipulowanych treści w kontekście wyborczym bez wyraźnego oznaczenia. Ponadto, w Nowym Jersey wprowadzono przepisy penalizujące tworzenie i rozpowszechnianie wprowadzających w błąd treści generowanych przez AI, znanych jako deepfake’i.
Na poziomie federalnym, projekt ustawy No AI FRAUD Act proponuje wprowadzenie obowiązku ujawniania, że treść została wygenerowana przez AI, oraz wprowadzenie sankcji za nieautoryzowane użycie głosu i wizerunku osób.
Edukacja – uzupełnienie dla technologii i prawa
Choć kluczową rolę w zapewnianiu przejrzystości treści generowanych przez AI odgrywają regulacje prawne i rozwiązania techniczne, świadomość społeczna również ma znaczenie. Bez niej nawet najlepsze oznaczenia mogą zostać zignorowane, a odbiorcy nie będą w stanie rozpoznać, że mają do czynienia z syntetycznym głosem lub zmanipulowanym komunikatem. Dlatego edukacja powinna być traktowana jako trzecia, wspierająca oś działań w obszarze ochrony odbiorców.
Nie chodzi tu o zaawansowaną wiedzę technologiczną. Wystarczą podstawowe kompetencje medialne, takie jak umiejętność zadania sobie pytania o pochodzenie treści, rozróżnienia faktu od fikcji czy odczytania sygnałów ostrzegawczych, w tym oznaczeń informujących o użyciu AI. Te umiejętności mogą być rozwijane już na poziomie edukacji szkolnej, w ramach zajęć z informatyki, języka polskiego czy wiedzy o społeczeństwie.
Przykładem może być Finlandia, która w 2025 roku planuje pełne wdrożenie oficjalnych wytycznych dotyczących wykorzystania sztucznej inteligencji w edukacji. Dokument ten podkreśla, że technologia powinna wspierać – a nie zastępować – ludzki konktakt w klasie. Wytyczne kładą nacisk na przejrzystość działania algorytmów, odpowiedzialność za ich użycie oraz równość dostępu. Uczenie o AI już od najmłodszych lat pomaga dzieciom rozumieć, jak działa technologia i jak odróżniać treści autentyczne od generowanych sztucznie. Badania z fińskich szkół pokazują, że takie podejście przekłada się nie tylko na większą świadomość uczniów, ale też na wzrost wyników w nauce i zaangażowania – odpowiednio o 25% i 30%.

Równie istotne są kampanie informacyjne i działania medialne, które w przystępny sposób tłumaczą działanie syntetycznych głosów i sens ich oznaczania. Krótkie komunikaty w radiu, podcastach czy mediach społecznościowych, w stylu „Ten materiał zawiera treści stworzone przez AI”, nie tylko spełniają wymogi prawa, ale mogą też pełnić funkcję edukacyjną, oswajając odbiorców z nowymi zjawiskami.
Edukacja nie zastąpi przepisów ani technologii, ale może pomóc je zakorzenić w praktyce społecznej. W kontekście dynamicznego rozwoju narzędzi generatywnych budowanie świadomego odbiorcy staje się nie tylko kwestią kultury medialnej, ale również odporności społecznej na manipulację.
Co na ten temat mówią twórcy?
Twórcy działający w różnych dziedzinach mają w zasadzie dosyć podobne i raczej ostrożne podejście do wykorzystywania technologii AI w generowaniu treści. W wywiadzie dla “The New York Times” Tom Hanks podkreślił, jak ważne są regulacje prawne, po tym, jak jego wizerunek został wykorzystany w reklamie bez jego zgody.
There are multiple ads over the internet falsely using my name, likeness and voice promoting miracle cures and wonder drugs. These ads have been created without my consent, fraudulently and through AI, I have nothing to do with these posts or the productions and treatments, or the spokespeople touting these cures, have type 2 diabetes, and I ONLY work with my board certified doctor regarding my treatment. DO NOT BE FOOLED. DO NOT BE SWINDLED. DO NOT LOSE YOUR HARD EARNED MONEY.
PL:
W Internecie jest wiele reklam fałszywie wykorzystujących moje imię, podobieństwo i głos promujących cudowne lekarstwa i cudowne leki. Reklamy te zostały stworzone bez mojej zgody, nieuczciwie i za pośrednictwem sztucznej inteligencji, nie mam nic wspólnego z tymi postami, produkcjami i zabiegami, ani rzecznikami reklamującymi te leki, mam cukrzycę typu 2 i pracuję TYLKO z moim certyfikowanym lekarzem w zakresie mojego leczenia. NIE DAJ SIĘ OSZUKAĆ. NIE DAJ SIĘ NABRAĆ. NIE TRAĆ SWOICH CIĘŻKO ZAROBIONYCH PIENIĘDZY.
— Tom Hanks
Z podobną sytuacją mierzyła się aktorka Scarlett Johansson, gdy powstał deepfake’owy filmik, w którym Johansson i inne gwiazdy, w tym David Schwimmer i Jerry Seinfeld, zostały przedstawione w białej koszulce przedstawiającej Gwiazdę Dawida na dłoni salutującej jednym palcem, nad słowem „Kanye”. Filmik ten miał być odpowiedzią na serię antysemickich postów Kanye’go Westa na platformie X. Aktorka podkreśliła, że takie działania są nieetyczne i mogą poważnie zaszkodzić reputacji osób publicznych. Zwróciła także uwagę na potrzebę wprowadzenia regulacji prawnych chroniących przed nieautoryzowanym wykorzystaniem wizerunku.
It has been brought to my attention by family members and friends, that an A.I.-generated video featuring my likeness, in response to an antisemitic view, has been circulating online and gaining traction. I am a Jewish woman who has no tolerance for antisemitism or hate speech of any kind. But I also firmly believe that the potential for hate speech multiplied by A.I. is a far greater threat than any one person who takes accountability for it. We must call out the misuse of A.I., no matter its messaging, or we risk losing a hold on reality.
PL:
Członkowie mojej rodziny i przyjaciele zwrócili moją uwagę na to, że w Internecie krąży i zyskuje na popularności wideo wygenerowane przez sztuczną inteligencję, w którym pojawia się moja podobizna w odpowiedzi na antysemickie poglądy. Jestem Żydówką, która nie toleruje antysemityzmu ani mowy nienawiści jakiegokolwiek rodzaju. Ale jestem również głęboko przekonana, że potencjał mowy nienawiści pomnożony przez sztuczną inteligencję jest znacznie większym zagrożeniem niż jakakolwiek osoba, która bierze za nią odpowiedzialność. Musimy zwracać uwagę na niewłaściwe wykorzystanie sztucznej inteligencji, niezależnie od jej przekazu, w przeciwnym razie ryzykujemy utratę kontroli nad rzeczywistością.
— Scarlett Johansson
Podobne obawy wyrażają nie tylko gwiazdy, ale też naukowcy, np. Don Fallis – profesor filozofii i informatyki – który zwraca uwagę na epistemologiczne[1] zagrożenie związane z deepfake’ami. Podkreślił, że takie technologie mogą prowadzić do dezinformacji, utrudniając ludziom odróżnienie prawdy od fałszu oraz zaznaczył, że w świecie przepełnionym informacjami, deepfake’i stanowią poważne wyzwanie dla społeczeństw demokratycznych.
[1] Epistemologia- dział filozofii zajmujący się procesami poznawania, bada jak poznajemy rzeczywistość, jakie są źródła wiedzy i jak jest ona uzasadniana (badanie pojęcia prawdziwości)
Źródła
- https://www.petycjeonline.com/apel_rodowiska_kultury_i_mediow_w_sprawie_sytuacji_w_off_radiu_krakow_i_zastpienia_pracownikow_sztuczn_inteligencj
- https://businessinsider.com.pl/prawo/czy-uchwala-sejmu-w-sprawie-tvp-ma-znaczenie-prawne-prawnicy-nie-maja-watpliwosci/vrsw2nd – moc prawna ustawy
- https://www.radiokrakow.pl/aktualnosci/krakow/mariusz-marcin-pulit-likwidatorem-radia-krakow/
- https://oko.press/off-radio-krakow-zamiast-dziennikarzy-ai
- https://party.pl/newsy/off-radio-krakow-konczy-eksperyment-z-ai-jest-oswiadczenie/
- https://off.radiokrakow.pl/
- https://lubimyczytac.pl/aktualnosci/21153/off-radio-krakow-ai-wygenerowalo-rozmowe-z-szymborska-w-sieci-zawrzalo
- https://wiez.pl/2024/10/23/szymborska-z-czatbota-i-nieczuly-narrator/
- https://wydarzenia.interia.pl/malopolskie/news-burza-wokol-radia-krakow-sztuczna-inteligencja-porozmawiala,nId,7841162
- https://www.polityka.pl/tygodnikpolityka/kultura/2275743,1,tego-sie-nie-robi-botom-off-radio-krakow-odpytuje-szymborska-nieciekawy-ten-projekt-ai.read
- https://pl.wikipedia.org/wiki/Wybory_parlamentarne_w_Polsce_w_2023_roku#Wyniki_wybor%C3%B3w_do_Senatu_RP
- https://www.reddit.com/r/Polska/comments/1g9fbi0/ai_zast%C4%85pi%C5%82o_prowadz%C4%85cych_w_off_radiu_w_krakowie/
- https://x.com/dziennikarz/status/1848713218614501827
- https://tvn24.pl/krakow/radio-krakow-likwidator-marcin-pulit-o-dziurze-budzetowej-pracownicy-o-zmianach-w-rozglosni-st7759338
- https://play.ht/blog/how-to-detect-an-ai-voice/
- https://apnews.com/article/new-jersey-deepfake-videos-criminal-civil-penalties-276ca23b00b10a7ee7e7303ead8b4260
- https://www.congress.gov/bill/118th-congress/house-bill/6943/text
- https://jedynka.polskieradio.pl/artykul/3508700,Shrek-5-Wiadomo-kto-zast%C4%85pi-Jerzego-Stuhra-w-roli-Os%C5%82a
- https://rozrywka.spidersweb.pl/osiol-shrek-5-dubbing-kto-maciej-stuhr-sztuczna-inteligencja
- https://www.theguardian.com/technology/article/2024/aug/22/fake-biden-robocalls-fine-lingo-telecom
- https://www.reuters.com/world/us/fcc-finalizes-6-million-fine-over-ai-generated-biden-robocalls-2024-09-26
- https://www.npr.org/2024/12/21/nx-s1-5220301/deepfakes-memes-artificial-intelligence-elections
- https://economictimes.indiatimes.com/tech/technology/75-indians-have-viewed-some-deepfake-content-in-last-12-months-says-mcafee-survey/articleshow/109599811.cms?from=mdr
- https://www.livemint.com/technology/tech-news/deepfake-pm-rahul-gandhi-and-50-million-robocalls-ai-influence-on-lok-sabha-election-2024-campaign-revealed-11744561921605.html
- https://www.weforum.org/stories/2024/08/deepfakes-india-tackling-ai-generated-misinformation-elections/
- https://blackbird.ai/blog/india-election-deepfakes/
- https://www.nytimes.com/2023/10/02/technology/tom-hanks-ai-dental-video.html
- https://news.northeastern.edu/2024/02/12/magazine/ai-deepfake-images-online-deception/
- https://www.bbc.com/news/articles/c0qwkdlxgxno
- https://theaitrack.com/ai-in-finland-education-global-model/
W 2023 nastąpiło też ,,ożywienie” Boczka i Paździocha (za zgodą rodziny) w specjalnym odcinku ,,Świata według Kiepskich”: https://www.polsat.pl/news/2023-03-20/swiat-wedlug-kiepskich-zobacz-odcinek-specjalny/
Niestety, wyszło to dość słabo 🙁