Rozwój sztucznej inteligencji postawił świat nauki przed nowym wyzwaniem: ,,fabryki prac’’ (ang. paper mills) zalewają literaturę naukową publikacjami pozorującymi rzetelne badania. Dzięki potędze dużych modeli językowych (LLM) generowanie przekonujących – choć fałszywych – artykułów stało się łatwiejsze niż kiedykolwiek. To zjawisko podkopuje zaufanie do nauki w podobny sposób, w jaki fake newsy i deepfake’i podważają wiarygodność informacji w społeczeństwie. Główny wniosek jest jasny: bez zdecydowanych działań organizacyjnych i technologicznych ryzykujemy kryzys wiarygodności nauki na niespotykaną skalę.
Wstęp
Pierwsze sygnały alarmowe pojawiły się już lata temu, kiedy okazało się, że całe serie publikacji medycznych i technicznych zostały wyprodukowane na zamówienie przez firmy oferujące autorom „publikacje na sprzedaż” (Else & Van Noorden 2021). Tego typu działalność określa się mianem paper mills – fabryk produkujących pozornie naukowe artykuły, często z fałszywymi danymi lub nawet kupionymi autorstwami. Problem ten urósł do globalnej skali: według szacunków od 2% do nawet 20% publikacji naukowych może pochodzić z paper mills (szczególnie w niektórych działach biomedycyny) (Sanderson 2024). W 2024 r. wydawca Hindawi (część Wiley, wydawnictwa specjalizującego się w publikacjach naukowych) musiał wycofać ponad 11 tysięcy podejrzanych artykułów i zamknąć 19 czasopism po wykryciu masowego oszustwa publikacyjnego (Subbaraman 2024). Co gorsza, coraz częściej podkreśla się, że najnowsze narzędzia AI mogą uczynić te fałszerstwa jeszcze trudniejszymi do wykrycia.
Przegląd literatury
Badacze zajmujący się etyką publikacji od kilku lat biją na alarm, że „papierowi oszuści” wykorzystują coraz sprytniejsze metody. Już w 2021 r. magazyn Nature opublikował analizę wskazującą, że wydawnictwa naukowe zmagają się z „fabrykami fałszywej nauki” produkującymi setki fałszywych prac na zamówienie (Else & Van Noorden 2021). W tamtym czasie zidentyfikowano listy ponad 1000 podejrzanych artykułów, co doprowadziło do setek wycofanych prac przez czasopisma znanych wydawców. Również Wall Street Journal opisał szokujący proceder, w którym firmy sprzedają autorom miejsce na publikację – niekiedy z pomocą skorumpowanych redaktorów – a „lawina pseudonauki” zmusiła wydawców do masowego wycofania całych numerów czasopism (Subbaraman 2024).
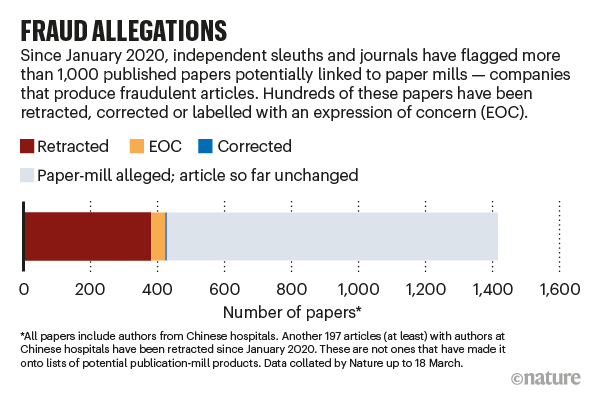
Statystyki dotyczące paper mills. Źródło: Else & Van Noorden 2021.
Zjawisko paper mills ma charakter globalny. Wiele afer ujawniono w Chinach, gdzie presja „publikuj albo giń” sprzyjała rozwojowi czarnego rynku publikacji (McLellan 2025). Jednak problem nie ogranicza się do jednego kraju – wykryto siatki fałszywych publikacji m.in. w Rosji, Iranie czy Indiach (Else & Van Noorden 2021). W głośnym raporcie Anna Abalkina przeanalizowała działalność rosyjskiej firmy International Publisher Ltd., ujawniając 451 potencjalnie fałszywych artykułów powiązanych z tą jedną „fabryką” (Abalkina 2023). Wiele z tych prac znalazło się nawet w uznanych wydawnictwach naukowych, zanim wykryto oszustwo. Skalę problemu dobrze oddaje wypowiedź prof. Dorothy Bishop: „Sytuacja stała się horrendalna. Zalew fałszywych publikacji sprawia, że w niektórych dziedzinach trudno już budować rzetelną, kumulatywną wiedzę naukową” (McKie 2024).
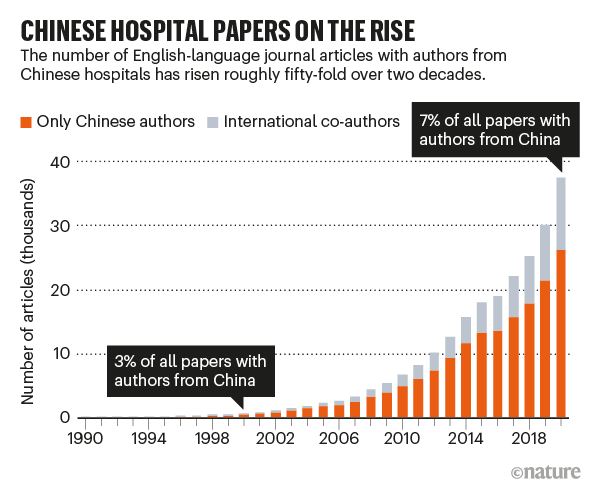
Liczba chińskich autorów w anglojęzycznych czasopismach naukowych na przestrzeni lat. Źródło: Else & Van Noorden 2021.
Jednocześnie pojawiają się nowe czynniki, które eskalują zagrożenie. W końcu 2022 r. świat ujrzał możliwości ChataGPT – modelu AI zdolnego pisać spójne teksty na niemal dowolny temat. Szybko sprawdzono, że potrafi on tworzyć fałszywe abstrakty prac naukowych na tyle przekonujące, że aż 32% recenzentów nie potrafiło ich odróżnić od prawdziwych (Else 2023). Co więcej, popularny chatbot zaczął pojawiać się w podziękowaniach, a nawet jako współautor w nadesłanych tekstach, co wywołało konsternację w środowisku wydawców (Sample 2023). W styczniu 2023 redakcje Science i Nature zareagowały błyskawicznie: zakazano wpisywania ChatGPT jako autora publikacji oraz wprost stwierdzono, że nieakceptowalne jest włączanie wygenerowanych przez AI fragmentów do tekstu naukowego. Jak tłumaczył Holden Thorp, redaktor Science, model językowy nie może być autorem, bo nie bierze odpowiedzialności za treść, a jego niezweryfikowane błędy mogłyby przeniknąć do literatury i wypaczyć wyniki badań.
Pomimo tych ostrzeżeń wykorzystanie LLM w pracach naukowych stale rośnie. Według najnowszych badań około 17,5% manuskryptów z informatyki zawiera fragmenty tekstu wygenerowane przez AI (np. przeredagowane akapity) (Kannan 2024). Nawet w recenzjach naukowych pojawiają się sekcje pisane przez ChatGPT. Wielu naukowców traktuje te modele jako narzędzia pomocnicze – do redakcji języka czy streszczania literatury. Jednak granica między „legalną” pomocą a nieetycznym zastąpieniem własnej pracy przez AI bywa płynna. Literatura fachowa podejmuje ten temat na polu etyki: dyskutuje się, czy i jak bezpiecznie korzystać z AI w pisaniu prac naukowych (np. czy dopuszczalne jest generowanie całych fragmentów tekstu czy jedynie stylistyczna korekta) (Logan 2024).
Analiza problemu

Rzetelność nauki vs. generatywna AI. Źródło: Else & Van Noorden 2021.
Społeczne i etyczne konsekwencje nadużywania AI w nauce są poważne. Przede wszystkim zagrożona jest wiarygodność publikacji naukowych – fundament zaufania społecznego do nauki. Jeżeli czytelnicy i badacze zaczną podejrzewać, że co druga praca może być mistyfikacją wygenerowaną przez algorytm, ucierpi na tym autorytet prawdziwych odkryć. W świecie nauki od dawna obowiązuje zasada, że wyniki muszą być powtarzalne i oparte na rzetelnych danych. Tymczasem wielkie modele językowe są mistrzami „halucynacji” – potrafią zmyślać nieistniejące referencje, dane czy całe eksperymenty w sposób trudny do wychwycenia dla pobieżnego recenzenta. W efekcie do literatury mogą trafiać pozorne odkrycia, których nikt naprawdę nie dokonał. Takie zjawisko to odpowiednik naukowego fake newsa – możemy je nazwać fake science. Skutki mogą być groźne: od błędnego ukierunkowania kolejnych badań, po podejmowanie złych decyzji klinicznych czy technologicznych opartych na sfabrykowanych wynikach (McKie 2024).
Analogii do fake newsów i deepfake’ów jest tu wiele. W sferze informacyjnej zalew fałszywych treści deformuje obraz rzeczywistości i polaryzuje społeczeństwo. Podobnie w nauce, papierowe fabryki mogą zalać bazy danych publikacjami-widmo, które zanieczyszczają wspólną wiedzę i utrudniają odnalezienie prawdy. Deepfake’i – czyli fałszywe obrazy lub nagrania wideo generowane przez sieci neuronowe – podważają zaufanie do materiałów wizualnych („czy to, co widzę, jest prawdziwe?’’). Paper mill z udziałem AI to nic innego jak deepfake artykuł naukowy: na pierwszy rzut oka wygląda wiarygodnie, ale jego treść jest wytworem algorytmu, nie odzwierciedla faktycznie przeprowadzonych badań. Co gorsza, generatywna AI może tworzyć także fałszywe obrazy naukowe – np. zdjęcia mikroskopowe czy wykresy – które trudno odróżnić od prawdziwych (odnotowano już przypadki użycia algorytmów GAN do generowania fikcyjnych zdjęć komórek) (WEB1). To rodzi dylemat: jeśli nawet surowe dane mogą być podrobione, jak zweryfikować wyniki?
Etycznie problem dotyka kwestii autorstwa i odpowiedzialności. Tradycyjnie autor artykułu naukowego zobowiązuje się do uczciwego przedstawienia wyników i ponosi odpowiedzialność za ewentualne błędy czy fałszerstwa. Gdy w grę wchodzi AI jako faktyczny ghostwriter, pojawia się pytanie: kto odpowiada za treść? Czy można obarczyć algorytm winą za plagiat czy błąd merytoryczny? W obecnym konsensusie wydawców – nie. To człowiek podpisany pod pracą musi gwarantować jej rzetelność (Sample 2023). Wykrycie oszustwa skutkuje zatem konsekwencjami dla autora (utrata reputacji, wycofanie pracy), nawet jeśli wina leży po stronie nierozumnej maszyny.
Ważny aspekt stanowi także nierówność dostępu do technologii. Duże modele językowe w wersjach zaawansowanych (np. GPT-4) są płatne i nie każdy badacz czy student może z nich skorzystać. Powstaje ryzyko, że ci, którzy mają dostęp i nie cofną się przed nadużyciem, zyskają nienależną przewagę publikacyjną. To budzi sprzeciw natury etycznej – nauka powinna opierać się na meritum badań, a nie sprycie w użyciu nowych narzędzi. Z drugiej strony podnosi się argument, że LLM mogą niwelować pewne nierówności, np. pomagając naukowcom nieanglojęzycznym pisać płynniejsze teksty po angielsku. Gdzie kończy się więc dopuszczalna pomoc stylistyczna, a zaczyna nieetyczne pisanie za kogoś?
Wreszcie, nadużycie AI w nauce to problem systemowy, bo splata się z presją publikacyjną i patologiami systemu oceniania naukowców. Przykładem z naszego podwórka może być np. punktoza, która zdaniem niektórych badaczy jest „pseudosystemem oceny pracowników nauki”(Katner 2025). Jeżeli uczelnie i grantodawcy rozliczają przede wszystkim liczbę publikacji, nietrudno zrozumieć, dlaczego część badaczy sięga po drogę na skróty. Sztuczna inteligencja staje się wtedy kolejnym narzędziem – obok plagiatu czy manipulacji danymi – do realizacji zasady „cel uświęca środki”. Rozwiązanie musi więc uwzględniać szerszy kontekst kultury akademickiej.
Propozycje rozwiązań
Jak zatem przeciwdziałać nadużyciom LLM i paper mills w nauce?
Zaostrzenie polityki wydawniczej i standardów etycznych
Większość czołowych wydawców już wprowadziła wytyczne dotyczące użycia AI. Należy egzekwować obowiązek ujawniania wykorzystania narzędzi AI na etapie przygotowania manuskryptu. Autorzy powinni w sekcji metodologicznej lub podziękowaniach jasno wskazać, czy np. użyli ChatuGPT do redakcji tekstu. Ukrywanie takiego faktu można traktować jako naruszenie etyki autorstwa. Ponadto utrzymany musi być kategoryczny zakaz wpisywania modeli AI jako współautorów (co wynika chociażby z wymogu, by autor pracował świadomie nad koncepcją i odpowiadał za treść). Redakcje powinny też rozszerzyć deklaracje autorów przed publikacją o zapewnienie, że praca nie została napisana ani przetłumaczona w całości przez AI bez nadzoru człowieka. Takie kroki – choć bazują na zaufaniu – tworzą formalną barierę i mogą działać odstraszająco na mniej zdeterminowanych oszustów.
Technologiczne systemy wykrywania deepfake’owych prac
Skala publikacji (miliony rocznie) wymaga wsparcia automatycznego. Trwają prace nad algorytmami wykrywającymi tekst wygenerowany przez AI – niestety na razie ich skuteczność jest ograniczona, a wyścig zbrojeń trwa (każdy nowy model językowy lepiej maskuje swoje ślady). Mimo to, kombinacja różnych metod może dać dobre wyniki. Proponuje się np. analizę stylometryczną na poziomie całych zbiorów, by wyłapać statystyczne anomalie w częstości słów czy konstrukcjach zdań charakterystycznych dla AI (Liang et al. 2024). Innym podejściem jest weryfikacja krzyżowa źródeł i cytowań – model generatywny często „halucynuje” bibliografię, więc prace z nieistniejącymi lub niepasującymi cytowaniami powinny wzbudzać alarm. Duże wydawnictwa (zrzeszone m.in. w organizacji STM) tworzą wspólną platformę – Integrity Hub – gdzie wykorzystuje się machine learning do wykrywania duplikatów, plagiatów obrazów i powtarzalnych wzorców mogących świadczyć o działaniu paper mill (WEB1). Przykładowo, prototypowe narzędzie porównuje zgłaszane manuskrypty z bazą wcześniej zidentyfikowanych fałszywych prac, szukając podobnych wykresów, tabel czy nietypowych sformułowań. W testach AI wychwyciła nawet więcej podejrzanych obrazów niż doświadczony „ludzki detektyw” (Jones 2024), co pokazuje potencjał takiej automatyzacji.
Ciekawym pomysłem jest także znakowanie treści generowanych przez AI na etapie ich tworzenia. Np. OpenAI eksperymentowało z watermarkingiem, co ułatwiłoby późniejszą detekcję (Kirchenbauer et al. 2023). Gdyby twórcy modeli wprowadzili takie znaczniki, czasopisma mogłyby skanować nadesłane artykuły pod ich kątem. Niestety, łatwo je obejść, zwyczajnie przepisując wygenerowany tekst.
Otwartość i transparentność procesu badawczego
Wielu ekspertów wskazuje, że otwarta nauka może ograniczyć pole do nadużyć (WEB1). Jeżeli czasopisma będą wymagać udostępnienia surowych danych, kodu i szczegółowych protokołów badań jako warunku publikacji, oszustom będzie trudniej podrobić całe badania. Łatwiej zauważyć, że np. przedstawione dane są niekompletne lub niezgodne z opisem doświadczenia. Ponadto, promowanie publikacji negatywnych wyników i replikacji zniechęci do produkowania pozornie przełomowych odkryć – skoro i tak cenione będą solidne, weryfikowalne prace. Wreszcie, otwarte recenzje (jawność recenzentów i ich opinii) mogą zwiększyć odpowiedzialność obu stron i utrudnić działanie zorganizowanym fabrykom (trudniej „wcisnąć” fałszywkę, jeśli recenzje są publicznie dostępne).
Zmiany systemowe w ocenie naukowców
Długofalowo, społeczność naukowa musi zmierzyć się z kulturowym źródłem problemu: nadmierną fetyszyzacją liczby publikacji i „szybkiego’’ sukcesu. Reforma systemu ewaluacji – uwzględnienie jakości nad ilością, docenianie współpracy, danych, zasobów, a nie tylko artykułów – zmniejszyłaby popyt na usługi paper mills. Jeżeli awans naukowy nie będzie już uzależniony od publikacji za wszelką cenę, pokusa oszustwa osłabnie. To oczywiście trudne zadanie wymagające konsensusu instytucji finansujących i uczelni na całym świecie. Niemniej, pojawiają się inicjatywy typu DORA (San Francisco Declaration on Research Assessment) promujące taką zmianę kultury oceniania.
Edukacja i budowanie świadomości
Warto zainwestować w szkolenia młodych naukowców z zakresu etyki i dobrych praktyk publikacyjnych. Programy doktoranckie coraz częściej obejmują moduły o tym, jak rozpoznawać manipulacje, unikać uprzedzeń, poprawnie korzystać z AI jako narzędzia pomocniczego, a nie protezy badawczej. Istotne jest, by już na etapie studiów uświadamiać, że korzystanie z „gotowców” z internetu czy z generatorów tekstu bez włożenia własnej pracy to nie tylko ryzyko blamażu, ale i etyczne zaniedbanie wobec społeczności naukowej. Również wydawcy prowadzą kampanie informacyjne, publikują wytyczne i studia przypadków, które pokazują, jak wygląda typowy produkt paper mill i dlaczego stanowi zagrożenie. Przykłady głośnych wycofań artykułów czy nawet całych czasopism mogą tu działać odstraszająco.
Na koniec warto podkreślić, że walka z pseudonauką generowaną przez AI to zadanie wielostronne. Wymaga współpracy informatyków, wydawców, redaktorów, recenzentów i samych autorów. Takie inicjatywy już się pojawiają – choćby wspomniany STM Integrity Hub jest efektem konsorcjum wydawców dzielących się danymi o podejrzanych manuskryptach. Kluczowe jest też wsparcie instytucjonalne: agencje rządowe i organizacje grantowe (np. komisje ds. etyki w różnych krajach) mogą ustanowić jasne regulacje i sankcje za nadużycia z użyciem AI.
Warto zauważyć, że niektórzy komentatorzy zachowują umiarkowany optymizm: „poważni naukowcy raczej nie będą masowo korzystać z AI do oszustw, bo ryzyko wykrycia i konsekwencji jest zbyt duże”. Argumentują, że reputacja w nauce to waluta, której nie opłaca się niszczyć dla krótkotrwałego zysku (Else 2023). Mimo to, biorąc pod uwagę dotychczasowe doświadczenia z plagami plagiatów czy sfabrykowanych danych, społeczność naukowa woli nie pozostawiać spraw własnemu biegowi.
Wnioski
Zarówno paper mills, jak i generatywna AI stawiają przed nauką ogromne wyzwanie, które można porównać do walki społeczeństwa z fake newsami i deepfake’ami. Stawką jest wiarygodność wiedzy naukowej – fundament postępu i zaufania społecznego do ekspertów. Jeśli zalew syntetycznych prac podważy tę wiarygodność, konsekwencje odczujemy wszyscy: od spowolnienia rozwoju nauk medycznych po erozję oświeceniowego autorytetu nauki w debacie publicznej.
Jak jednak pokazaliśmy, istnieją konkretne kroki, które mogą zapobiec najgorszemu scenariuszowi. Po pierwsze, świat naukowy nie jest bezbronny – dysponujemy rosnącą świadomością problemu, wsparciem technologicznym (AI przeciwko AI) oraz sprawdzonymi metodami krzewienia etyki i transparentności. Po drugie, historia uczy, że nauka ma zdolność samonaprawy, gdyż wykrywanie i wycofywanie fałszywych publikacji już działają.
Nie oznacza to, że można zlekceważyć zagrożenie. Wręcz przeciwnie – musimy działać proaktywnie. Ustanowienie nowych standardów (dotyczących użycia AI), inwestycja w systemy weryfikacji oraz reforma oceny publikacji w nauce to elementy kompleksowej strategii. Wymaga ona globalnej współpracy: pojedyncze czasopismo czy uczelnia nie powstrzyma fali, ale skoordynowane działanie wielu podmiotów już może.
Podsumowując, paper mills i nadużycia LLM są dla nauki próbą charakteru. Czy obronimy integralność procesu naukowego w dobie coraz potężniejszych algorytmów? Ostatecznie to od ludzi zależy, jak wykorzystają AI – czy jako narzędzie wspierające twórczość i innowacje, czy jako drogę na skróty podkopującą sens pracy badawczej. Wybierając pierwszą z tych dróg i wdrażając opisane rozwiązania, możemy sprawić, że zamiast kryzysu wiarygodności czeka nas ewolucja praktyk naukowych, w której AI służy nauce, a nie jej szkodzi. Naszym zadaniem jest nie dopuścić, by ta pesymistyczna wizja spełniła się w świecie nauki.
Literatura
- Abalkina, A. (2023). Publication and collaboration anomalies in academic papers originating from a paper mill: Evidence from a Russia-based paper mill. Learned Publishing, 36(4), 689–702. https://doi.org/10.48550/arXiv.2112.13322
- Else, H. (2023). Abstracts written by ChatGPT fool scientists. Nature, 613(423), 516–519. https://doi.org/10.1038/d41586-023-00056-7
- Else, H., & Van Noorden, R. (2021). The fight against fake-paper factories that churn out sham science. Nature, 591(7851), 516–519. https://doi.org/10.1038/d41586-021-00733-5
- Jones, N. (2024). How journals are fighting back against a wave of questionable images. Nature, 626, 697-698. https://doi.org/10.1038/d41586-024-00372-6
- Kannan, P. (2024). How Much Research Is Being Written by Large Language Models?. HAI Stanford
- Katner, W. J. (2025). Tzw. punktoza jako pseudosystem oceny pracowników nauki mogący prowadzić do naruszenia ich dóbr osobistych. Przegląd Sądowy, 2025/2/7-23
- Kirchenbauer, J. et al. (2023). A Watermark for Large Language Models. PMLR. https://doi.org/10.48550/arXiv.2301.10226
- Liang, W. et al. (2024), Mapping the Increasing Use of LLMs in Scientific Papers. arXiv:2404.01268, https://doi.org/10.48550/arXiv.2404.01268
- Logan, S. W. (2024). Generative Artificial Intelligence Users Beware: Ethical Concerns of ChatGPT Use in Publishing Research. Journal of Motor Learning and Development, 12(3), 429-436. https://doi.org/10.1123/jmld.2024-0024
- McKie, R. (2024). ‘The situation has become appalling’: fake scientific papers push research credibility to crisis point. The Guardian.
- McLellan, T. (2025). Asian Tricks and Research Misconduct: From Orientalism and Occidentalism to Solidarity against Audit Cultures. East Asian Science, Technology and Society: An International Journal, 1–21. https://doi.org/10.1080/18752160.2025.2482324
- Sample, I. (2023). Science journals ban listing of ChatGPT as co-author on papers. The Guardian.
- Sanderson, K. (2024). Science’s fake-paper problem: high-profile effort will tackle paper mills. Nature, 626(7997), 17–18. https://doi.org/10.1038/d41586-024-00159-9
- Subbaraman, N. (2024). Exclusive: Flood of fake science forces multiple journal closures. Wall Street Journal.
- WEB1. The real threat of AI-Powered research paper mills to academic publishers
http://www.sagepub.com/explore-our-content/blogs/posts/asia-pacific-insights/2024/11/22/the-real-threat-of-ai-powered-research-paper-mills-to-academic-publishers