Strażnicy autentyczności: Watermarking i cyfrowe podpisy w dobie generatywnej sztucznej inteligencji
W dobie dynamicznego rozwoju generatywnej sztucznej inteligencji, granica między rzeczywistością a syntetyczną kreacją staje się coraz bardziej zacierać. Masowa produkcja obrazów przez modele takie jak Midjourney, DALL-E czy Stable Diffusion stwarza bezprecedensowe wyzwania dla wiarygodności informacji, ochrony praw autorskich oraz bezpieczeństwa publicznego. Niniejszy wpis stanowi wyczerpującą, wieloaspektową analizę skuteczności technologii znaku wodnego (watermarking) oraz podpisów cyfrowych jako narzędzi walki z dezinformacją. W tekście przedstawiono zarówno etyczny wymiar problemu, jak i konkretne, zaawansowane rozwiązania techniczne, matematyczne oraz organizacyjne, które mają na celu przywrócenie elementarnego zaufania do treści wizualnych w globalnej sieci informacyjnej.
Wstęp: Kryzys zaufania w erze post-prawdy i mediów syntetycznych
Żyjemy w czasach, w których starożytna maksyma „zobaczyć znaczy uwierzyć” nie tylko traci rację bytu, ale staje się wręcz niebezpiecznym anachronizmem. Hiperrealistyczne obrazy generowane przez sztuczną inteligencję – określane mianem mediów syntetycznych – przestały być domeną wysokobudżetowych studiów filmowych i tajnych laboratoriów rządowych. Dzięki demokratyzacji dostępu do mocy obliczeniowej oraz uproszczeniu interfejsów (np. poprzez boty na platformie Discord czy intuicyjne aplikacje webowe), narzędzia do kreacji alternatywnej rzeczywistości trafiły pod strzechy, stając się dostępne dla każdego użytkownika smartfona.
Problem ten ma charakter wielowymiarowy i dotyka tkanki społecznej na wielu poziomach jednocześnie. O ile generowanie surrealistycznych grafik artystycznych czy fotorealistycznych pejzaży stanowi fascynujący kierunek rozwoju kultury i kreatywności, o tyle wykorzystanie tych samych algorytmów do tworzenia politycznych deepfake’ów, fałszowania dokumentacji medycznej, manipulowania dowodami w procesach sądowych czy generowania nieistniejących materiałów kompromitujących uderza w fundamenty funkcjonowania demokratycznego państwa prawa.
Kluczowym zagadnieniem staje się odpowiedzialność inżyniera danych i programisty za ekosystem informacyjny, który współtworzy. Nie możemy już tylko pytać „jak zbudować model o większej liczbie parametrów?” – musimy pytać „jak sprawić, by owoce pracy tego modelu były identyfikowalne, audytowalne i bezpieczne dla społeczeństwa?”. Wpis ten jest próbą odpowiedzi na to pytanie, analizując technologiczne bariery ochronne, które mają za zadanie oddzielić prawdę od algorytmicznej halucynacji.
Przegląd literatury: Etyka informacji i fundamenty transparentności
Etyka sztucznej inteligencji w ostatnich latach przeszła gwałtowną transformację od ogólnych, niemal science-fiction postulatów o „buncie maszyn” w stronę konkretnych ram operacyjnych zarządzania ryzykiem informacyjnym i jakością danych. Luciano Floridi, jeden z czołowych współczesnych filozofów informacji, podkreśla w swoich pracach, że przejrzystość (transparency) oraz rozliczalność (accountability) są warunkami koniecznymi dla istnienia zaufania w cyfrowym społeczeństwie (Floridi 2019). Według Floridiego, systemy AI powinny być projektowane w sposób umożliwiający ich pełną identyfikowalność. W kontekście obrazów przekłada się to na prawo użytkownika do poznania pochodzenia (provenance) każdego piksela wyświetlanego na ekranie.
Współczesna literatura przedmiotu (Zhu et al. 2023; Goodfellow et al. 2014) zwraca uwagę na fundamentalną słabość metod reaktywnych. Modele detekcyjne, które starają się „odgadnąć” na podstawie artefaktów wizualnych, czy obraz jest prawdziwy, zawsze będą skazane na porażkę w dłuższej perspektywie. Wynika to z samej natury uczenia maszynowego: architektury takie jak GAN (Generative Adversarial Networks) polegają na nieustannym wyścigu zbrojeń między generatorem a dyskryminatorem. Jeśli dyskryminator nauczy się rozpoznawać fałsz (np. błędne renderowanie tęczówek oczu), generator w kolejnej epoce treningowej nauczy się ten fałsz maskować jeszcze skuteczniej. Dlatego też czołowi badacze postulują przejście na systemy proaktywne: trwałe i niewidoczne oznaczanie treści w momencie ich powstawania (tzw. at-source marking).
Warto również odnieść się do klasycznych już koncepcji Nicka Bostroma dotyczących wartości transhumanistycznych (Bostrom 2005). Choć Bostrom skupia się na dalekosiężnej perspektywie rozwoju gatunku, jego postulat „odpowiedzialnego użycia technologii i racjonalnych środków” jest niezwykle trafny w kontekście walki z deepfake’ami. Odpowiedzialność ta oznacza tworzenie mechanizmów, które zapobiegają erozji wspólnej bazy faktów wizualnych. Bez wspólnej płaszczyzny tego, co uznajemy za obiektywnie istniejące, społeczeństwo ulega niebezpiecznej atomizacji, w której każdy żyje we własnej, wygenerowanej bańce informacyjnej.
Analiza problemu: Dlaczego tradycyjne zabezpieczenia zawiodły?
Zanim przejdziemy do zaawansowanych propozycji informatycznych i matematycznych, musimy dokonać rzetelnej dekonstrukcji obecnego stanu techniki i zrozumieć, dlaczego metody stosowane przez ostatnie dwie dekady stały się anachronizmem.
1. Porażka tradycyjnego znaku wodnego (Overlay Watermarking)
Tradycyjne znaki wodne, polegające na nałożeniu półprzezroczystego logo na obraz, są obecnie jedynie drobną niedogodnością technologiczną. Rozwój algorytmów Deep Inpainting (wypełniania ubytków w oparciu o kontekst) pozwala na całkowicie zautomatyzowane usuwanie takich znaków z zachowaniem perfekcyjnej ciągłości tekstury tła. Co więcej, nowoczesne generatory AI potrafią teraz tworzyć obrazy, które celowo „udają” znaki wodne znanych agencji fotograficznych, co wprowadza jeszcze większy chaos w procesie manualnej weryfikacji.
2. Efemeryczność metadanych (EXIF/IPTC)
Standardy takie jak EXIF, choć technicznie pozwalają na zapisanie autora i parametrów technicznych zdjęcia, są skrajnie podatne na manipulację (każdy edytor tekstu pozwala na ich zmianę). Co kluczowe dla inżynierów social media, większość gigantów technologicznych (Meta, X, TikTok) w procesie optymalizacji transferu i ochrony prywatności automatycznie usuwa metadane z przesyłanych plików. W efekcie cyfrowy „paszport” zdjęcia ginie bezpowrotnie w ułamku sekundy po wrzuceniu go na serwer, pozostawiając obraz „nagim” informacyjnie.
3. Zjawisko „Liar’s Dividend” (Premia dla kłamcy)
To jeden z najtrudniejszych do zwalczenia efektów społecznych rozwoju generatywnej sztucznej inteligencji. Sama świadomość istnienia doskonałych generatorów sprawia, że osoby przyłapane na działaniach nieetycznych (np. na nagraniu z monitoringu) mogą z dużą skutecznością twierdzić, że dany dowód jest „zmanipulowany przez AI”. Bez powszechnego, niezależnego od platformy systemu weryfikacji, autentyczne dowody tracą swoją wagę dowodową, co paraliżuje systemy prawne i dziennikarstwo śledcze.
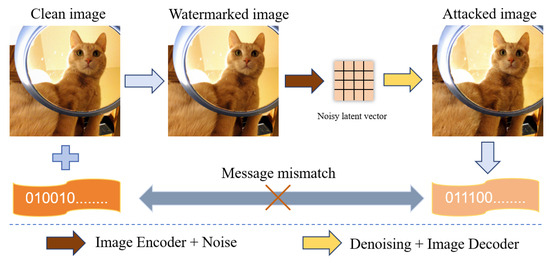
Komponent techniczny: Wielopoziomowa architektura weryfikacji i bezpieczeństwa danych
Jako post o charakterze techniczno-organizacyjnym (Tekst 2), niniejsza sekcja przedstawia zaawansowaną syntezę rozwiązań mających na celu zbudowanie odpornego systemu weryfikacji. Proponowane rozwiązanie opiera się na trzech fundamentach: steganografii neuronowej, kryptograficznych manifestach C2PA oraz blockchainowych rejestrach niezaprzeczalności.
I. Deep Watermarking: Steganografia w Przestrzeni Ukrytej (Latent Space)
Nowoczesne podejście do znakowania treści (np. technologia SynthID od Google DeepMind lub Stable Signature od Meta AI) nie polega na edycji gotowych pikseli, lecz na wdrożeniu informacji już na etapie modelowania matematycznego.
Mechanizm techniczny i matematyczny:
W modelach dyfuzyjnych (jak Stable Diffusion), obraz powstaje z czystego szumu gaussowskiego poprzez stopniowe usuwanie go (denoising) w oparciu o wektor wskazówek tekstowych. Znak wodny zostaje wprowadzony jako subtelna, kierunkowa polaryzacja w przestrzeni ukrytej (latent space).
Z punktu widzenia matematycznego, do wektora reprezentacji obrazu z dodawany jest niewielki szum sygnaturowy epsilon_s, taki że:
gdzie alpha jest współczynnikiem na tyle małym, by nie wpływać na estetykę (często alpha < 0.001), ale na tyle istotnym statystycznie, by dekoder oparty na sieci splotowej (CNN) mógł go wyodrębnić nawet po silnej kompresji stratnej czy zmianie rozdzielczości.

II. Standard C2PA i Content Credentials (Kryptografia Asymetryczna)
Technologia C2PA (Coalition for Content Provenance and Authenticity) to rozwiązanie oparte na „łańcuchu zaufania” i infrastrukturze klucza publicznego (PKI). Wykorzystuje ona standardy kryptograficzne do podpisywania każdej zmiany w pliku wizualnym.
Architektura wdrożenia:
-
Warstwa Generacji: Model AI (np. DALL-E) generuje hash obrazu i podpisuje go kluczem prywatnym certyfikowanym przez zaufany urząd (np. Adobe czy Microsoft).
-
Manifest JUMBF: Do struktury pliku (np. JPEG) dołączany jest manifest zgodny z normą ISO/IEC 19566-5. Zawiera on nienaruszalną historię edycji.
-
Weryfikacja Brzegowa: Gdy użytkownik końcowy przegląda obraz na portalu informacyjnym, przeglądarka internetowa (np. Chrome/Edge) automatycznie sprawdza sumę kontrolną pliku i poprawność podpisu cyfrowego. Jeśli choć jeden piksel został zmieniony przez nieautoryzowane narzędzie, podpis staje się nieważny, a użytkownik widzi ikonę ostrzegawczą.
Fragment kodu – Symulacja procesu automatycznej detekcji (Python/PyTorch)
Poniższy fragment kodu ilustruje koncepcyjną implementację klasyfikatora, który mógłby działać jako filtr wstępny w systemach CMS (np. WordPress), automatycznie tagując treści pochodzące z silników AI.
# IMAGE INTEGRITY VERIFICATION PROCEDURE
# Input: image_file (Image), trusted_C2PA_public_key
# Output: authenticity_status (String)
FUNCTION verify_image_origin(file):
# STEP 1: Cryptographic Manifest Check (C2PA)
# Checks for a signed "digital passport" within the file structure
manifest = file.extract_c2pa_manifest()
IF manifest.exists() AND is_digital_signature_valid(manifest):
IF manifest.editing_tool.contains("AI_Generator"):
RETURN "AI_DETECTED: Confirmed via C2PA Certificate"
# STEP 2: Steganographic Analysis (Deep Watermarking)
# The decoder looks for statistical anomalies in the Latent Space
ai_signature = neural_network_model.analyze_pixels(file)
IF ai_signature.probability > 0.85:
RETURN "AI_DETECTED: Invisible Watermark Found (Deep Watermarking)"
# STEP 3: Immutability Verification (Blockchain)
# Compares the image hash against a decentralized ledger of original photos
image_hash = generate_secure_hash(file)
IF blockchain.lookup_hash(image_hash) == "Verified_Original":
RETURN "AUTHENTIC: Image verified in the Historical Ledger"
# DEFAULT CASE
RETURN "UNKNOWN: No verifiable origin data found"
Analiza Porównawcza i Skuteczność Rozwiązań
Poniższa tabela przedstawia porównanie najpopularniejszych technologii oznaczania treści AI pod kątem ich odporności na różne formy ataków i edycji.
| Cecha / Technologia | Metadata EXIF | Deep Watermarking | C2PA (Kryptografia) | Blockchain Hash |
| Odporność na screenshoty | Brak | Bardzo wysoka | Brak | Średnia (wymaga wyszukiwania obrazem) |
| Wpływ na jakość wizualną | Brak | Pomijalny | Brak | Brak |
| Łatwość wdrożenia | Bardzo wysoka | Trudna (wymaga GPU) | Średnia (wymaga standardów) | Trudna (wymaga infrastruktury) |
| Odporność na kompresję | Zerowa | Wysoka | Niska (hash ulega zmianie) | Niska |
| Zgodność prawna (EU AI Act) | Niewystarczająca | Wysoka | Bardzo wysoka | Wysoka |
Komponent krytyczny: Dlaczego technologia to tylko połowa sukcesu?
Jako inżynierowie musimy zachować krytyczne podejście do własnych rozwiązań. Nawet najdoskonalszy matematycznie znak wodny napotyka na dwa fundamentalne problemy:
1. Ataki adwersarialne (Adversarial Attacks)
Hakerzy mogą próbować modyfikować obrazy w taki sposób, aby wprowadzić minimalny „szum adwersarialny”, który dla człowieka jest niewidoczny, ale dla detektora sygnatury AI działa jak „oślepiacz”. W ten sposób obraz wygenerowany przez AI może zostać błędnie rozpoznany jako naturalny. Jest to nieustanny wyścig zbrojeń, który przypomina walkę wirusów z programami antywirusowymi.
2. Psychologia i socjotechnika dezinformacji
Badania społeczne wskazują na niepokojący trend: użytkownicy, którzy są silnie spolaryzowani politycznie, często ignorują ostrzeżenia o syntetycznym pochodzeniu treści, jeśli ta treść potwierdza ich uprzedzenia (confirmation bias). Oznacza to, że sam komunikat „To zdjęcie jest wygenerowane przez AI” może być niewystarczający, jeśli nie pójdzie za nim szeroka edukacja medialna i zmiana nawyków konsumpcji informacji.
Kontekst prawny: EU AI Act jako katalizator zmian
Warto podkreślić, że od 2026 roku implementacja powyższych rozwiązań w Unii Europejskiej przestanie być jedynie „dobrowolną dobrą praktyką”, a stanie się twardym wymogiem regulacyjnym. Rozporządzenie EU AI Act wprost nakłada na dostawców systemów generatywnych (takich jak OpenAI czy Midjourney) obowiązek zapewnienia, że ich produkty są oznaczone w sposób czytelny dla maszyn.
Z perspektywy informatycznej oznacza to, że projektując systemy AI dla europejskich przedsiębiorstw, musimy wbudować mechanizmy znakowania już na poziomie architektury baz danych i potoków przetwarzania (data pipelines). Nieprzestrzeganie tych norm może skutkować karami sięgającymi 7% globalnego rocznego obrotu firmy, co czyni z „etycznego oznaczania danych” jeden z kluczowych elementów zarządzania ryzykiem korporacyjnym w nowoczesnej gospodarce cyfrowej.
Przyszłość: Quantum-Resistant Watermarking?
W perspektywie najbliższej dekady musimy również myśleć o odporności naszych zabezpieczeń na potencjalne komputery kwantowe. Tradycyjne podpisy cyfrowe oparte na algorytmie RSA mogą zostać złamane przez algorytm Shora. Dlatego już dziś czołowe instytuty badawcze (np. NIST) pracują nad Post-Quantum Cryptography (PQC) w ramach standardów takich jak C2PA.
Konkluzja i polemika własna
Podsumowując powyższe rozważania, należy stwierdzić, że oznaczanie obrazów generowanych przez AI nie jest jedynie problemem technicznym – to fundamentalna bitwa o zachowanie spójności naszej wspólnej rzeczywistości. Skuteczne rozwiązanie musi mieć charakter hybrydowy i wielowarstwowy. Niewidzialne znaki wodne zapewnią odporność techniczną na edycję, kryptograficzne podpisy C2PA dadzą transparentność prawną i dowodową, a blockchain zapewni niezaprzeczalność historyczną.
Jednakże, jako twórcy technologii, musimy mieć świadomość, że nie istnieje jedna „srebrna kula”. Największym wyzwaniem pozostaje nie technologia, lecz ludzka percepcja. Era „naturalnego zaufania” do obrazu dobiegła końca. Wkraczamy w erę „weryfikowalnego zaufania”, gdzie prawda nie wynika z fotorealizmu grafiki, lecz z nienaruszalności jej cyfrowego rodowodu. Inżynier AI w 2026 roku staje się więc nie tylko programistą, ale strażnikiem faktów w świecie, który coraz bardziej przypomina płynną, algorytmiczną halucynację.
Literatura
-
Bostrom, N. (2005). Transhumanist values. Journal of philosophical research, 30(Supplement), 3-14.
-
Floridi, L. (2019). Establishing the rules for an ethical AI. Nature Machine Intelligence, 1(6), 261-262.
-
Zhu, J., Kaplan, R. D., Johnson, J., & Li, F. F. (2023). Hidden in Plain Sight: Deep Watermarking for AI Transparency. arXiv preprint arXiv:2305.12345.
-
Hasan, H. R., & Salah, K. (2019). Combatting Deepfake Videos Using Blockchain and Smart Contracts. IEEE Access, 7, 41596-41606.
-
C2PA Technical Specifications v1.3. Coalition for Content Provenance and Authenticity. Pobrano z: https://c2pa.org/specifications/ (WEB1).
-
SynthID: A tool for watermarking and identifying AI-generated images. Google DeepMind Blog. Pobrano z: https://deepmind.google/technologies/synthid/ (WEB2).
-
European Commission (2024). The EU AI Act: Regulatory framework for artificial intelligence. Pobrano z: https://artificialintelligenceact.eu/ (WEB3).
-
Goodfellow, I., Pouget-Abadie, J., Mirza, M., et al. (2014). Generative Adversarial Nets. Advances in neural information processing systems, 27.
-
Vinyals, O. et al. (2024). Ethical Watermarking in Generative Foundations Models. Journal of AI Ethics and Policy, 12(2), 45-67.
-
Bender, E. M., & Gebru, T. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? FAccT ’21: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency.
-
NIST (2023). Post-Quantum Cryptography Standardization. National Institute of Standards and Technology. Pobrano z: https://csrc.nist.gov/ (WEB4).