 źródło: https://www.forbes.com/sites/forbestechcouncil/2020/11/09/how-to-keep-your-data-secure-in-the-cloud/
źródło: https://www.forbes.com/sites/forbestechcouncil/2020/11/09/how-to-keep-your-data-secure-in-the-cloud/
Etyka i sztuczna inteligencja to dwa terminy, które w coraz większym stopniu przecinają się w rozmowach i debatach na temat przyszłości technologii. Szczególnie ważna staje się ta kwestia w kontekście roli jaką odgrywają specjaliści od danych, czyli Data Scientist, w procesie tworzenia i wdrażania rozwiązań opartych na AI. W tej roli przestrzeganie pewnego kodeksu honorowego ma kluczowe znaczenie. W tym artykule przyjrzymy się, jakie zasady powinien przestrzegać Data Scientist, aby chronić dane, bezpiecznie je analizować, a jednocześnie rozpoznawać te, których nie powinno się przetwarzać.
Rola etyki w pracy Data Scientista
Data Scientist jako strażnik danych
Mając na względzie specyfikę pracy specjalisty od danych na stanowisku Data Scientist, można z dużą dozą pewności stwierdzić, iż pełni on dodatkową rolę strażnika danych, pracując z obecnie jednym z najcenniejszych zasobów w organizacjach. Etyka odgrywa istotną rolę w zakresie uzyskania intuicji, w jaki sposób przetwarzać dane, aby nie dopuszczać do naruszeń, mogących być krzywdzącymi dla jednostek bądź większych grup użytkowników. Etyczne przetwarzanie danych ma na celu przede wszystkim ochronę prywatności i poufnych informacji – dane medyczne bądź dane finansowe. Ponadto, nieetyczne oraz niestaranne przetwarzanie danych może prowadzić do nierówności bądź dyskryminacji systemów na nich bazujących. Data Scientist musi działać w sposób sprawiedliwy i dbać o to, aby procesy analizy danych a także finalne decyzje podejmowane przez systemy SI były wolne od uprzedzeń czy stronniczości. Przestrzeganie norm i zasad etycznych pozwala bowiem budować rozwiązania mogące uzyskać wiarygodność i zaufanie użytkowników, brak podejrzeń bądź zarzutów co do manipulacji danymi. W tym zakresie, Data Scientist jako strażnik danych ponosi społeczną odpowiedzialność za proces.
Data Governance
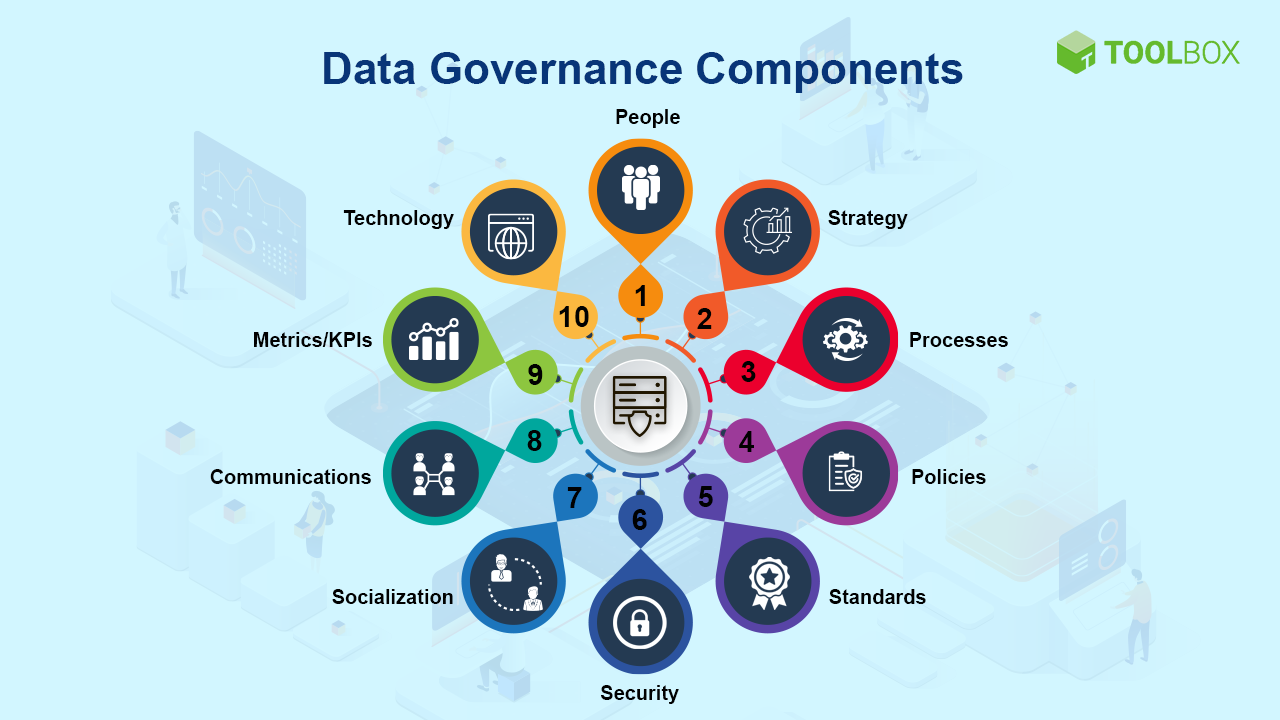 źródło: https://www.spiceworks.com/tech/big-data/articles/best-data-governance-tools/
źródło: https://www.spiceworks.com/tech/big-data/articles/best-data-governance-tools/
Data governance to zbiór zasad, polityk, procedur i rekomendowanych praktyk dotyczących sposobów zarządzania danymi w organizacji [1]. W uproszczeniu, obejmuje ono zazwyczaj długoterminową strategię, strukturę organizacyjną, procesy i mechanizmy, które mają na celu zapewnienie odpowiedniego gromadzenia, zarządzania, ochrony i wykorzystywania danych w sposób zgodny z przepisami i celami biznesowymi. Zbiór tych praktyk, jeśli zdefiniowany w organizacji, powinien niejako stanowić naturalne źródło informacji, celem rozwiania wątpliwości w zakresie etyki wykorzystania danych. Istotnym komponentem Data Governance, jest ustalenie struktury organizacyjnej i hierarchii/kultury odpowiedzialności za zarządzanie danymi, gdzie stanowisko Data Scientist stanowi kluczową rolę. Od strony praktycznej, w rolę komponentów zalicza się definiowanie standardów jakościowych i zasad transformacji danych, określanie zasad bezpieczeństwa i ochrony danych a także monitorowanie i audyt działań związanych z danymi. Niestety, w wielu organizacja Data Governance nadal uchodzi za proses silnie poboczny, mało atrakcyjny, wobec tego indywidualna świadomość i dobre praktyki stosowane przez specjalistów w dziedzinie przyczyniają się w zakresie zdefiniowania kodeksu honorowego.
Bezpieczne przetwarzanie i analiza danych
Bezpieczne przetwarzanie danych, które stanowi kluczowy element ochrony prywatności i bezpieczeństwa informacji, opiera się na różnorodnych zasadach i wytycznych określonych między innymi przez Rozporządzenie Ogólne o Ochronie Danych Osobowych (RODO). W sytuacji, gdy w organizacji nie jest zdefiniowana polityka Data Governance, regulacje prawne stają się punktem odniesienia głównie w zakresie bezpieczeństwa pozyskiwania i przetwarzania danych. Kodeks honorowy Data Scientistów powinien bezwątpienia uwzględniać następujące zasady [4]:
- Zasada zgodności z prawem, przejrzystości i rzetelności: Osoby, których dane są przetwarzane, powinny być poinformowane o celach, zakresie i sposobach przetwarzania ich danych osobowych. Informacje te powinny być łatwo dostępne i zrozumiałe.
- Zasada ograniczenia celu: Dane osobowe powinny być zbierane i przetwarzane tylko w celach określonych, jasno zdefiniowanych i zgodnych z prawem. Przetwarzanie danych powinno odbywać się tylko w celu, dla którego zostały zebrane.
- Zasada minimalizacji danych: Przetwarzanie danych powinno być ograniczone do minimum niezbędnego do osiągnięcia określonego celu. Nie należy zbierać ani przechowywać zbędnych danych.
- Zasada prawidłowości danych: Dane osobowe powinny być dokładne, kompleksowe i aktualne. Należy podjąć odpowiednie środki, aby zapewnić, że przechowywane dane są poprawne i aktualne.
- Zasada ograniczenia przechowywania danych: Dane osobowe powinny być przechowywane tylko przez okres niezbędny do osiągnięcia celu przetwarzania. Po upływie tego okresu dane powinny być usunięte lub zanonimizowane.
- Zasada integralności i poufności danych: Należy podjąć odpowiednie środki techniczne i organizacyjne, aby zapewnić bezpieczeństwo danych i ochronę przed nieautoryzowanym dostępem, utratą, uszkodzeniem lub nieuprawnionym ujawnieniem. Dostęp do danych powinien być ograniczony tylko do upoważnionych osób.
- Zasada rozliczalności: Podmiot przetwarzający dane osobowe powinien ponosić odpowiedzialność za przestrzeganie zasad ochrony danych i podejmować odpowiednie środki, aby zapewnić ich przestrzeganie. Należy przeprowadzać regularne audyty i monitorować zgodność z przepisami dotyczącymi ochrony danych.
Techniki bezpiecznego przetwarzania danych
Świadomość bezpiecznego przetwarzania danych stanowi teoretyczną podstawę kodeksu honorowego. Jednakże, istnieje szereg technik mających praktyczne zastosowanie w zgodzie z uprzednio zdefiniowanymi zasadami. W obszarach takich jak Data Science wykorzystywanie danych do wyciągania wartościowych wniosków i tworzenia innowacyjnych rozwiązań staje się nieodłączną częścią strategii sukcesu. Jednakże, wraz z rosnącą ilością danych, pojawiają się również nowe wyzwania związane między innymi z ochroną prywatności, bezpieczeństwem informacji oraz przestrzeganiem odpowiednich przepisów i regulacji. W tym kontekście, techniki bezpiecznego przetwarzania danych nabierają szczególnego znaczenia. Istnieje coraz większe zapotrzebowanie na innowacyjne metody, które nie tylko umożliwiają efektywne wykorzystanie danych, ale także gwarantują, że prywatność użytkowników i poufność informacji są w pełni chronione.
Jedną z powszechnie stosowanych technik, które cieszą się rosnącym zainteresowaniem, jest uczenie federacyjne. Ta innowacyjna metoda pozwala na trenowanie modeli na rozproszonych zbiorach danych, bez konieczności przekazywania samych danych do centralnego serwera. W ramach uczenia federacyjnego modele są wysyłane do lokalnych źródeł danych, gdzie uczą się na swoich własnych zbiorach informacji. Następnie, zaktualizowane modele są przekazywane do centralnego serwera, który agreguje te modele i tworzy globalny model. Dzięki temu podejściu dane pozostają na swoim pierwotnym miejscu, minimalizując ryzyko nieuprawnionego dostępu i naruszenia prywatności.
Inną z powszechnie wykorzystywanych metod, które można zastosować w celu zabezpieczenia danych, jest anonimizacja danych. Anonimizacja danych to proces przekształcenia danych osobowych w sposób uniemożliwiający przyporządkowanie poszczególnych informacji do określonej lub możliwej do zidentyfikowania osoby fizycznej. Anonimizacja jest procesem, który umożliwia trwałe rozłączenie danych osobowych z konkretną osobą, do której się odnoszą [5]. Dzięki temu, dane, które wcześniej były uważane za dane osobowe, tracą tę cechę i stają się całkowicie niepowiązanymi zidentyfikowanymi informacjami. Istnieje szereg różnych metod anonimizacji danych, takich jak generalizacja, randomizacja czy agregacja danych.
Szyfrowanie jest kolejną z technik, która może być stosowana do ochrony danych podczas przechowywania, przesyłania i przetwarzania. Polega na przekształceniu czytelnych danych w format nieczytelny i niezrozumiały dla osób nieupoważnionych. Proces szyfrowania wykorzystuje specjalne algorytmy i klucze, które zmieniają dane w postać zaszyfrowaną. Tylko osoby posiadające odpowiedni klucz mogą odczytać dane i przywrócić je do pierwotnej formy. Szyfrowanie zapewnia nie tylko poufność danych, ale także ochronę przed nieautoryzowanym dostępem, kradzieżą danych i nadużyciami. Mając na względzie kryptografie, należy zadbać o bezpieczny proces wymiany oraz pozyskiwania kluczy szyfrujących.
 Różnica między maskowaniem a szyfrowaniem danych (źródło: https://www.k2view.com/blog/data-masking-vs-encryption)
Różnica między maskowaniem a szyfrowaniem danych (źródło: https://www.k2view.com/blog/data-masking-vs-encryption)
W systemach ochrony danych istnieją trzy kluczowe elementy, które są wzajemnie powiązane i odgrywają istotną rolę. Są nimi uwierzytelnianie, autoryzacja i kontrola dostępu, często oznaczane skrótem AAA z angielskich słów: Authentication, Authorization i Accounting [6].
Uwierzytelnianie odnosi się do procesu weryfikacji tożsamości użytkownika lub systemu, który chce uzyskać dostęp do określonych zasobów. W tym procesie użytkownik dostarcza dane uwierzytelniające, takie jak login i hasło, karta dostępu, odcisk palca lub inne czynniki, które pozwalają potwierdzić, że dana osoba jest tym, za kogo się podaje.
Autoryzacja jest kolejnym krokiem po uwierzytelnianiu. Polega na przyznawaniu uprawnień lub dostępu do określonych zasobów lub funkcjonalności w systemie w oparciu o zdefiniowane reguły. Autoryzacja określa, jakie czynności użytkownik może wykonać po pomyślnym uwierzytelnieniu. Może obejmować zezwolenie na odczyt, zapis, modyfikację lub usuwanie danych, dostęp do określonych funkcji aplikacji lub dostęp do specyficznych obszarów systemu.
Kontrola dostępu to proces zarządzania dostępem do zasobów systemu. Obejmuje zarządzanie uprawnieniami użytkowników lub ról, tworzenie reguł i polityk, które określają, kto ma dostęp do określonych zasobów, jakie czynności mogą być podejmowane, oraz jakie warunki muszą być spełnione. Kontrola dostępu pozwala na monitorowanie, ograniczanie i rejestrowanie działań użytkowników w systemie w celu zapewnienia bezpieczeństwa i ochrony danych. Wobec tego, kodeks honorowy Data Scientistów powinien zawierać dobre praktyki wytwarzania oprogramowania, w zakresie projektowania rozwiązań bezpiecznych, dostosowanych do aktualnych norm w zakresie przechowywania danych, w zabezpieczeniu przed ich utratą bądź niepowołanym dostępem.
Kodeks honorowy Data Scientist
Zasada pierwsza: Prywatność przede wszystkim
Prywatność to jedna z podstawowych zasad, które każdy Data Scientist powinien przestrzegać. Należy więc chronić dane osobowe, które są nam powierzone, i zawsze uzyskać zgodę na ich wykorzystanie. Źródło danych powinno być dobrze udokumentowane. Przykładem realizacji tej zasady może być wykorzystanie technik anonimizacji danych, celem uniknięcia łatwego powiązania danych z konkretną osobą przez niepożądane podmioty. Na tym etapie, koniecznym jest pozostanie w pełnej zgodności z regulacjami takimi jak RODO. Wypracowanie lokalnych bądź globalnych polityk w tym zakresie, powinno pozwalać na elastyczne zarządzanie danymi, szczególnie w sytuacji gdy użytkownicy wystosują prośbę o usunięcie ich danych z bazy.
Zasada druga: Transparentność w działaniu
Data Scientist powinien zawsze dążyć do pełnej transparentności w swojej pracy. To oznacza, że powinien jasno komunikować, jakie dane są zbierane, jak są przetwarzane i do jakich celów są używane. Transparentność jest również kluczowa w kontekście modeli AI, które tworzymy. Powinniśmy być w stanie wyjaśnić, jak nasze modele działają i na jakich danych zostały wytrenowane, co jest szczególnie ważne w kontekście tzw. czarnych skrzynek, gdzie proces decyzyjny modelu może być niejasny. Istotny wpływ ma XAI czyli eXplainable AI, a więc zbiór technik pozwalających na wyjaśnienie powodu, dla którego model podjął taką a nie inną decyzję. Warto również mieć na względzie, iż zasada ta obejmuje staranny dobór narzędzi ściśle do typu przetwarzanych danych (walidacja krzyżowa dla szeregów czasowych).
Zasada trzecia: Zgodność z dobrymi praktykami wytwarzania oprogramowania
Projektowane aplikacje bądź serwisy powinny spełniać aktualne normy w zakresie bezpieczeństwa przechowywanych danych. Istotnym jest więc zachowanie zgodności co do dobrych praktyk wytwarzania oprogramowania.
Zasada czwarta: Równość i brak dyskryminacji
Data Scientist powinien rozważać skutki społeczne i środowiskowe swoich działań. Powinien działać w sposób, który przyczynia się do dobra społeczeństwa i środowiska, unikając szkody czy nadużyć. Procesy trenowania i utrzymania modeli SI powinny przebiegać w szczególnej staranności, aby zapobiegać tworzeniu rozwiązań, których werdykty byłyby w jakiś sposób nieprawidłowe, niesprawiedliwe bądź krzywdzące. Data Scientist, powinien dodatkowo stosować czytelną i jasno określoną metodologię (szczególnie, uwzględniającą adaptacje rozwiązań AI do danych, których charakterystyka/dystrybucja może ulegać zmianie) weryfikacji modeli SI, unikając manipulacji wyników czy prezentowania informacji w sposób dezinformujący.
Kiedy nie dotykać danych?
Niezależnie od tego, jak atrakcyjne mogą wydawać się dane, istnieją sytuacje, w których Data Scientist powinien odmówić ich wykorzystania. Do tych sytuacji należą:
- Dane bez zgody: Jeżeli brakuje wyraźnej zgody na przetwarzanie danych, nie powinno się ich dotykać. Zasada ta ma zastosowanie zarówno do danych osobowych, jak i do danych z innych źródeł. Bez odpowiedniej zgody i prawnej podstawy przetwarzanie danych byłoby naruszeniem prywatności i etyki.
- Dane wrażliwe: Niektóre dane są szczególnie wrażliwe, np. dane dotyczące zdrowia, orientacji seksualnej, przekonań religijnych czy politycznych. Przetwarzanie takich danych bez odpowiednich środków ochrony może prowadzić do poważnych naruszeń prywatności. Data Scientist powinien mieć świadomość, że istnieją specjalne regulacje i wymagania dotyczące przetwarzania tych danych oraz zastosować odpowiednie środki ochrony, takie jak anonimizacja.
- Dane z nielegalnych źródeł: Jeżeli dane pochodzą z nielegalnych źródeł, nie powinno się ich używać. Przestrzeganie tej zasady jest kluczowe dla utrzymania wysokich standardów etycznych w branży Data Science. Korzystanie z nielegalnie pozyskanych danych może prowadzić do poważnych konsekwencji prawnych i naruszeń zasad etycznych.
Podsumowując, z pracą Data Scientisty wiąże się duża odpowiedzialność. Przestrzeganie kodeksu honorowego jest nie tylko kwestią etyki, ale również kluczem do budowania zaufania do naszej pracy i technologii, które tworzymy. Istotną rolę odgrywają klarownie zdefiniowane zasady Data Governance w organizacjach, które niestety często pozostają drugoplanowe. Wobec tego, pozyskując, przetwarzając bądź przechowując dane, należy mieć na względzie wszelkie obowiązujące regulacje takie jak RODO.
Literatura
- Data Governance: Organizing data for trustworthy Artificial Intelligence; Marijn Janssen, Paul Brous, Elsa Estevez, Luis S. Barbosa, Tomasz Janowski; https://doi.org/10.1016/j.giq.2020.101493
- https://rkrodo.pl/minimalizacja-danych-rodo/
- https://odo24.pl/rodo-uodo/zasady-przetwarzania-danych-osobowych/
- https://www.apexnet.com.pl/blog/newsy-prawne/7-zasad-przetwarzania-danych-wedlug-rodo/
- https://pl.wikipedia.org/wiki/Anonimizacja_danych
- https://www.computerworld.pl/news/AAA-uwierzytelnianie-autoryzacja-i-kontrola-dostepu-cz-1,374709.html