Stronniczość sztucznej inteligencji mogła zostać uznana za duży problem, mogący oddziaływać na dużą część społeczeństwa prawdopodobnie wraz z rozpowszechnieniem się internetu wśród użytkowników niekomercyjnych. W Polsce miało to miejsce około 20 lat temu. W Stanach Zjednoczonych nie więcej niż kilka lat wcześniej. Wiązało się to bowiem z szerokim wykorzystaniem wydanej w 1998 roku wyszukiwarki Google, która za pomocą sprawnego algorytmu była w stanie zaproponować użytkownikom wyniki odpowiadające zadanym w języku naturalnym zapytaniu. Co jednak jest miarą jakości uzyskanych wyników? Co to oznacza, że są one adekwatne? Czy nie są one tendencyjne, faworyzując pewne wyniki względem innych? I co najważniejsze, jakie mogą być skutki tej stronniczości?
Pomimo swojej sprawności, wyszukiwarka Google nie korzystała początkowo z uczenia maszynowego, opierając swoje działanie na algorytmie PageRank. Rozwój technologii, uczynił ją wrażliwszą na nowe czynniki, mogące wpływać na jej tendencyjność. Jest to szczególnie istotne, biorąc pod uwagę coraz szersze wykorzystanie uczenia maszynowego w wielu dziedzinach życia człowieka, co może prowadzić do różnych skutków, które mogą być rozpatrywane z perspektywy zarówno pojedynczych osób, jak i całego społeczeństwa. Warto jednak pamiętać, jak zauważono w (Ntoutsi i in., 2020), że pewnego rodzaju stronniczość zawsze istniała w społecznościach ludzkich od momentu ich powstania. Co jednak istotne, rozwój sztucznej inteligencji może zwiększyć jej skalę oraz sprawić, że zacznie przejawiać się na inne sposoby. Warto do tego dodać, że jej charakter może przejawiać się w bardziej systemowy sposób, uniemożliwiający dopatrzenie się ludzkiej odpowiedzialności. Może również prowadzić do wystąpienia pętli z pozytywnym sprzężeniem zwrotnym, w której stronnicze predykcje systemu, w wyniku różnych procesów, mogą prowadzić do dalszego zwiększania własnej stronniczości.
Problemy ze stronniczością
Jakich dziedzin życia może dotyczyć problem stronniczości? Rozważania na ten temat można rozpocząć od rozrywki oraz drobnych użyteczności, mających usprawnić codzienne funkcjonowanie. Można zatem zacząć od wymienienia algorytmów rekomendujących treści w serwisach streamingowych, takich jak Netflix, Spotify, czy Pinterest. Chociaż pozornie społecznie nieistotne, poprzez dostarczaną sztukę mogą kształtować przemyślenia, świadomość pewnych problemów, czy ogólne poczucie estetyki swoich odbiorców. Ponieważ algorytmy mają dostęp do danych pochodzących z wyłącznie dotychczasowej aktywności użytkowników, mogą ciągle polecać jedynie już dobrze znane rodzaje dzieł, zmniejszając szansę na odkrycie czegoś nowego, inspirującego. Dodatkowo, przez swoją stronniczość, mogą uniemożliwić części twórców uzyskanie odpowiedniego rozgłosu, z którym może być związana możliwość uzyskania odpowiednich przychodów. Podobny problem może dotyczyć wyszukiwarek oraz sklepów internetowych, w wyniku czego część sprzedawców, bądź usługodawców może nie być w stanie dotrzeć do potencjalnych klientów. Stronniczość przekazywania informacji przez serwisy informacyjne może skutkować brakiem dostępu do istotnej wiedzy. W przypadku portali randkowych, może natomiast zmniejszyć szansę na znalezienie odpowiedniego partnera.
W przypadku bardziej kontrowersyjnych kwestii, takich jak wykorzystanie uczenia maszynowego w wymiarze sprawiedliwości, decydowaniu w sprawie podjęcia leczenia, oferowaniu zatrudnienia, bądź udzielaniu kredytów, jedna decyzja może zaważyć na przyszłym kształcie czyjegoś życia. W artykule (Angwin i in., 2013) opisano działanie wykorzystywanego w Stanach Zjednoczonych systemu COMPAS, mającego przewidywać ryzyko ponownego popełnienia przestępstwa. Przewidywał ryzyko jako wyższe w przypadku osób czarnych, niż w przypadku osób białych, nawet kiedy inne czynniki na to nie wskazywały. W wyniku tego, do części osób niesłusznie przypisano wysoki wskaźnik ryzyka, podczas gdy u innych ten wskaźnik był zaniżony. Tego typu zdarzenia mogą posłużyć jako przykład systemu, w którym mogłoby wystąpić pozytywne sprzężenie zwrotne. Grupa osób z zawyżonym wskaźnikiem ryzyka mogłaby bowiem być częściej zatrzymywana przez policję oraz skazywana w procesach sądowych, przez co do systemu trafiałoby więcej danych na temat popełnionych przez nią przestępstw, co nie działoby się w przypadku innych grup społecznych.
Zainteresowanie społeczne
Opisana tendencyjność systemu COMPAS oraz przedstawienie innych, podobnie działających systemów, wywołały oburzenie części społeczeństwa oraz doprowadziły do zwiększenia zainteresowania tematem stronniczości uczenia maszynowego, co znalazło odbicie w liczbie poświęconych mu publikacji. Poniższy wykres przedstawia ilość badań na stronie dimensions.ai odpowiadających zapytaniu “bias in machine learning” od 2000 roku.
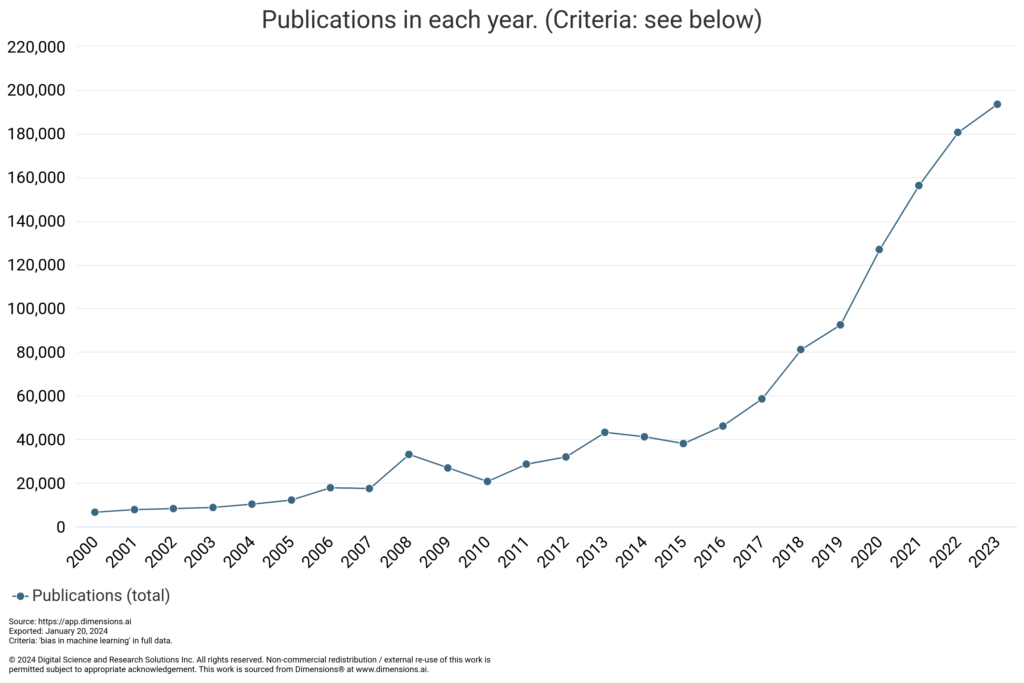
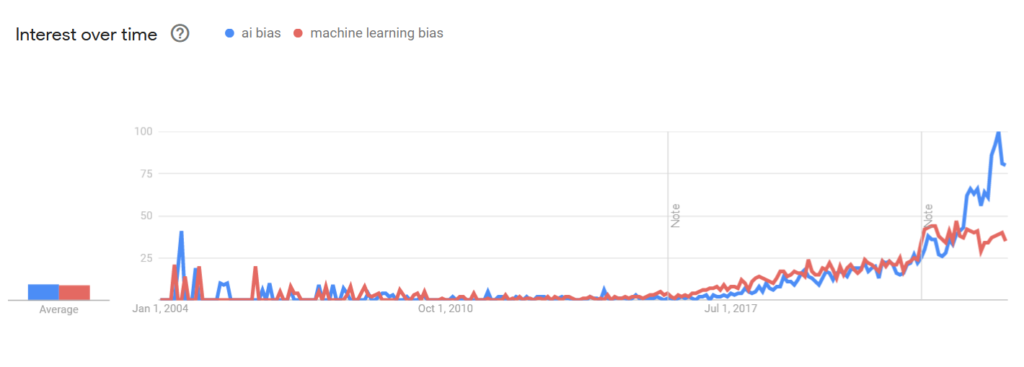
Zainteresowanie rośnie również wśród ogółu społeczeństwa, co przejawia się we wzroście liczby zapytań o hasła “ai bias” oraz “machine learning bias”, przedstawionej na stronie trends.google.com.
Kategoryzacja problemu
Problem tendencyjności jest złożony i rozważając go, można skupiać się na różnych jego aspektach. Biorąc to pod uwagę, konieczne staje się wprowadzenia klasyfikacji jej możliwych źródeł. Zadanie to zostało podjęte w wielu pracach. Dla przykładu (Roselli et al., 2019) wyróżnia trzy potencjalne miejsca przejawiania się stronniczości: określenie celu wykorzystania uczenia maszynowego, ogólne cechy całego zbioru danych oraz charakterystyka indywidualnych próbek danych. Z kolei (Schwartz et al., 2022) szczegółowo rozważa ten problem i przedstawia trzy główne kategorie stronniczości: systemowa (historyczne, społeczne, instytucjonalne), ludzka (indywidualne i grupowe) oraz statystyczna i obliczeniowa (przy przetwarzaniu i walidacji, użyciu i interpretacji oraz wyboru i próbkowania). Poza wyróżnieniem poszczególnych kategorii i podkategorii, w pracy zostaje szczegółowo opisane, jakie mogą być przyczyny poszczególnych błędów.
Problem ten jest rozpatrywany również w wielu innych pracach, jednak (Mehrabi et al., 2021) pozwala na przedstawienie go w szeroki, ale jednocześnie uporządkowany sposób. Również wyróżniając trzy potencjalne źródła stronniczości:
- Dane, przy pomocy których trenowany jest algorytm. W tej kategorii znajdują się problemy związane z m.in. pozyskaniem danych (sposobem mierzenia), pomijaniem istotnych zmiennych, korzystaniu z niereprezentatywnej próby, czy też nadmiernemu generalizowaniu.
- Algorytm, który korzystając z danych dostarcza użytkownikom wyników. Można tutaj zakwalifikować wszelkie problemy związane z wykonywanymi obliczeniami, operacjami statystycznymi, czy samymi cechami wybranych algorytmów, takimi jak sposób dokonywania ewaluacji. Co więcej, znajdują się tutaj wszelkie kwestie związane z tym, w jaki sposób, użytkownicy obcują z otrzymanymi wynikami.
- Użytkownicy, którzy swoim działaniem wpływają na dane. Należy tutaj uwzględnić wszelkie aspekty społeczne i historyczne, sprawiające że pozyskane dane zawierają pewną tendencyjność. Jako przykład można podać sugerowanie się opiniami znajomych podczas oceniania filmów, bądź częstsze uczestniczenie studentów w różnych badaniach, ze względu na łatwiejszy dostęp.
Takie ujęcie problemu może pozwolić na rozszerzenie pola poszukiwań jego potencjalnych rozwiązań oraz na zauważenie, że kwestia stronniczości uczenia maszynowego może niekiedy być postrzegana jako odbicie strukturalnych problemów społecznych.
Bibliografia
AI Bias, Machine Learning Bias. (20.01.2024). Google Trends. Ostatni dostęp: 20.01.2024, https://trends.google.com/trends/explore?date=all&q=ai%20bias,machine%20learning%20bias&hl=en
Angwin, J., Larson, J., Mattu, S., & Kirchner, L. (2016). Machine Bias. ProPublica.
Dimensions – Dimensions AI. (20.01.2024). Dimensions. Ostatni dostęp: 20.01.2024, https://app.dimensions.ai/discover/publication
Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2021). A Survey on Bias and Fairness in Machine Learning. Association for Computing Machinery, 54. https://doi.org/10.1145/3457607
Ntoutsi, E., Fafalios, P., Gadiraju, U., Iosifidis, V., Nejdl, W., Vidal, M.-E., Ruggieri, S., & Turini, F. (2020). Bias in data-driven artificial intelligence systems—An introductory survey. WIREs Data Mining and Knowledge Discovery, 10(3). https://doi.org/10.1002/widm.1356
Roselli, D., Matthews, J., & Talagala, N. (2019). Managing Bias in AI. Association for Computing Machinery, 539–544. https://doi.org/10.6028/NIST.SP.1270
Schwartz, R., Vassilev, A., Greene, K., Perine, L., Burt, A., & Hall, P. (2022). Towards a Standard for Identifying and Managing Bias in Artificial Intelligence. National Institute of Standards and Technology, NIST Special Publication 1270.