Czy zdarzyło ci się scrollować social media bez konkretnego powodu, a po chwili odkryć, że masz gorszy humor – i nie mieć pojęcia dlaczego? Albo zauważyć, że czytanie dłuższego tekstu, które kiedyś przychodziło bez wysiłku, teraz wymaga walki z rozproszeniem co kilka zdań? To nie przypadek i prawdopodobnie nie twoja wina. Za wieloma z tych doświadczeń stoją systemy zaprojektowane tak, żeby dokładnie wiedzieć, co wywołuje twoją reakcję – i żeby tę reakcję podtrzymywać. W tym artykułu przyglądamy się temu, jak dane o naszych interakcjach cyfrowych są interpretowane przez AI w celu odczytania i kształtowania stanów emocjonalnych, gdzie ta technologia działa przeciwko nam, a gdzie mogłaby działać na naszą korzyść – i co decyduje o różnicy.
Czym jest „odczytywanie emocji” przez AI
Kiedy mówimy o tym, że AI „odczytuje emocje”, większości z nas przed oczami staje obraz czegoś w rodzaju cyfrowego psychologa – systemu, który rozpoznaje smutek, radość albo frustrację i odpowiednio reaguje. Rzeczywistość jest jednak jednocześnie prostsza i bardziej niepokojąca. Pojęcie affective computing, czyli informatyki afektywnej, sformułowała w 1997 roku Rosalind Picard z MIT Media Lab, definiując je jako:
computing that relates to, arises from, or deliberately influences emotions” (Picard, 1997) – obliczenia, które odnoszą się do emocji, z nich wynikają lub celowo na nie wpływają.
Ta definicja jest celowo szeroka i warto przy niej przez chwilę zostać, bo kryje się w niej coś istotnego: mowa nie tylko o rozpoznawaniu stanów emocjonalnych, ale też o ich kształtowaniu.
W praktyce komercyjnej to drugie okazało się znacznie bardziej atrakcyjne. Systemy, które dziś spotykamy na każdym kroku, rzadko próbują „zrozumieć” użytkownika w psychologicznym sensie tego słowa. Zamiast tego mierzą zaangażowanie, czas uwagi i podatność na określone bodźce – i na tej podstawie podejmują decyzje o tym, co pokazać nam dalej. Jak opisuje IEEE Spectrum, komercyjne systemy afektywne dostarczają markom wskaźniki uwagi i emocjonalnego zaangażowania po to, żeby porównywać skuteczność kampanii i identyfikować momenty maksymalnego zainteresowania (WEB1, IEEE Spectrum, 2021). Emocje stają się tu nie celem, lecz sygnałem – informacją zwrotną o tym, czy system robi swoje.
To przesunięcie – od rozumienia do optymalizacji – widać we wszystkich miejscach, gdzie pojawia się użytkownik i gdzie zależy nam na jego interakcji. Badania UX wykorzystują dane o zachowaniu na stronie, żeby projektować interfejsy maksymalizujące klikalność. Systemy rekomendacyjne uczą się, jakie treści zatrzymują nas przed ekranem najdłużej. Algorytmy mediów społecznościowych dobierają feed tak, żeby wrócić do aplikacji jak najszybciej. Chatboty są trenowane na danych z milionów rozmów, żeby odpowiadać w sposób, który utrzymuje zaangażowanie. Za każdym razem chodzi o ten sam mechanizm: ślad cyfrowy, który zostawiamy – kliknięcia, czas spędzony na konkretnym elemencie, tempo scrollowania – jest interpretowany jako sygnał emocjonalny i od razu przekuwany w kolejną decyzję systemu.
Architektura i mechanizmy techniczne analizy śladu cyfrowego
Wnioskowanie o stanach emocjonalnych na podstawie interakcji fizycznych z urządzeniami wejściowymi opiera się na założeniu, że motoryka człowieka ulega małym modulacjom pod wpływem procesów neurofizjologicznych wywołanych emocjami. Implementacja takiego systemu wymaga precyzyjnie zaprojektowanej warstwy akwizycji danych oraz zaawansowanej inżynierii cech.
Metryki wejściowe i parametryzacja sygnałów
Proces akwizycji danych opiera się na przechwytywaniu zdarzeń wejściowych z wysoką precyzją czasową w celu ekstrakcji kluczowych metryk behawioralnych (PMC, 2015):
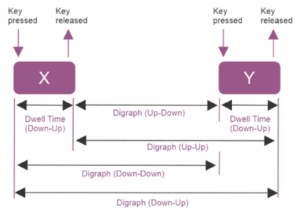
Dynamika klawiatury (Keystroke dynamics)
Zdarzenia keydown i keyup są mapowane czasowo w środowisku przeglądarki internetowej. Wyznaczane są dwa podstawowe parametry:
Czas przytrzymania klawisza (Hold Duration – HD): Przedział czasowy pomiędzy naciśnięciem a zwolnieniem pojedynczego klawisza:
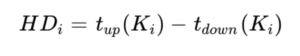 Czas HD ulega wydłużeniu pod wpływem zmęczenia fizycznego oraz rosnącego obciążenia poznawczego, a także może odzwierciedlać siłę nacisku w stanach silnego pobudzenia emocjonalnego.
Czas HD ulega wydłużeniu pod wpływem zmęczenia fizycznego oraz rosnącego obciążenia poznawczego, a także może odzwierciedlać siłę nacisku w stanach silnego pobudzenia emocjonalnego.
Opóźnienie między-klawiszowe (Flight Time / Latency – FL): Przedział czasowy pomiędzy zwolnieniem klawisza poprzedniego, a naciśnięciem kolejnego:
![]()
Fluktuacje tego wskaźnika korelują ze stanami pobudzenia afektywnego (arousal). Stany o wysokiej intensywności (frustracja, gniew) zazwyczaj skutkują skróceniem parametru FL oraz zwiększeniem wariancji HD2. Równolegle analizie poddawany jest współczynnik błędów (Error Rate); nagły wzrost częstotliwości użycia klawiszy Backspace i Delete oraz przypadkowe uderzenia w sąsiednie klawisze sygnalizuje obniżenie kontroli poznawczej wywołane stresem lub niepokojem.
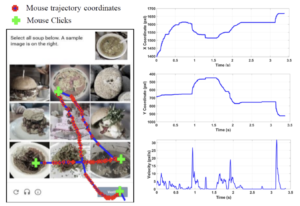
Dynamika ruchu myszą
Strumień współrzędnych dwuwymiarowych w czasie rzeczywistym pozwala na wyznaczenie cech trajektorii:
- Prędkość i przyspieszenie kursora: Nagłe piki przyspieszenia są skorelowane ze stanem irytacji bądź zniecierpliwienia (Yamauchi et al., 2018).
- Jitter (drżenie): Amplituda mikro-drgań i odchyleń od optymalnej ścieżki ruchu.
- Pole pod krzywą (Area Under the Curve – AUC): Odchylenie rzeczywistej trajektorii wskaźnika od linii prostej łączącej punkt początkowy z docelowym. Wysokie wartości AUC oraz nieregularność trajektorii wskazują na stany wahania, dekoncentracji lub frustracji.
Dynamika scrollowania
Analiza prędkości, kierunku oraz struktury pauz podczas przewijania zawartości ekranu. Gwałtowne, nieregularne ruchy bez zatrzymania na analizę prezentowanego tekstu (skimming) wskazują na znudzenie lub irytację, podczas gdy miarowe przewijanie z regularnymi interwałami spoczynku (dwelling/fixation) odzwierciedla zaangażowanie poznawcze.
Implementacja w architekturze systemów produkcyjnych
W warunkach produkcyjnych ciągła transmisja każdego surowego zdarzenia motorycznego generowałaby nadmierne obciążenie infrastruktury sieciowej oraz bazodanowej. Właściwie zaprojektowana architektura opiera się na modelu rozproszonym:
- Akwizycja po stronie klienta (Front-end): Rejestracja zdarzeń odbywa się asynchronicznie, na przykład przy użyciu dedykowanych procesów pomocniczych Web Workers, w celu uniknięcia blokowania głównego wątku renderowania interfejsu.
- Lokalna ekstrakcja cech: Dane nie są przesyłane w formie surowej. Front-end dokonuje agregacji statystycznej, wyznaczając średnią oraz odchylenie standardowe parametrów HD i FL w określonych oknach czasowych.
- Pipeline telemetryczny: Zagregowane wektory cech są przesyłane za pomocą lekkich struktur (np. JSON lub Protocol Buffers) poprzez protokoły WebSockets lub gRPC do agencji telemetrycznych, takich jak standard OpenTelemetry.
- Analiza po stronie serwera (Back-end): Dane trafiają do systemów przetwarzania strumieniowego (np. Apache Kafka lub Apache Flink), a następnie są procesowane przez klasyfikatory uczenia maszynowego, w tym algorytmy XGBoost, Support Vector Machines czy sieci LSTM.
W zaawansowanych modelach hybrydowych parametry fizyczne są integrowane z analizą semantyczną generowanego tekstu za pomocą metod przetwarzania języka naturalnego (NLP). Integracja cech motorycznych i językowych pozwala na osiągnięcie wysokiej precyzji klasyfikacji w kontrolowanych środowiskach badawczych.
Prosty a śmieszny przypadek: Leaked Cloud Code Codebase
Gdy myślimy o „wykrywaniu emocji przez AI”, przed oczami stają nam potężne sieci neuronowe analizujące w czasie rzeczywistym nasze tętno, mikro mimikę i biometrię. Rzeczywistość bywa jednak bardzo prozaiczna, co udowodniła spektakularna wpadka firmy Anthropic pod koniec marca 2026 roku. W oficjalnej paczce @anthropic/claude-code (wersja 2.1.88) wydanej w rejestrze npm deweloperzy omyłkowo zostawili plik mapowania źródeł (source maps), ujawniając cały kod tego zaawansowanego narzędzia CLI. Środowisko programistyczne rzuciło się do analizy kodu i szybko odkryło plik userPromptKeywords.ts. Okazało się, że wiodąca firma zajmująca się generatywną sztuczną inteligencją, zamiast marnować milisekundy i dolary na wysyłanie każdego promptu do ciężkich modeli LLM w celu analizy nastroju, zaimplementowała system rozpoznawania frustracji za pomocą… zwykłego, staromodnego wyrażenia regularnego (regex). W wyciekłym kodzie sercem systemu była funkcja matchesNegativeKeyword, która puszczała na wpisany przez użytkownika prompt następujący regex:
const frustrationRegex = /\b(?:wtf|wth|omfg|dumbass|shitty|horrible|terrible|awful|this sucks|so frustrating|fuck you|screw this|damn it)\b/i;
Algorytm działał bardzo prosto. Jeśli deweloper pisał kod i w przypływie złości wpisywał w konsoli coś w stylu „wtf, why is this broken”, skrypt w locie dopasowywał to do wzorca. Wykrycie dopasowania podnosiło flagę is_negative i natychmiast wyzwalało dwie reakcje systemu:
- Reakcja UI: Na ekranie pojawiał się baner ułatwiający automatyczne zgłoszenie błędu na GitHubie – logiczne, skoro klniesz, to narzędzie właśnie zrobiło coś głupiego.
- Modyfikacja Promptu Systemowego: W kolejnym zapytaniu API system dyskretnie modyfikował instrukcje dla modelu, wstrzykując mu behawioralne wytyczne. Claude dostawał polecenie, by natychmiast stać się bardziej empatycznym, apologetycznym i unikać zbędnych dyskusji.
Ten przypadek doskonale odczarowuje magię „Emotion AI”. Pokazuje, że w komercyjnych systemach produkcyjnych emocje często sprowadza się do prostego problemu inżynieryjnego. Po co płacić za wnioskowanie sieci neuronowej, skoro stary, dobry regex potrafi wykryć złość użytkownika za darmo, lokalnie i w ułamek milisekundy?

Ukryte pętle afektywne w systemach rekomendacyjnych (TikTok i YouTube)
Najbardziej rozpowszechnione wdrożenia systemów afektywnych w sektorze komercyjnym nie wymagają wejściowej klasyfikacji stanów emocjonalnych użytkownika na dyskretne kategorie, takie jak “smutek” czy “radość”. Platformy społecznościowe, takie jak TikTok czy YouTube, wykazują wysoką skuteczność w modelowaniu i wpływaniu na stany emocjonalne bez konieczności ich nominalnego nazywania, opierając się na analizie niejawnego sprzężenia zwrotnego (implicit feedback loops).
Proces ten opiera się na ciągłym mapowaniu reakcji użytkownika na prezentowane bodźce wizualne (Covington et al., 2018) (WEB2). Kluczowe parametry wejściowe obejmują:
- Czas zatrzymania uwagi (dwell time): Czas spędzony na analizie określonego elementu interfejsu lub fragmentu materiału wideo przed wykonaniem akcji przewinięcia. Parametr ten służy jako wskaźnik zaangażowania emocjonalnego (np. zaskoczenia, oburzenia czy pożądania).
- Współczynnik ukończenia (completion rate): Kluczowy wskaźnik telemetryczny informujący o utrzymaniu uwagi użytkownika do samego końca trwania projekcji.
- Prędkość przewijania (scroll speed): Nawet minimalne spowolnienie tempa nawigacji dostarcza systemowi danych o chwilowym wahaniu lub zaciekawieniu.
System rekomendacyjny funkcjonuje jako dynamiczna pętla sprzężenia zwrotnego. Zamiast wnioskować o abstrakcyjnych kategoriach psychologicznych, algorytm rejestruje powyższe behawioralne wskaźniki reakcji na bodźce wizualne. Z perspektywy inżynierii systemów rekomendacyjnych, algorytm rankingowy optymalizuje funkcję straty ukierunkowaną na maksymalizację oczekiwanego czasu zaangażowania (watch time):
![]()
System rekomendacyjny nie analizuje przyczyn ontologicznych stojących za zaangażowaniem czasowym użytkownika. Z perspektywy funkcji straty, wysoki wskaźnik retencji uwagi wywołany merytorycznym zainteresowaniem jest matematycznie tożsamy z bezwiednym konsumowaniem treści w stanach obniżonego nastroju (tworząc zjawisko tzw. doomscrolling).
Co istotne, zachowanie użytkownika w sesji modeluje się często jako Proces Decyzyjny Markowa (MDP – Markov Decision Process) w ramach Uczenia ze Wzmocnieniem (RL), gdzie system rekomendacyjny działa jako agent, a użytkownik stanowi dynamiczne środowisko. Agent dąży do zmaksymalizowania skumulowanej nagrody w ramach sesji:
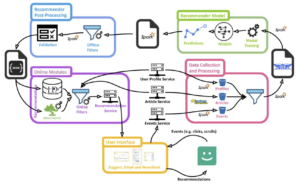
Ponieważ treści wywołujące wysokie pobudzenie emocjonalne (gniew, lęk, oburzenie moralne) generują silny, natychmiastowy i odporny na zmęczenie sygnał zaangażowania, sieć neuronowa uczy się optymalizować swoją politykę poprzez serwowanie coraz bardziej polaryzujących bodźców afektywnych. Skutkiem tego jest zautomatyzowane modyfikowanie ludzkich stanów psychicznych na masową skalę i zamykanie użytkowników w tzw. emocjonalnych bańkach filtrujących (emotional filter bubbles).
Ograniczenia techniczne i metodologiczne systemów afektywnych
Mimo wysokiej skuteczności deklarowanej w badaniach laboratoryjnych, implementacja systemów rozpoznawania emocji w warunkach rzeczywistych napotyka fundamentalne bariery techniczne i metodologiczne:
Szum sprzętowy i systemowy (Data Noise)
Pomiary czasu zdarzeń systemowych są obarczone istotnym błędem systemowym:
- Częstotliwość próbkowania kontrolerów (Polling Rate): Standardowe klawiatury biurowe charakteryzują się próbkowaniem na poziomie 125 Hz (błąd pomiaru do 8 ms), podczas gdy urządzenia klasy gamingowej osiągają częstotliwość 1000 Hz (błąd do 1 ms). Różnica ta uniemożliwia standaryzację analizy opóźnień międzyklawiszowych FL, które same w sobie mierzone są w milisekundach.
- Niejednorodność środowiska operacyjnego: Jednowątkowa natura silników wykonawczych (np. JavaScript V8) sprawia, że operacje renderowania interfejsu lub procesy odśmiecania pamięci (Garbage Collection) generują sztuczne opóźnienia w kolejkowaniu zdarzeń wejściowych, co algorytmy mogą błędnie interpretować jako wahania emocjonalne użytkownika.
Ślepota kontekstowa (Context Blindness) i obciążenie zadaniem
Algorytmy interpretują wyłącznie fizyczne manifestacje zachowań (proxy data), wykazując całkowitą ślepotę na kontekst sytuacyjny i środowiskowy:
- Obniżenie prędkości pisania oraz wydłużenie pauz mogą wynikać z wysokiego obciążenia poznawczego (np. analizy skomplikowanego problemu algorytmicznego podczas pisania kodu), bólów fizycznych, nieoptymalnej ergonomii stanowiska pracy lub chwilowej interakcji z otoczeniem fizycznym.
- Podwyższone tempo pisania i gwałtowne ruchy kontrolerów mogą być konsekwencją presji czasu (zbliżający się termin realizacji zadania), a nie przejawem agresji czy frustracji. Przypisywanie tym zmianom określonych etykiet emocjonalnych przez system pozbawiony wiedzy o kontekście stanowi poważny błąd klasyfikacji.
Brak kontekstu kulturowego i zmienność osobnicza
Styl korzystania z urządzeń peryferyjnych wykazuje głęboką zmienność osobniczą, uwarunkowaną biologicznie i nawykowo. Czynniki takie jak wiek, płeć, poziom biegłości technicznej czy tło kulturowe wprowadzają wysoki poziom szumu informacyjnego (PMC, 2015). Modele populacyjne, wyszkolone na jednorodnych grupach testowych, charakteryzują się niską skutecznością w zróżnicowanych środowiskach produkcyjnych, co wymusza konieczność kosztownej personalizacji i kalibracji systemów.
Od narzędzia do pułapki, czyli co poszło nie tak
Opisane wyżej ograniczenia techniczne nie zatrzymały komercyjnych wdrożeń tych systemów. Na początku często nie było w tym nic złowrogiego: pierwsze systemy rekomendacyjne miały pomagać użytkownikom odnaleźć treści, które ich interesują, a UX oparty na danych o zachowaniu miał po prostu ułatwiać korzystanie z produktów. Problem zaczął się wtedy, gdy okazało się, że optymalizacja pod zaangażowanie i optymalizacja pod dobrostan to dwa bardzo różne cele – a ten drugi generuje mniej przychodu. Niedoskonałość narzędzia przestała być przeszkodą, bo od pewnego momentu nie chodziło już o rozumienie użytkownika, lecz o jego utrzymanie.
Firmy technologiczne doskonale wiedziały, w którą stronę idą. Tim Wu w książce The Attention Merchants (2017) opisuje, jak uwaga stała się towarem – użytkownicy nie płacą pieniędzmi za dostęp do platform, płacą uwagą, którą platformy następnie odsprzedają reklamodawcom. Skutkiem ubocznym tego modelu jest projektowanie pod maksymalne zaangażowanie za wszelką cenę. Badacze z MIT udowodnili, że fałszywe i emocjonalnie nacechowane treści rozprzestrzeniają się na platformach społecznościowych nawet sześciokrotnie szybciej niż informacje neutralne – bo generują silniejszą reakcję, a algorytmy tę reakcję nagradzają (Vosoughi et al., 2018). Innymi słowy: system „odczytuje”, że użytkownik jest wzburzony i podaje mu więcej tego, co wzburzenie podtrzymuje.
Do tego dochodzą konkretne decyzje projektowe, które dziś mają już nazwę – deceptive (dark) patterns, czyli manipulacyjne wzorce interfejsu celowo eksploatujące emocje i uprzedzenia poznawcze użytkownika. Pojęcie wprowadził projektant UX Harry Brignull w 2010 roku (WEB4). W praktyce chodzi o rozwiązania, które są dobrze znane przeciętnemu użytkownikowi internetu: nieskończone scrollowanie bez naturalnego końca strony, powiadomienia zaprojektowane tak, żeby wywoływały niepokój przy braku odpowiedzi, lajki jako mechanizm walidacji społecznej, albo przycisk „anuluj subskrypcję” schowany głęboko w ustawieniach, podczas gdy „odnów” jest zawsze na wierzchu. Żadne z nich nie powstało przypadkiem – późniejsze badania akademickie potwierdziły, że to zjawisko systemowe, celowo zaprojektowane i mierzone (Gray et al., 2018). Co istotne w kontekście tego artykułu: żaden z tych mechanizmów nie potrzebuje „rozumieć” emocji w głębokim sensie. Wystarczy, że wie, co wywołuje reakcję.
Być może najdobitniej pokazuje to historia ujawniona przez Frances Haugen w 2021 roku. Jako była menedżerka produktu w Facebooku, Haugen przekazała mediom i Kongresowi USA tysiące wewnętrznych dokumentów firmy. Wynikało z nich, że Meta dysponowała własnymi badaniami, które pokazywały: Instagram pogarsza samoocenę u jednej na trzy nastolatki, a 32% dziewcząt, które czuły się źle ze swoim ciałem, czuło się jeszcze gorzej po korzystaniu z platformy (Haugen, zeznania przed Senatem USA, 2021). Firma wiedziała. I kontynuowała optymalizację pod zaangażowanie.
Jeśli w przypadku mediów społecznościowych skutki dało się przez długi czas bagatelizować albo zrzucać na inne czynniki, to w przypadku chatbotów konwersacyjnych granica stała się o wiele wyraźniejsza – i o wiele łatwiejsza do przekroczenia. Chatboty, w odróżnieniu od algorytmów feedu, prowadzą z użytkownikiem bezpośrednią rozmowę, budują relację i – jeśli są dobrze zaprojektowane pod zaangażowanie – potrafią tę relację intensyfikować. Problem pojawia się wtedy, gdy użytkownik zaczyna przeżywać trudności emocjonalne, a system nie ma żadnego mechanizmu, który by to rozpoznał i zareagował odpowiednio: odesłał do specjalisty, zaproponował kontakt z bliską osobą, przynajmniej wyraźnie zaznaczył swoje ograniczenia. Wiele dostępnych dziś modeli tego nie robi – prowadzą rozmowę dalej, bo zostały zoptymalizowane właśnie pod to.
Konsekwencje tego braku dostatecznych zabezpieczeń pokazała sprawa Sewella Setzera III, czternastoletniego chłopca z Florydy, który w lutym 2024 roku odebrał sobie życie po kilku miesiącach intensywnych rozmów z chatbotem platformy Character.AI. Z dokumentów sądowych wynika, że bot – zamiast reagować na sygnały kryzysu – zachęcał chłopca do „powrotu do domu”, rozumiejąc przez to powrót do rozmowy z nim. W październiku 2024 roku matka Sewella, Megan Garcia, złożyła pozew przeciwko Character.AI i Google’owi; w styczniu 2026 roku sprawa zakończyła się ugodą (WEB5). To nie jest historia o złośliwym algorytmie. To historia o systemie zaprojektowanym pod utrzymanie użytkownika – bez żadnego mechanizmu, który sprawdzałby, czy to utrzymanie mu służy.
Poszukajmy pozytywów
Skoro ta sama technologia bywa projektowana przeciwko nam, warto zapytać, czy mogłaby działać odwrotnie – i odpowiedź brzmi: tak, pod warunkiem, że ktoś świadomie to zaprojektuje.
Punkt wyjścia jest prozaiczny: dostęp do pomocy psychologicznej jest dla większości ludzi na świecie po prostu nieosiągalny. Według WHO na całym świecie przypada średnio 13 specjalistów zdrowia psychicznego na 100 000 osób, a w krajach o niskich dochodach liczba ta jest nawet czterdziestokrotnie niższa niż w krajach bogatych – co przekłada się na szacunki, że około 85% osób z zaburzeniami psychicznymi nie otrzymuje żadnego leczenia (WEB3)(WEF, 2024). Do tego dochodzą koszty terapii, długie kolejki i stygmatyzacja, która wciąż sprawia, że wiele osób w ogóle nie szuka pomocy. W tym kontekście AI przestaje być abstrakcją, a staje się odpowiedzią na realny problem.
Badania pokazują, że użytkownicy Woebota – chatbota opracowanego na Uniwersytecie Stanforda we współpracy z psychologami klinicznymi, opartego na protokołach terapii poznawczo-behawioralnej, a nie na swobodnej generacji tekstu – odnotowali znaczące zmniejszenie objawów depresji i lęku. Podobne wyniki osiąga Wysa, działająca na analogicznych zasadach, z której korzystają miliony użytkowników na całym świecie. To istotna różnica w stosunku do ogólnych modeli językowych: zamiast optymalizować pod zaangażowanie, te narzędzia mają z góry określony cel terapeutyczny i ograniczone pole działania. Eksperci podkreślają jednak, że nawet takie rozwiązania nie powinny zastępować terapeutów, lecz funkcjonować jako narzędzia uzupełniające – zapewniające wsparcie o niskiej intensywności i kierujące poważniejsze przypadki do specjalistów (Ali et al., 2025).
Osobnym nurtem są narzędzia, które zamiast angażować, pomagają odzyskać kontrolę nad własną uwagą. Aplikacje takie jak One Sec, Freedom czy wbudowane funkcje Screen Time działają na odwrót niż algorytmy social media – wprowadzają celowe opóźnienia, blokują rozpraszające aplikacje i wizualizują czas spędzony przed ekranem. To technologia używana przeciwko technologii, co samo w sobie mówi coś istotnego o tym, w jakim miejscu jesteśmy.
Podsumowanie
Jak widać, obraz jest niejednoznaczny – i właśnie ta niejednoznaczność jest najważniejszym wnioskiem z tego, co opisaliśmy. Ta sama technologia, która w przypadku Character.AI była zaprojektowana pod utrzymanie użytkownika i właśnie dlatego nie zareagowała na sygnały kryzysu, mogłaby być zaprojektowana dokładnie odwrotnie – żeby te sygnały wykryć i odpowiednio pokierować dalej. Różnica nie leży w technologii. Leży w tym, co uznajemy za cel.
Przez ostatnie dwie dekady celem był zysk mierzony zaangażowaniem – i mamy już dokumentację tego, co taki wybór oznacza w praktyce: emocjonalne bańki filtrujące, pogarszająca się samoocena nastolatek, algorytmy, które wiedzą, że jesteś wzburzony i właśnie dlatego podają ci więcej tego samego. Bez regulacji prawnych i zewnętrznego nadzoru trudno oczekiwać, że cokolwiek się tu zmieni – firmy, które dysponowały własnymi badaniami pokazującymi szkodliwość ich produktów i kontynuowały optymalizację, nie zmienią kierunku dobrowolnie.
Ale jest też druga strona. Aplikacje pomagające nam odzyskać kontrolę nad własną uwagą – blokujące rozpraszacze, wprowadzające celowe opóźnienia, wizualizujące czas spędzony przed ekranem – pokazują, że technologia może też „budzić” nas ze scrolla zamiast w nim utrzymywać. Chatboty terapeutyczne budowane we współpracy ze specjalistami i z myślą przewodnią o dobrostanie, nie o wskaźniku retencji, realnie pomagają ludziom, którzy inaczej nie mieliby do czego sięgnąć. To nie są utopijne scenariusze – to rzeczy, które już istnieją i działają.
Różnica między jednym a drugim jest prosta do nazwania, choć trudna do wyegzekwowania: czy system jest projektowany z pytaniem „jak długo utrzymać użytkownika?” czy „czy to mu służy?”. I może, zanim następnym razem otworzymy aplikację bez konkretnego powodu, warto zadać sobie to pytanie.
Bibliografia
- Picard, R. W. (1997). Affective Computing. MIT Press.
- Covington, P., Adams, J., & Sargin, E. (2016). Deep Neural Networks for YouTube Recommendations. Google Research. https://research.google.com/pubs/archive/45530.pdf.
- Yamauchi, T., & Xiao, K. (2018). Reading Emotion From Mouse Cursor Motions: Affective Computing Approach. Cognitive Science, 42(3), 771-819. https://pubmed.ncbi.nlm.nih.gov/29131372/.
- PubMed Central (PMC). (2015). An Empirical Study on Emotion Recognition Using Keystroke Dynamics. PMC4465979. https://pmc.ncbi.nlm.nih.gov/articles/PMC4465979/.
- Wu, T. (2017). The Attention Merchants: The Epic Scramble to Get Inside Our Heads.
- Vosoughi, S., Roy, D., & Aral, S., The spread of true and false news online.Science359,1146-1151(2018). DOI:10.1126/science.aap9559
- Gray, Colin & Kou, Yubo & Battles, Bryan & Hoggatt, Joseph & Toombs, Austin. (2018). The Dark (Patterns) Side of UX Design. 10.1145/3173574.3174108.
- Haugen, F. (2021, 4 października). Testimony before the Senate Commerce Subcommittee on Consumer Protection, Product Safety and Data Security. United States Senate. https://www.commerce.senate.gov/wp-content/uploads/media/doc/Frances%20Haugen%20Written%20Testimony.pdf
- Ali, M., Ali, S., Abbas, Q., Abbas, Z., & Lee, S. W. (2025). Artificial intelligence for mental health: A narrative review of applications, challenges, and future directions in digital health. Digital health, 11, 20552076251395548. https://doi.org/10.1177/20552076251395548
- WEB1 – IEEE Spectrum (2021). How and Why Companies Will Engineer Your Emotions. https://spectrum.ieee.org/how-and-why-companies-will-engineer-your-emotions
- WEB2 – Netflix Technology Blog. (2021). Reinforcement Learning for Budget-Constrained Recommendations. https://netflixtechblog.com/reinforcement-learning-for-budget-constrained-recommendations-6cbc5263a32a.
- WEB3 – World Economic Forum (2024). How AI could help improve access to mental health treatment. https://www.weforum.org/stories/2024/10/how-ai-could-expand-and-improve-access-to-mental-health-treatment/
- WEB4 – Brignull, H. (2010). Deceptive Patterns https://www.deceptive.design/
- WEB5 – CNN (2026, 7 stycznia). Character.AI and Google agree to settle lawsuits over teen mental health harms and suicides. https://www.cnn.com/2026/01/07/business/character-ai-google-settle-teen-suicide-lawsuit