W dzisiejszym świecie rozwój sztucznej inteligencji zdaje się nie mieć granic. Dezinformacja, plagiat i treści generowane przez SI stają się coraz większym wyzwaniem dla społeczeństwa. Eksperci ostrzegają, że dezinformacja stanowi największe zagrożenie technologiczne dla ludzkości w najbliższych latach. Choć technologia SI może być narzędziem do tworzenia, to również staje się podstawowym narzędziem szerzenia nieprawdziwych informacji. Jak zatem radzić sobie z tym problemem?
W niniejszym artykule omówimy perspektywy identyfikowania treści generowanych przez SI oraz możliwości i ograniczenia, jakie te technologie niosą dla społeczeństwa. Zastanowimy się, czy dalszy rozwój narzędzi do weryfikacji może być krokiem w dobrym kierunku oraz czy regulacje i narzędzia weryfikacyjne nadążą za rosnącym potencjałem SI.
Kto jest autorem dezinformacji?
W erze cyfryzacji szybki przepływ informacji umożliwia łatwe rozprzestrzenianie się nieprawdziwych treści. Celowe rozpowszechnianie nieprawdy w celu wprowadzenia innych w błąd czy manipulowanie opinią publiczną to aspekty zjawiska dezinformacji. Według raportu Global Risks Report 2024 wydanego w styczniu tego roku przez World Economic Forum, dezinformacja jest na pierwszym miejscu zagrożeń technologicznych czekających ludzkość w najbliższych dwóch latach. Pozycja ta zaliczyła awans w tym niechlubnym rankingu o 15 miejsc i jest to bezpośredni efekt rozwoju narzędzi związanych ze sztuczną inteligencją. Narzędzia te coraz częściej nie wymagają żadnej specjalistycznej wiedzy, a co za tym idzie znacznie więcej osób może z nich swobodnie korzystać. Naturalnie stawia to pytanie, czy generowane treści powinny być dozwolone?
Powiedzmy sobie wprost: technologia nie jest głównym sprawcą dezinformacji. Choć oczywiście jest używana do jej szerzenia, to ludzie są głównym źródłem dezinformacji. Ludzie, którzy z różnych powodów, często nawet nieświadomie, decydują się na wprowadzanie innych w błąd. Dezinformacja kwitnie w rękach internetowych trolli, botów, osób nieświadomych, a także tych, którzy celowo manipulują informacjami.
W erze, gdzie algorytmy uczenia maszynowego rozwijają się w zawrotnym tempie, coraz trudniejsze staje się rozróżnianie prawdziwych treści od tych wygenerowanych przez sztuczną inteligencję. Generowane treści mogą być niezwykle przekonujące i trudne do wykrycia, zwłaszcza dla przeciętnego użytkownika Internetu. Powszechnie dostępne chat boty mogą wygenerować teksty, obrazy, filmy, czy muzykę, które, niejednokrotnie nie tylko na pierwszy rzut oka, wyglądają bardzo realistycznie.
Jednakże, równolegle do wspomnianego rozwoju technologicznego, rozwijane są również narzędzia służące do wykrywania treści sztucznie wygenerowanych. Te narzędzia są kluczowe dla zapewnienia prawidłowego funkcjonowania społeczeństwa w przyszłości poprzez utrzymywanie wysokiego poziomu wiarygodności informacji w przestrzeni online. W związku z tym, konieczne jest ciągłe doskonalenie tych narzędzi oraz edukacja społeczeństwa na temat sposobów rozpoznawania dezinformacji. Nadzieję daje powszechna świadomość zagrożeń wynikających z niekontrolowanego stosowania SI. Dodatkowo, coraz częściej można się spotkać z tym, że zdjęcia i filmy tworzone przez sztuczną inteligencję są oznaczone przez znaki wodne. Przykładem może być wymaganie chińskiego rządu dotyczące oznaczania zdjęć i filmów generowanych przez sztuczną inteligencję znakami wodnymi, co ułatwia weryfikację ich autentyczności. Oczywiście nie rozwiązuje to zupełnie problemu, gdyż wymaga to stworzenia odpowiedniego systemu tworzenia znaków wodnych, co może potencjalnie prowadzić do wielu implikacji związanych z prawami autorskimi, ale z pewnością jest to krok w dobrą stronę. Zdecydowanie łatwiejszy sposób oznaczania treści wygenerowanych przez SI proponuje serwis YouTube. W momencie dodawania filmu pojawia się opcja oznaczenia takich treści poprzez wybranie odpowiedzi Tak/Nie. Mimo że zasady serwisu nakazują twórcom stosowanie oznaczenia, to w rzeczywistości nie zawsze jest to egzekwowane.
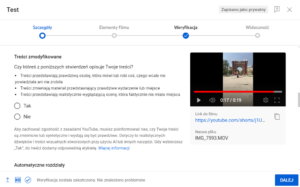
Funkcja oznaczenia treści zmodyfikowanych w Studiu Twórców YouTube
Wykorzystywanie treści generowanych – szansa czy zagrożenie?
Aspekt wykorzystywania treści generowanych przez SI omówił Steve Wozniak podczas konferencji “The Three Seas Generation Freedom Conference 2023” zorganizowanej przez Politechnikę Warszawską.
“Sztuczna inteligencja powinna być wielkim narzędziem, które pomoże ludziom pójść dalej niż kiedykolwiek.”
Podkreślił on, że narzędzia takie jak ChatGPT mogą w szybki sposób udzielić “dobrze sformułowanych, dobrze napisanych” odpowiedzi. Jego zdaniem używanie takich treści nie powinno być zakazane, ale powinno być oznaczone jako stworzone przy użyciu sztucznej inteligencji. Co więcej, Wozniak uważa, że czytelnik powinien zostać poinformowany także o tym, jakie dokładnie narzędzie zostało wykorzystane do wygenerowania danej treści. Dzięki temu czytelnik będzie świadomy konieczności krytycznego spojrzenia na materiał, z którym ma do czynienia. Takie zastosowanie sztucznej inteligencji stanowi szansę na usprawnienie wielu kwestii.
Wozniak zwrócił też uwagę na zagrożenia płynące z rozwoju systemów SI, a konkretniej technologii deepfake, dzięki którym możliwa jest cyfrowa obróbka zdjęć lub głosu. Praktyki związane z deepfake są coraz częściej wykorzystywane do oszustw i wyłudzeń. W ostatnim czasie sporo można było słyszeć o połączeniach z wygenerowanym głosem bliskiej osoby błagającej o pomoc po spowodowaniu wypadku. Ofiarami takich ataków najczęściej są starsze osoby, które są nieświadome zagrożenia. W końcu która matka nie oddałaby wszystkich oszczędności, żeby jej ukochany syn nie trafił do więzienia? W celu podkreślenia potęgi sztucznej inteligencji w zakresie deepfake’ów i wyłudzeń warto przytoczyć jeszcze jeden przykład. Początkiem tego roku pracownik międzynarodowej firmy przelał ponad 25 milionów dolarów na konto oszustów, po tym jak dostał takie polecenie na wideokonferencji od kierownika. W spotkaniu brali udział również inni pracownicy firmy, będący świadkami zleconego zadania, więc pracownik nie nabrał żadnych podejrzeń. Dopiero po czasie okazało się, że zarówno kierownik, jak i pozostali pracownicy mieli cyfrowo wygenerowany wygląd i głos.
Plagiat czy inspiracja?
Dla większości osób przepisy związane z prawem autorskim nie są jednoznaczne ani łatwe do interpretacji. Każdy natomiast, przynajmniej intuicyjnie, zdaje sobie sprawę z tego, czym jest plagiat. W związku z rozwojem narzędzi do generowania treści, konieczne jest spojrzenie na pojęcie plagiatu z innej perspektywy. Czy stosowanie narzędzi takich jak ChatGPT stwarza zagrożenie bycia posądzonym o plagiat? Czy używanie wygenerowanych treści może być uznane za przestępstwo? Trudno jednoznacznie odpowiedzieć na te pytania. Są to dość świeże zagadnienia, w dodatku stale się rozwijające, co powoduje, że trudno jest ocenić, do jakiego stopnia wykorzystywanie SI jest etyczne i nieszkodliwe społecznie, a kiedy ta granica jest przekroczona.
Jednym z najczęściej przewijających się tematów plagiatu a wykorzystania SI jest pisanie prac dyplomowych na studiach wyższych. Prace dyplomowe, przed złożeniem i egzaminem, są weryfikowane pod kątem plagiatu przez JSA (Jednolity System Antyplagiatowy). Jak można wyczytać na portalu bankier.pl, JSA został wyposażony w narzędzie, które pomaga w wykrywaniu treści wygenerowanych przez sztuczną inteligencję. Konieczne jest podkreślenie, że narzędzie to nie daje stuprocentowej pewności, że dany fragment został stworzony przez SI, a jedynie określa, jakie jest prawdopodobieństwo, że tak jest. Prawdopodobieństwo jest tym większe, im więcej jest regularności w tekście. Modele językowe nie potrafią w pełni naśladować tekstu stworzonego przez człowieka. Często brakuje im oryginalności i indywidualności, a wygenerowane teksty pozbawione są błędów i cechują się dużą szablonowością. Eksperci Ośrodka Przetwarzania Informacji twierdzą, że nawet twórcy technologii ChatGPT nie mają narzędzia, które ze stuprocentową pewnością potrafi wskazać tekst napisany przez bota.
Wykrywanie twórczości SI jest jednak coraz trudniejsze. Boty z każdym dniem coraz lepiej naśladują prawdziwą rozmowę. Za przykład można przytoczyć niedawną sytuację, w której chat bot firmy kurierskiej DPD zaczął przeklinać podczas rozmowy z klientem, a także sam skrytykował swoje działanie i koncern, dla którego “pracował”. Taki przykład, że SI może w niedalekiej przyszłości bardzo umiejętnie naśladować ludzi, co sprawi, że jej wykrycie może się wiązać z dużymi trudnościami.
Parcel delivery firm DPD have replaced their customer service chat with an AI robot thing. It’s utterly useless at answering any queries, and when asked, it happily produced a poem about how terrible they are as a company. It also swore at me. 😂 pic.twitter.com/vjWlrIP3wn
— Ashley Beauchamp (@ashbeauchamp) January 18, 2024
Do kogo należą prawa autorskie?
Tak jak wcześniej wspomniano, przepisy prawa autorskiego są zawiłe i trudne w interpretacji. W rozumieniu art. 1 ustawy o prawie autorskim i prawach pokrewnych, mówiącym, że „przedmiotem prawa autorskiego jest każdy przejaw działalności twórczej o indywidualnym charakterze, ustalony w jakiejkolwiek postaci, niezależnie od wartości, przeznaczenia i sposobu wyrażenia (utwór)”, można stwierdzić, że każde dzieło stworzone przez SI podlega ochronie. W celu ustalenia komu przysługiwałyby prawa autorskie należy przyjrzeć się ust. 1 art.8 ustawy o prawie autorskim i prawach pokrewnych – “prawo autorskie przysługuje twórcy, o ile ustawa nie stanowi inaczej”. Ale kto jest twórcą? Odpowiedź na to pytanie można znaleźć w ust. 2 tego samego artykułu – “domniemywa się, że twórcą jest osoba”. Osoba, czyli człowiek. W przypadku treści generowanych, autorem nie jest człowiek, tylko sztuczna inteligencja. Czy to oznacza, że treści wygenerowane przez SI nie podlegają ochronie? Niezupełnie.
W różnych źródłach można znaleźć wiele interpretacji przepisów, które sprowadzają się do podobnego wniosku – treści wygenerowane przez sztuczną inteligencję nie są chronione prawnie. Nie są one bowiem wytworem człowieka. Nie oznacza to jednak, że można bezkarnie używać treści wygenerowanych przez sztuczną inteligencję. Ustawa przewiduje przynależność praw autorskich twórcom oprogramowania, co oznacza, że osoba, do której należą prawa autorskie do programu, będzie również posiadać prawa autorskie do treści wytworzonych przez ten program. Zapewnia to art. 74 ustawy o prawie autorskim i prawach pokrewnych – „1. Programy komputerowe podlegają ochronie jak utwory literackie, o ile przepisy niniejszego rozdziału nie stanowią inaczej.”. Takie samo stanowisko przedstawia ChatGPT, zapytany o to, do kogo należą prawa autorskie wygenerowanych przez niego treści.
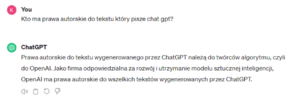
ChatGPT odpowiadający na pytanie do kogo należą prawa autorskie do wygenerowanych odpowiedzi
Regulacje prawne
Rozwój sztucznej inteligencji i jej ogromny wpływ na codzienne życie jest niepodważalny. Nic dziwnego, że pojawiają się wątpliwości, czy SI nie powinna być regulowana prawnie, a w niektórych obszarach wręcz zakazywana. 13 marca br. Parlament Europejski przyjął rozporządzenie dotyczące sztucznej inteligencji (tzw. AI Act). Rozporządzenie ma uregulować zasady używania narzędzi opartych na działaniu SI. Zadaniem AI Act ma być “ochrona praw podstawowych, demokracji, praworządności i środowiska przed systemem sztucznej inteligencji wysokiego ryzyka”. Dzięki nowym regulacjom możliwe ma być dalsze rozwijanie SI przy jednoczesnej gwarancji poszanowania praw człowieka i minimalizowaniu zjawiska dyskryminacji. Stworzenie takiego rozporządzenia oraz nakaz stosowania go przez państwa członkowskie UE pokazuje potęgę SI i obawy, które za sobą niesie.
Czy istnieje przyszłość, w której możliwa jest weryfikacja treści wygenerowanych przez SI?
Oczywiście, na to pytanie nie da się jeszcze jednoznacznie odpowiedzieć. Ludzkość dopiero odkrywa potęgę sztucznej inteligencji, a ta jedynie zaczęła raczkować. Niemniej, pojawia się coraz więcej pomysłów na radzenie sobie z weryfikacją treści generowanych przez SI. Coraz więcej firm wdraża obsługę standardów ustalonych przez Coalition for Content Provenance and Authenticity (C2PA), które wspiera już między innymi Google, Microsoft czy Adobe. Standardy te mają na celu ułatwienie śledzenia i weryfikacji autentyczności treści w Internecie, co może przyczynić się do ograniczenia rozprzestrzeniania się dezinformacji.
W przypadku tekstów generowanych przez ChatGPT, algorytm dodaje znak wodny w postaci losowych znaków w tekście, które maja jednoznacznie potwierdzać autorstwo GPT. Ów ciąg znaków ma być niewykrywalny przez użytkownika i stanowi metodę autentykacji wygenerowanych treści. Open AI przyznało, że wprowadzenie tego mechanizmu ma ograniczyć zjawisko plagiatu w środowisku akademickim oraz masowe generowanie treści propagandowych.
W przypadku prac graficznych znaki wodne mogą przyjąć formę logo lub być dostępne jedynie dla algorytmów wyciągających podpisy cyfrowe. Obecnie najbardziej obiecującą metodą jest SynthID wprowadzone przez Google, które polega na wprowadzeniu znaku wodnego w piksele grafiki w taki sposób, że są one obecne nawet po przycięciu czy zmianie rozmiaru grafiki. Jednakże, sam Google przyznał, że SynthID nie jest idealne i nie może stanowić jedynego narzędzia w walce z treściami generowanymi. W związku z tym konieczne jest szukanie nowych rozwiązań do kontrolowania treści generowanych.
Niestety, na dzień dzisiejszy wydaje się, że regulacje oraz efektywność narzędzi weryfikujących prawdziwość treści generowanych nie nadążają za rozwojem sztucznej inteligencji. Konieczne jest podjęcie bardziej aktywnych działań, aby zapobiec nadużyciom oraz utrzymać wysoki poziom wiarygodności informacji w erze cyfrowej. Zakazanie używania sztucznej inteligencji nie jest rozwiązaniem problemu, takie działanie mogło by wręcz przynieść odwrotny efekt. Należy edukować społeczeństwo na temat zagrożeń związanych z coraz powszechniejszym dostępem do narzędzi SI oraz promować odpowiedzialne i krytyczne podejścia do korzystania z tych technologii.
Źródła
- Raport World Economic Forum https://www.weforum.org/publications/global-risks-report-2024/
- https://www.linkedin.com/pulse/how-ai-boosting-disinformation-melissa-fleming-vbdpe
- Oznaczanie treści generowanych na YouTube https://www.polsatnews.pl/wiadomosc/2024-03-20/nowe-wymagania-dla-youtuberow-tresci-generowane-przez-ai-na-celowniku-giganta/
- Steve Wozniak https://naukawpolsce.pl/aktualnosci/news%2C98537%2Csteve-wozniak-tresci-tworzone-przez-ai-powinny-posiadac-odnosniki-do-zrodel
- Kradzież 25 mln https://forsal.pl/lifestyle/technologie/artykuly/9426806,rekordowy-przekret-na-deepfake-oszusci-ukradli-25-mln-dolarow.html
- SI a Jednolity System Antyplagiatowy https://www.bankier.pl/wiadomosc/Antyplagiat-po-nowemu-Promotor-sprawdzi-czy-student-korzystal-z-technologii-GPT-przy-pisaniu-pracy-dyplomowej-8695958.html
- Chat bot DPD https://twitter.com/ashbeauchamp/status/1748034519104450874?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1748034519104450874%7Ctwgr%5E41b8c0a9d9353d307174f6a7274783dd05b15c3e%7Ctwcon%5Es1_&ref_url=https%3A%2F%2Fpulsembed.eu%2Fp2em%2FwYCRTIhKq%2F
- Rozporządzenie Parlamentu Europejskiego https://www.gov.pl/web/cyfryzacja/przelomowe-przepisy-dotyczace-sztucznej-inteligencji–parlament-europejski-przyjal-rozporzadzeniehttps://www.tgc.eu/publikacje/ai-act-przyjety-sztuczna-inteligencja-pod-kontrola-ue/
- Coalition for Content Provenance and Authenticity https://c2pa.org/
- OpenAI o znakach wodnych https://scottaaronson.blog/?p=6823
- Google o SynthID https://www.theverge.com/2023/10/31/23940626/artificial-intelligence-ai-digital-watermarks-biden-executive-order