
Quantified Self – wykorzystanie danych i sztucznej inteligencji do poprawy wydajności intelektualnej oraz wspomagania podejmowania decyzji. Architektura technologii, możliwości, wyzwania i kwestie etyczne.
Początki i rozwój pojęcia
Quantified Self (QS) określa ruch społeczny, który został zapoczątkowany w 2007 roku przez redaktorów magazynu Wired, Gary’ego Wolfa i Kevina Kelly’ego. Opiera się w swoich założeniach na wykorzystaniu technologii do sporządzania pomiarów i gromadzenia danych z różnych dziedzin życia, zaczynając od danych biologicznych, przez te behawioralne po środowiskowe. Osoby zaangażowane w ruch pozyskują informacje o wskaźnikach związanych ze stanem zdrowia, czy aktywnością fizyczną, ale też dotyczących nastroju i zdolności poznawczych. (Combs, Barham, 2016) Przyświecają temu różnorodne cele. Środowisko od samego początku – jeszcze przed zawiązaniem ruchu – składało się zarówno z entuzjastów nowych technologii, wykorzystujących je choćby dla zwiększenia własnej produktywności, osób uprawiających fitness, liczących na poprawę efektów treningu, jak również chorych na rzadkie schorzenia, poszukujących w zebranych w ten sposób obserwacjach jaśniejszych odpowiedzi, co do własnego stanu zdrowia. Wszyscy oni dzielili przekonanie, że „w swoich danych odnajdą samych siebie”, co skłaniało ich do podjęcia się czasochłonnego zadania zbierania i analizy danych. (Kreit, 2018)

Rozwój koncepcji był w dużej mierze uzależniony od powstania i rozpowszechnienia smartfonów i elektroniki noszonej, który znacząco ułatwił dokonywanie pomiarów i ich przechowywanie, otwierając tym samym drogę do dołączenia do ruchu szerszemu gronu osób – śledzenie mierzonych informacji nie wymaga już żywego zainteresowania tematem. Jednak chociaż aplikacje rejestrujące liczbę przebytych kroków czy puls działają w tle, w ramach QS podkreśla się konieczność świadomej analizy dostarczanych przez nie danych. Nastąpiła pod tym względem zmiana myślenia – od skupiania się na technologii jako rozwiązaniu do postrzegania jej jako narzędzia, mającego wspierać refleksję użytkownika. Stąd obok stwierdzenia, jak można lepiej zbierać potrzebne informacje, istotne stało się pytanie, co mierzyć, by zbliżyć się do odkrycia interesującej daną osobę odpowiedzi. (Kreit, 2018)
Nie może więc dziwić, że zmieniały się też zbierane przez osoby zaangażowane w ruch dane, początkowo skupione wokół zdrowia i uprawiania sportu, a stopniowo rozszerzone m.in. o nastrój, nawyki czy procesy poznawcze (np. koncentrację).
Wydajność intelektualna i wspomaganie podejmowania decyzji a dane
Podstawą każdego projektu QS są dane – dobrane zależnie od obranego celu, a w perspektywie ruchu jako całości bardzo różnorodne; obok typowych danych medycznych, takich jak historia medyczna rodziny, przyjmowane lekarstwa czy wyniki testów laboratoryjnych pojawiają się nowe dane z obszarów takich jak genomika, pomiary mikrobiomu czy metabolomika, ale również dane zbierane przez elektronikę noszoną czy zapisywane przez zainteresowane osoby informacje z dzienników, rejestrujące nawyki, a nawet nastrój. (Swan, 2013) Informacje mogą być zbierane przez urządzenia w tle, niewymagając interakcji ze strony osoby je mierzącej (np. pomiar liczby przebytych kroków), albo przeciwnie – opierać się o jej zaangażowanie (np. wszelkiego rodzaju testy kognitywne).
Ze względu na typ zbierane dane można podzielić na kategorie takie jak dane biomedyczne, do których zaliczają się dane fizjologiczne (przykładami których mogą być tętno, ciśnienie krwi, temperatura ciała czy poziom glukozy we krwi). Wspólnie stanowią one obraz stanu organizmu, pozostający nie bez znaczenia też na wydajność intelektualną.
Inną grupą danych są dane behawioralne, obejmujące wszelkie nawyki i rutyny. Zaliczyć mogą się do nich czas przeznaczony na pracę, obserwowane użycie urządzeń elektronicznych, ale też np. dane związane ze spożywanymi posiłkami i szerzej dietą (np. ilością wypitej dziennie kawy).
Kluczowe dla poprawy wydajności intelektualnej, ale najtrudniejsze w badaniu, są dane kognitywne. Tworzą je m.in. opisy subiektywnych uczuć (wszelkiego rodzaju samoocena np. koncentracji czy nastroju odnotowywanego w danym momencie), ale też np. wyniki testów kognitywnych sprawdzających pamięć, czas reakcji albo liczbę popełnianych błędów.
Badanie tak różnorodnych wskaźników może umożliwiać poszukiwanie interesujących korelacji poprzez zestawienie ze sobą różnych typów danych. Przykładem takiego działania może być obserwowanie zależności między zbieranymi przez elektronikę noszoną wskaźnikami dotyczącymi jakości snu (czas poświęcony na sen, spędzony w różnych fazach snu, tętno w trakcie snu) a pogorszeniem czasu reakcji czy spowolnieniem pisania na klawiaturze i popełnieniem większej liczby literówek. (Abdelfattah et al., 2025)
Rola sztucznej inteligencji w ekosystemie QS
Uczenie maszynowe może służyć przetwarzaniu zgromadzonych z elektroniki albo odnotowanych przez poddającą się badaniu osobę różnorodnych danych, celem odnalezienia interesujących związków pomiędzy różnymi poddawanymi pomiarom aspektami fizjologicznymi czy też związanymi z nawykami. Może jednak też być stosowane do sugerowania użytkownikowi rekomendacji, które w założeniu mogłyby np. zachęcać do podejmowania działań sprzyjających lepszemu samopoczuciu czy wyrabianiu zdrowych nawyków. Sprzyja temu możliwość analizy i przetwarzania danych z wielu różnych obszarów, składających się w zależności, które są spersonalizowane dla konkretnej osoby. (Sharma, Rani, 2021)
W kontekście wydajności intelektualnej oznacza to, że system QS mógłby obok rejestrowania określonych nawyków i przykładowo wspomnianych wcześniej wyników testów kognitywnych, wykrywać złe przyzwyczajenia (rozumiane jako takie, które skutkują obniżeniem sprawności umysłowej – w niedługiej perspektywie (np. następnego dnia) albo długoterminowo) i przekazywać wiadomość zwrotną z informacją, które z mierzonych czynników miały najprawdopodobniej wpływ na gorszą wydajność. Możliwy jest też przeciwny scenariusz – model wykazywałby, jakie działania pozytywnie wpływały na uzyskany rezultat danego sprawdzianu, zapewniając dodatkową motywację.
Z perspektywy założeń ruchu wydaje się szczególnie istotne, żeby użytkownik podobnego systemu otrzymywał jak najpełniejszy obraz odkrytych korelacji, co pozwalałoby na spełnienie zarysowanej wcześniej idei lepszego rozumienia siebie.
Przykładowa architektura systemu QS z AI
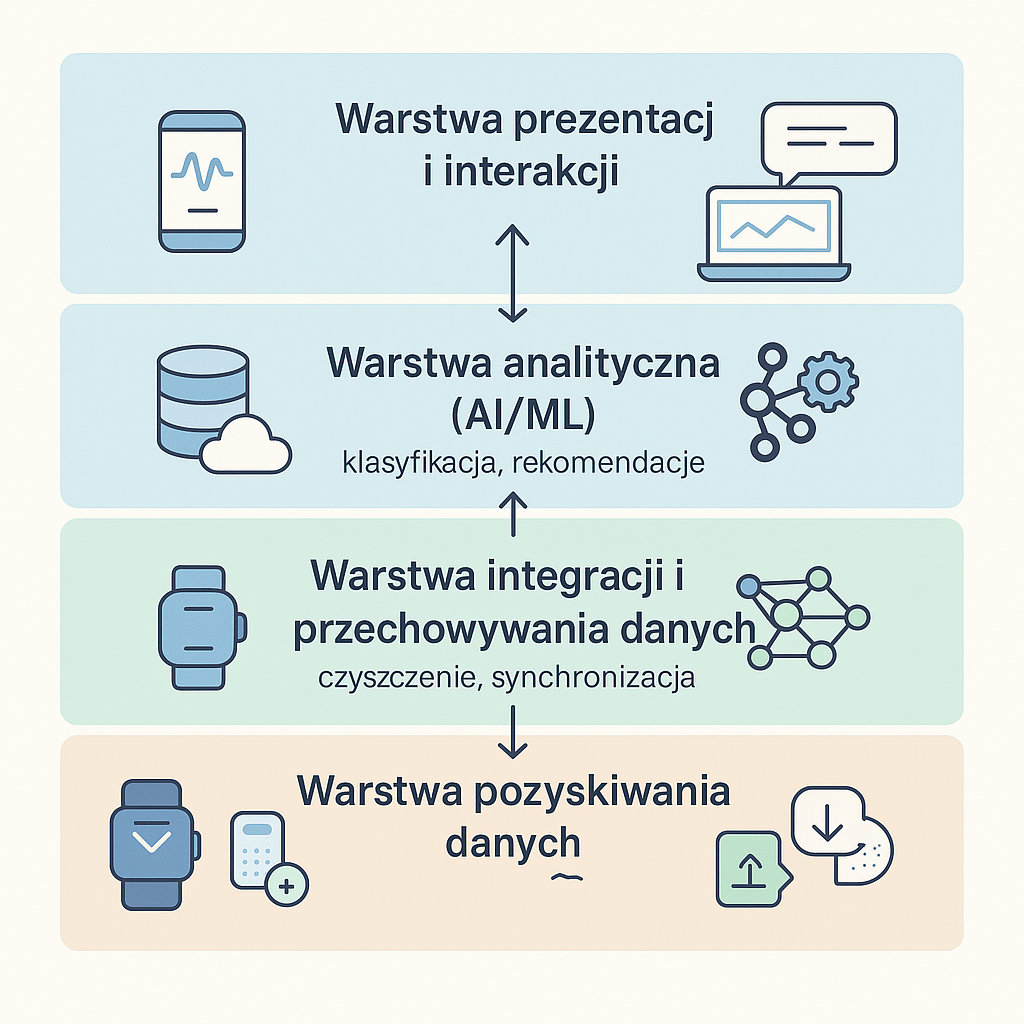
Typowy system Quantified Self zintegrowany ze sztuczną inteligencją w dużym uogólnieniu składa się z kilku podstawowych warstw, które razem realizują proces od pozyskania danych do wygenerowania rekomendacji/feedbacku.
1. Warstwa sensoryczna (Data Capture Layer)
- Czujniki monitorujące sen i aktywność
- Aplikacje mobilne śledzące nastrój, posiłki czy treningi
- Pulsometry
- Smart-zegarki i opaski sportowe
- Medyczne implanty i biosensory (np. do stałego pomiaru glikemii)
2. Warstwa przetwarzania danych (Data Processing Layer)
- Łączenie pomiarów z innymi źródłami
- Przetwarzanie strumieniowe lub wsadowe zależnie od potrzeb
- Czyszczenie danych z błędów i szumów
3. Warstwa analizy (AI/Analytics Layer)
- Systemy rekomendacyjne personalizują plan treningów i regeneracji
- Algorytmy wykrywają trendy, anomalie i korelacje (np. jakość snu ↔ wydolność)
- Modele uczenia maszynowego prognozują reakcje organizmu
4. Warstwa prezentacji dla użytkownika (UX)
- Powiadomienia push
- Boty AI doradzające na bieżąco
- Interaktywne pulpity (dashboardy)
- Wyraźne wizualizacje postępów
5. Modularność, ekosystemy i bezpieczeństwo
Tak poukładane warstwy tworzą technologiczny „szkielet” Quantified Self – od czujnika na ciele po spersonalizowaną wskazówkę na ekranie.
Architektura jest modułowa: warstwę czujnikową i algorytmy AI można rozwijać niezależnie lub wykorzystywać urządzenia dostarczane przez różne zewnętrzne firmy, o ile API pozostają spójne. Na rynku istnieją rozwiązania zamknięte (Fitbit) oraz otwarte standardy wymiany danych – Open mHealth, Open Humans. Kluczowe w obu podejściach są szyfrowanie transmisji, anonimizacja, granularne uprawnienia i pełna transparentność wykorzystania danych.
Przykłady narzędzi i platform
- Urządzenia noszone i sensory medyczne
Niezmiennym fundamentem samo‑monitoringu są wearables wyposażone w czujniki zapewniające całodobowy pomiar parametrów fizjologicznych. Do najczęściej stosowanych należą opaski i zegarki: Fitbit (kroki, sen), Apple Watch (EKG, saturacja), a także modele sportowe Garmin (GPS, metryki treningowe). Segment wyspecjalizowany uzupełniają m.in. Oura Ring (analiza snu i wskaźnik „readiness”), pasy piersiowe HRV do precyzyjnego pomiaru rytmu zatokowego, opaska EEG Muse wspierająca trening uważności oraz zestawy Emotiv rejestrujące aktywność mózgu. Łącznie tworzą one bogate źródło wysokoczęstotliwościowych danych biometrycznych. - Aplikacje mobilne do samotrackingu
Smartfon pełni rolę przenośnego laboratorium badawczego. Oprogramowanie pokroju MyFitnessPal (dziennik żywieniowy), Sleep Cycle (analiza faz snu z mikrofonu i akcelerometru), Headspace czy Calm (statystyka praktyki medytacyjnej), Daylio (monitoring nastroju) oraz RescueTime (analiza czasu pracy i stron WWW) wykorzystuje wbudowane sensory i dane wpisywane ręcznie. W obszarze kognitywnym popularne są programy treningu umysłu (Lumosity, Elevate), natomiast refleksyjny charakter samopoznania wspiera dziennik multimedialny Day One. - Platformy agregujące i dashboardy
W celu integracji danych z licznych źródeł stosuje się rozwiązania systemowe – Apple Health i Google Fit – gromadzące pomiary z wielu aplikacji w obrębie ekosystemu mobilnego. Niezależne usługi, takie jak Gyroscope (rozbudowany „life dashboard”) i Exist.io (automatyczna analiza korelacji między zmiennymi), łączą informacje z trackerów, kalendarzy i mediów społecznościowych, prezentując je na chronologicznej osi czasu. Zaawansowani użytkownicy nierzadko konstruują własne panele oparte na rozwiązaniach open‑source, np. Zenobase lub narzędziach BI w językach Python czy R. - Automatyzacja przepływu danych
Rozproszone środowisko aplikacji integrują platformy reguł warunkowych. Usługi chmurowe IFTTT oraz Zapier umożliwiają definiowanie przepływów „jeżeli X, to Y” (np. eksportowanie dziennej liczby kroków z Fitbit do arkusza kalkulacyjnego). Na poziomie urządzenia analogiczne funkcje realizują Apple Shortcuts oraz Tasker dla systemu Android, automatyzując czynności i synchronizację danych bez udziału użytkownika.

Przykładowy własnoręczny system Quantified Self
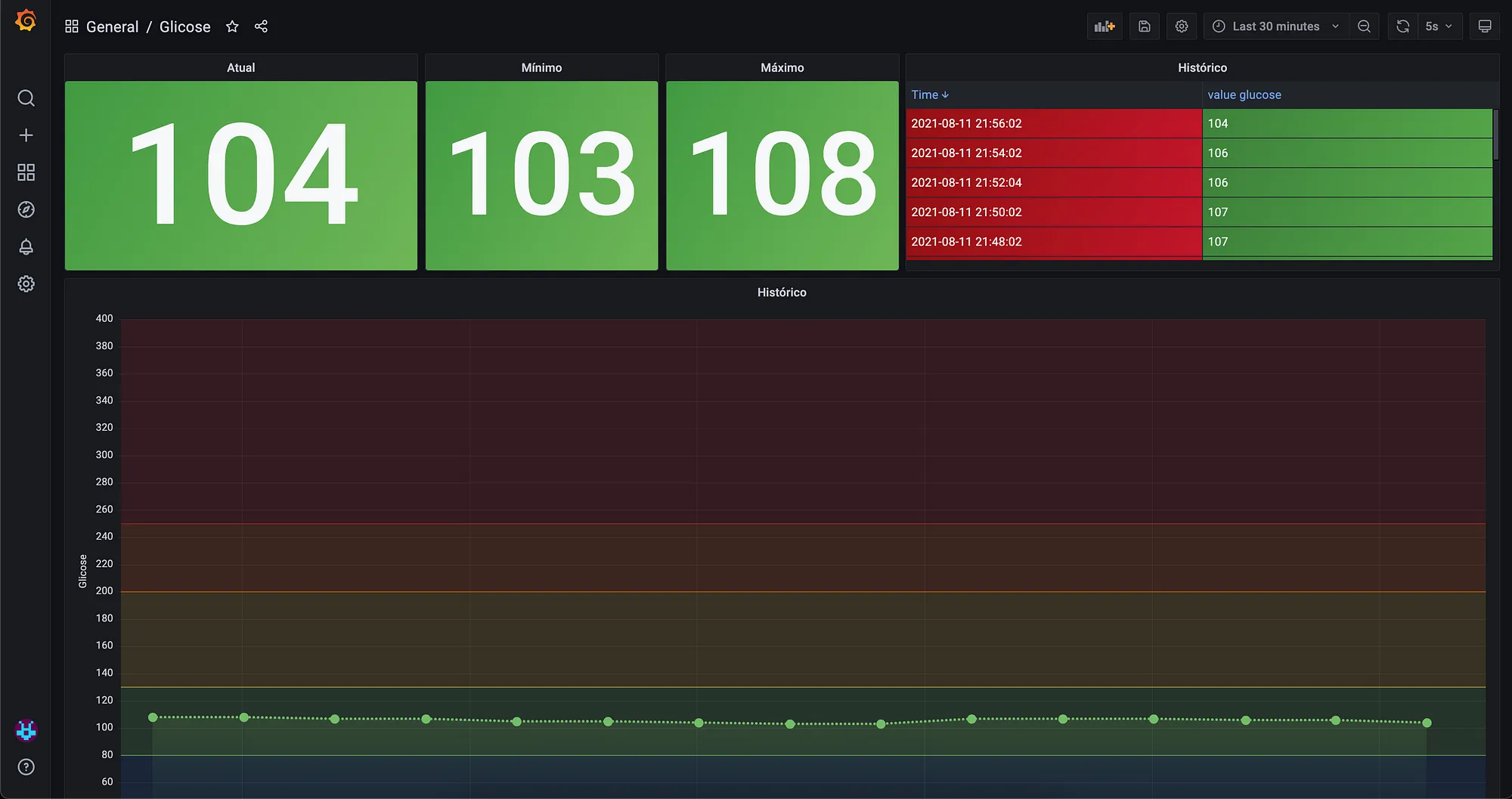
Ten artykuł jest bardzo dobrym przykładem dobrego zastosowania podejścia Quantified Self. Autor jest osobą, która zmaga się z cukrzycą typu pierwszego od dzieciństwa. Jedną z konsekwencji takiej choroby jest konieczność częstego monitorowania poziomu cukru we krwi. Autor, który korzysta ze specjalnej sondy umieszczonej na stałe w ramieniu, zdecydował się na usprawnienie procesu monitorowania swojego poziomu cukru. W tym celu stworzył pipeline, który dane z urządzenia zapisuje w serwisie Dropbox, skąd są sczytywane przez Workflow na Google Cloud Platform, a następnie są wyświetlane jako wykresy w serwisie Grafana. Takie rozwiązanie pozwala na wysyłanie powiadomień do rodziny i bliskich w przypadku drastycznych zmian w poziomie cukru, oraz na wgląd w szczegółowe dane np. dla lekarzy. Jest to świetny przykład na to, że takie platformy mogą być tworzone nie tylko przez duże zespoły programistyczne, ale również przez samych użytkowników.
Krytyka i aspekty etyczne

Podejście „Quantified Self” jest głównie krytykowane na trzech płaszczyznach:
- Autodiagnoza bez kontekstu klinicznego. QS pośrednio zachęca użytkowników do samodzielnego interpretowania danych zdrowotnych, co przy braku odpowiedniego przygotowania (ang. health literacy) może prowadzić do błędnych decyzji i niezamierzonych konsekwencji zdrowotnych.
- Nadużycia w miejscu pracy. Pracodawcy mogą przekraczać granice prywatności, próbując śledzić wydajność lub emocje pracowników. Głośnym przykładem było wdrożenie „liczników uśmiechu” w sopockim urzędzie, rejestrujących częstotliwość uśmiechu urzędników wobec petentów.
- Zagrożenia prywatności i bezpieczeństwa. Quantified Self zachęca użytkowników do zbierania bardzo wrażliwych danych dotyczących ich życia i zdrowia, co wiąże się z całą gamą zagrożeń na płaszczyźnie cyberbezpieczeństwa. Dane zdrowotne są coraz częściej wykorzystywane w celach komercyjnych, co często skłania właścicieli portali umożliwiających śledzenie swojego zdrowia do sprzedaży takich danych do firm zajmujących się marketingiem, sprzedających sprzęt medyczny czy do koncernów farmaceutycznych. Dane dotyczące zdrowia są też dodatkową płaszczyzną ataku dla cyberprzestępców chcących dokonać jakiejś formy inwigilacji na danej osobie fizycznej.
Podsumowanie
Quantified Self łączy technologię, dane i sztuczną inteligencję, aby zwiększyć samoświadomość oraz wspierać decyzje dotyczące zdrowia i wydajności intelektualnej. Choć otwiera ogromne możliwości personalizacji i optymalizacji codziennych nawyków, niesie też realne zagrożenia związane z prywatnością, nadużyciami oraz błędną interpretacją danych. Kluczowe jest więc świadome i etyczne podejście do ich gromadzenia i analizy – z pełną kontrolą użytkownika nad tym, jak i po co jego dane są wykorzystywane.
Literatura
- Donald Combs, Scarlett R. Barham, The Quantifiable Self: Petabyte By Petabyte, The Digital Patient, 2016.
- Bradley Kreit, The Evolution of the Quantified Self – Interview with Gary Wolf, IFTF Blog, 2018.
- H. Abdelfattah et al., Cognitive Performance Measurements and the Impact of Sleep Quality Using Wearable and Mobile Sensors, arXiv preprint 2501.15583, 2025.
- Melanie Swan, The Quantified Self: Fundamental Disruption in Big Data Science and Biological Discovery, Big Data Journal, 2013.
- Deborah Lupton, Self-tracking, health and medicine, Health Sociology Review, 26(1), 2016, pp. 1–5.
- Melanie Swan, Quantified Self, Encyclopedia of Behavioral Medicine, 2018.
- Sarah Lee, Quantified Self: The Future of Personal Data, Number Analytics Blog, 2025.
- Rishav Raj, How a Quantified Life Empowers Us: The Role of Machine Learning in Self-Improvement, Medium, 2025.
- GitHub contributors, awesome-quantified-self, GitHub repository, 2025.
- Michał Wieczorek et al., The ethics of self-tracking: A comprehensive review of the literature, Ethics & Behavior, 2022.
- Quantified Self Labs, QuantifiedSelf.com, 2025.
- Stephen Wolfram, The Personal Analytics of My Life, Wolfram Blog, 2012.