Czy można ufać sztucznej inteligencji?
Obecnie systemy wykorzystujące uczenie maszynowe są obecne niemal wszędzie – od wyszukiwarek internetowych i mediów społecznościowych, przez systemy rekomendacji i bankowość, aż po diagnostykę medyczną czy autonomiczne pojazdy. Wraz ze wzrostem możliwości modeli pojawiło się jednak pytanie, które dla wielu badaczy okazuje się równie istotne jak sama skuteczność algorytmów: czy można ufać decyzjom podejmowanym przez sztuczną inteligencję?
Problem ten nie jest wyłącznie kwestią techniczną. W przypadku zastosowań wysokiego ryzyka, takich jak medycyna, finanse czy wymiar sprawiedliwości, błędna decyzja systemu może prowadzić do bardzo poważnych konsekwencji. Użytkownicy oczekują więc nie tylko wysokiej dokładności, ale również możliwości zrozumienia, dlaczego algorytm podjął określoną decyzję.
W odpowiedzi na te potrzeby rozwinięto wiele strategii mających zwiększyć wiarygodność systemów AI. Szczególne znaczenie zyskały Explainable AI (XAI), podejście Human-in-the-Loop (HITL), ciągłe monitorowanie modeli, a także regulacje prawne i standardy etyczne. Wszystkie te rozwiązania mają wspólny cel – budowę zaufania do systemów, których działanie jest często znacznie bardziej złożone niż tradycyjnych programów komputerowych.
Problem czarnej skrzynki
W klasycznych algorytmach komputerowych proces podejmowania decyzji można prześledzić krok po kroku. Programista jest w stanie wskazać, dlaczego program zwrócił określony wynik. W przypadku współczesnych modeli głębokiego uczenia sytuacja wygląda zupełnie inaczej.
Nowoczesne sieci neuronowe mogą zawierać miliony, a nawet miliardy parametrów. Chociaż osiągają bardzo wysoką skuteczność, ich działanie przypomina tzw. black box, czyli „czarną skrzynkę”. Oznacza to, że znamy dane wejściowe oraz końcowy wynik, lecz dokładny proces prowadzący do podjęcia decyzji pozostaje trudny do zrozumienia.
Wyobraźmy sobie system analizujący zdjęcia rentgenowskie płuc. Algorytm stwierdza obecność zmian nowotworowych, jednak lekarz chciałby wiedzieć:
- które fragmenty obrazu miały największy wpływ na decyzję,
- jak duża jest pewność modelu,
- czy podobne przypadki występowały wcześniej,
Bez możliwości odpowiedzi na takie pytania trudno mówić o pełnym zaufaniu do systemu.
Explainable AI – próba zajrzenia do wnętrza modelu
Explainable AI (XAI) to zbiór metod umożliwiających człowiekowi zrozumienie działania systemów sztucznej inteligencji.
Podstawowym celem XAI nie jest ujawnienie wszystkich szczegółów matematycznych modelu, lecz dostarczenie wyjaśnień pozwalających użytkownikowi ocenić wiarygodność otrzymanych wyników.
W praktyce nie chodzi o to, aby człowiek był w stanie prześledzić każdą operację wykonywaną przez model. Znacznie ważniejsze jest uzyskanie odpowiedzi na pytania:
- dlaczego model podjął właśnie taką decyzję,
- które cechy danych były najważniejsze,
- jak bardzo model jest pewny swojej odpowiedzi,
- czy podobne dane prowadziły wcześniej do podobnych wyników,
- czy model nie wykorzystuje przypadkowych zależności lub błędów obecnych w danych,
Wyjaśnienia mogą mieć charakter globalny lub lokalny.
Wyjaśnienia globalne dotyczą całego modelu i próbują odpowiedzieć na pytanie, jak system działa ogólnie. Przykładowo można badać, które zmienne są najważniejsze dla wszystkich predykcji.
Wyjaśnienia lokalne odnoszą się do pojedynczej decyzji. W przypadku konkretnego pacjenta lub konkretnego zdjęcia RTG chcemy wiedzieć, dlaczego właśnie ten przypadek został sklasyfikowany w określony sposób.
Można wyróżnić dwa główne podejścia do osiągnięcia tego celu.
Modele interpretowalne z natury
Niektóre algorytmy są stosunkowo łatwe do zrozumienia już ze swojej konstrukcji. Należą do nich:
- regresja liniowa,
- regresja logistyczna,
- drzewa decyzyjne
Modele te określa się jako interpretowalne z natury (intrinsically interpretable), ponieważ sposób podejmowania decyzji jest bezpośrednio zapisany w strukturze modelu.
Przykładowo w regresji liniowej wynik jest kombinacją ważoną poszczególnych cech:
y = w1x1 + w2x2 + … + wnxn
Współczynniki (w_i) mają jasną interpretację. Dodatnia wartość oznacza, że wzrost danej cechy zwiększa przewidywany wynik, natomiast wartość ujemna działa odwrotnie.
Podobnie działa regresja logistyczna, szeroko stosowana między innymi w medycynie i finansach. Parametry modelu można interpretować jako wpływ poszczególnych cech na prawdopodobieństwo wystąpienia określonego zdarzenia.
Jeszcze bardziej intuicyjne są drzewa decyzyjne. Proces podejmowania decyzji przypomina serię pytań typu:
- czy wiek pacjenta przekracza 60 lat?
- czy poziom cholesterolu jest wyższy od określonego progu?
- czy występują dodatkowe czynniki ryzyka?
Każda ścieżka prowadząca od korzenia drzewa do liścia odpowiada konkretnej sekwencji decyzji, którą człowiek może łatwo prześledzić.
Sytuacja wygląda zupełnie inaczej w przypadku głębokich sieci neuronowych. Wiedza modelu jest rozproszona pomiędzy milionami parametrów, dlatego nawet pełna znajomość wszystkich wag nie oznacza rzeczywistego zrozumienia sposobu działania systemu.
Wyjaśnianie modeli typu black-box
W przypadku głębokich sieci neuronowych stosuje się dodatkowe techniki interpretacji, takie jak:
- LIME (Local Interpretable Model-Agnostic Explanations),
- SHAP (SHapley Additive Explanations),
- Grad-CAM (Gradient-weighted Class Activation Mapping),
Metody te nie zmieniają samego modelu, lecz próbują wyjaśnić jego zachowanie już po zakończeniu procesu uczenia. Są to więc techniki typu post hoc.
LIME
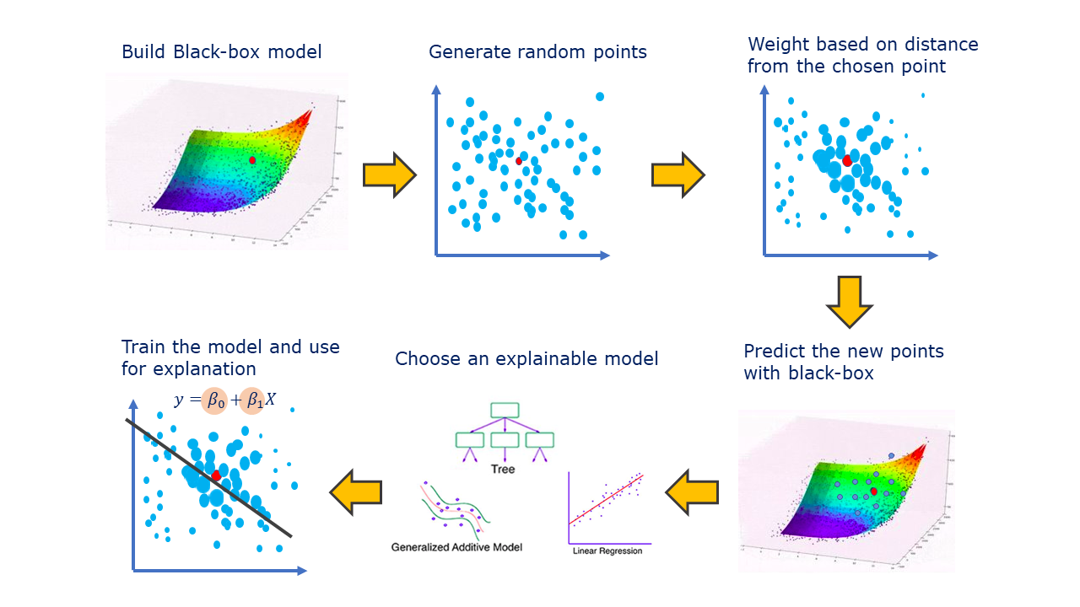
LIME jest metodą lokalną i niezależną od rodzaju modelu.
Jej podstawowa idea polega na tym, że nawet bardzo skomplikowany model może zachowywać się w niewielkim otoczeniu konkretnego przykładu w sposób zbliżony do prostego modelu liniowego.
Algorytm:
- generuje wiele lekko zmodyfikowanych wersji badanego przykładu,
- oblicza odpowiedzi oryginalnego modelu dla tych danych,
- dopasowuje prosty model interpretowalny do uzyskanych wyników.
W efekcie otrzymujemy informację, które cechy były najważniejsze dla konkretnej predykcji.
SHAP
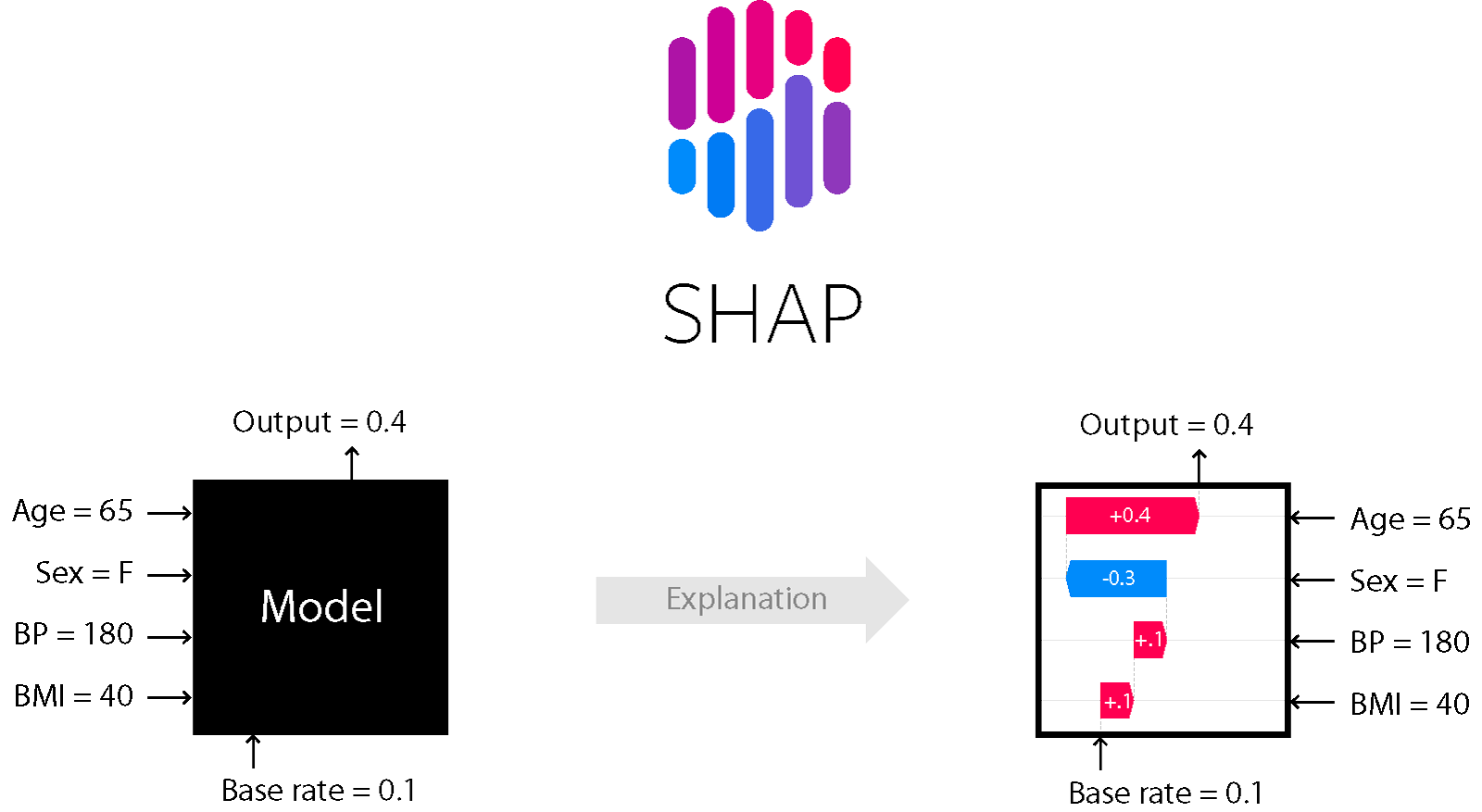
SHAP opiera się na teorii gier i koncepcji wartości Shapleya.
Poszczególne cechy traktowane są jak gracze współpracujący przy osiągnięciu końcowego wyniku. Dla każdej cechy oblicza się jej średni wkład w predykcję.
Dzięki temu można określić:
- które cechy zwiększały prawdopodobieństwo danej klasy,
- które działały przeciwnie,
- jak duży był wpływ każdej zmiennej.

Grad-CAM
Grad-CAM jest metodą przeznaczoną głównie dla konwolucyjnych sieci neuronowych analizujących obrazy.
Wykorzystuje gradienty obliczane podczas propagacji wstecznej, aby określić, które obszary obrazu miały największy wpływ na końcową klasyfikację.
Wynikiem działania algorytmu jest mapa cieplna (heatmap), nakładana na oryginalny obraz.
Jeżeli model wykrywa nowotwór na zdjęciu RTG, Grad-CAM pozwala zobaczyć, czy sieć rzeczywiście koncentrowała się na zmianie chorobowej, czy może przypadkowo wykorzystała nieistotne elementy obrazu.

Metody te pozwalają określić, które cechy danych miały największy wpływ na końcową predykcję, choć nie rozwiązują całkowicie problemu „czarnej skrzynki”. Dostarczają raczej przybliżonych wyjaśnień zachowania modelu niż pełnego opisu wszystkich procesów zachodzących wewnątrz sieci neuronowej.
Explainable AI w praktyce
Diagnostyka obrazowa
Jednym z najważniejszych zastosowań Explainable AI jest medycyna. Technika Grad-CAM umożliwia generowanie map aktywacji wskazujących obszary obrazu, które miały największy wpływ na decyzję modelu. Dzięki temu lekarz nie otrzymuje jedynie odpowiedzi „wykryto zmianę chorobową”, ale może sprawdzić, na czym dokładnie opierała się klasyfikacja.
Wyjaśnialność okazała się szczególnie cenna podczas analiz zdjęć RTG płuc i mammografii. W kilku przypadkach mapy aktywacji ujawniły, że modele częściowo opierały się na nieistotnych elementach obrazu, takich jak oznaczenia szpitali czy artefakty techniczne. Podobny problem zaobserwowano przy klasyfikacji zmian skórnych, gdzie sieć neuronowa wykorzystywała obecność linijki chirurgicznej jako pośrednią wskazówkę sugerującą nowotwór.
Przykłady te pokazują, że Explainable AI nie służy wyłącznie zwiększaniu komfortu użytkowników. Pozwala również wykrywać błędy i niepożądane zależności, które mogłyby pozostać niewidoczne przy analizie samej skuteczności modelu.
Badania wskazują także, że lekarze częściej akceptują rekomendacje systemów AI, gdy mogą zobaczyć mapy aktywacji oraz poziom pewności predykcji. W praktyce AI pełni więc rolę „drugiej pary oczu”, a nie całkowitego zastępstwa specjalisty.
Systemy finansowe
Banki coraz częściej wykorzystują modele uczenia maszynowego do oceny ryzyka kredytowego. W wielu krajach decyzje finansowe muszą być jednak uzasadnione.
W praktyce stosuje się więc metody SHAP, pozwalające określić wpływ poszczególnych cech na końcową decyzję. Klient może otrzymać informację, że na odmowę kredytu największy wpływ miały:
- wysoki poziom zadłużenia,
- nieregularna historia spłat,
- niewystarczające dochody.
Wyjaśnialność ma tutaj znaczenie nie tylko z punktu widzenia klienta, ale również regulatorów i samych analityków ryzyka.
Metody SHAP są wykorzystywane również do monitorowania modeli i wykrywania sytuacji, w których algorytm zaczyna nadmiernie polegać na określonych zmiennych. Pozwala to ograniczać ryzyko błędnych decyzji i ułatwia przeprowadzanie audytów.
Co istotne, analitycy finansowi często deklarują większe zaufanie do modeli, których decyzje można uzasadnić. W praktyce oznacza to, że wyjaśnialność zwiększa szanse na rzeczywiste wykorzystanie systemu przez ludzi.
Human-in-the-Loop – człowiek pozostaje częścią procesu
Jedną z najważniejszych strategii zwiększania wiarygodności systemów AI jest Human-in-the-Loop (HITL).
Podejście to zakłada, że sztuczna inteligencja nie działa całkowicie autonomicznie, lecz współpracuje z człowiekiem podczas rzeczywistego użytkowania systemu. AI może dostarczać rekomendacji, wskazywać potencjalne problemy lub wykonywać część zadań, jednak człowiek zachowuje możliwość nadzoru i ingerencji.
W praktyce użytkownik może:
- zatwierdzać lub odrzucać rekomendacje modelu,
- poprawiać błędy,
- monitorować działanie systemu,
- przejmować kontrolę w sytuacjach niejednoznacznych,
- decydować o ostatecznym wyniku działania systemu.
Dobrym przykładem Human-in-the-Loop są systemy moderacji treści w mediach społecznościowych. Algorytmy automatycznie wykrywają potencjalnie szkodliwe materiały, takie jak spam, mowa nienawiści czy treści naruszające regulamin. W przypadkach jednoznacznych decyzja może zostać podjęta automatycznie, jednak bardziej kontrowersyjne lub niejednoznaczne zgłoszenia trafiają do ludzkich moderatorów, którzy podejmują ostateczną decyzję.
Podobne rozwiązanie stosuje się w tłumaczeniach maszynowych. System AI generuje wstępne tłumaczenie dokumentu, natomiast profesjonalny tłumacz dokonuje korekty, poprawia błędy i dostosowuje tekst do kontekstu kulturowego oraz stylistycznego. Dzięki temu możliwe jest połączenie szybkości działania algorytmu z wiedzą i doświadczeniem człowieka.
Innym przykładem są systemy wspomagające obsługę klienta. Chatbot może odpowiadać na najczęściej zadawane pytania, ale w przypadku bardziej złożonych problemów rozmowa zostaje przekazana konsultantowi. Człowiek przejmuje wtedy kontrolę nad dalszą komunikacją i podejmuje decyzje wymagające większego zrozumienia sytuacji.
Human-in-the-Loop jest również szeroko wykorzystywany w oznaczaniu danych treningowych. Algorytmy mogą wstępnie klasyfikować obrazy lub dokumenty, natomiast eksperci weryfikują poprawność etykiet i korygują błędy. Takie podejście pozwala znacząco przyspieszyć proces przygotowywania danych, jednocześnie zachowując wysoką jakość zbiorów treningowych.
Przykłady te pokazują, że AI coraz częściej pełni rolę inteligentnego asystenta, a nie całkowicie autonomicznego zastępcy człowieka. Pozwala to wykorzystać szybkość i zdolność analizy dużych ilości danych przez algorytmy, jednocześnie zachowując ludzką intuicję, doświadczenie i odpowiedzialność.
Czy ludzie rzeczywiście bardziej ufają wyjaśnialnym systemom?
Badania przeprowadzone przez Ribeiro i współpracowników podczas opracowywania metody LIME wykazały, że odpowiednio przedstawione wyjaśnienia mogą pomagać użytkownikom lepiej oceniać działanie modeli. Osoby mające dostęp do dodatkowych informacji o przyczynach predykcji były skuteczniejsze w wykrywaniu błędów i łatwiej rozpoznawały sytuacje, w których modelowi nie należy ufać. Oznacza to, że wyjaśnienia mogą wspierać bardziej świadome korzystanie z systemów AI, a nie jedynie zwiększać zaufanie do ich wyników.
Podobne obserwacje poczyniono w medycynie. Lekarze częściej akceptują rekomendacje systemów AI, jeśli mają dostęp do dodatkowych informacji, takich jak mapy aktywacji, poziom pewności predykcji czy najważniejsze cechy wpływające na decyzję. Jednocześnie najwyższy poziom akceptacji obserwuje się zwykle wtedy, gdy system pełni rolę wspomagającą, a ostateczna decyzja pozostaje w rękach człowieka.
W finansach możliwość uzasadnienia decyzji ma znaczenie nie tylko psychologiczne, ale również praktyczne. Analitycy ryzyka i regulatorzy znacznie chętniej akceptują modele, których działanie można przynajmniej częściowo wyjaśnić. W wielu zastosowaniach brak możliwości przedstawienia uzasadnienia może wręcz uniemożliwić wdrożenie systemu.
Jednocześnie badania pokazują, że wpływ wyjaśnień na zachowanie użytkowników nie zawsze jest korzystny. Zjawiska takie jak automation bias oraz overtrust wskazują, że ludzie mogą nadmiernie polegać na rekomendacjach systemu. Przekonujące wizualizacje lub pozornie logiczne uzasadnienia mogą sprawiać, że użytkownicy przypisują modelowi większą wiarygodność, niż wynika to z jego rzeczywistych możliwości. Oznacza to, że samo dostarczenie wyjaśnień nie gwarantuje bardziej racjonalnych decyzji.
Z tego powodu celem Explainable AI nie powinno być maksymalne zwiększanie zaufania do systemów, lecz budowanie tzw. skalibrowanego zaufania (calibrated trust). Oznacza ono sytuację, w której użytkownik ufa modelowi wtedy, gdy jest on rzeczywiście wiarygodny, a zachowuje ostrożność w przypadkach niejednoznacznych lub obarczonych większą niepewnością. W tym ujęciu zadaniem Explainable AI nie jest sprawienie, aby ludzie ufali sztucznej inteligencji bardziej, lecz aby ufali jej w sposób bardziej świadomy i adekwatny do rzeczywistych możliwości systemu.
Karty modeli jako uzupełnienie wyjaśnialności i świadomego zaufania
Wnioski płynące z badań nad Explainable AI wskazują, że dostęp do dodatkowych informacji o działaniu modeli może istotnie wpływać na sposób, w jaki użytkownicy oceniają ich decyzje. Wyjaśnienia nie tylko zwiększają zrozumienie pojedynczych predykcji, ale przede wszystkim pomagają w rozpoznawaniu sytuacji, w których model może być niepewny lub błędny. W efekcie użytkownicy niekoniecznie ufają systemom bardziej, lecz uczą się oceniać ich wiarygodność w sposób bardziej świadomy.
W tym kontekście ciekawym uzupełnieniem podejścia opartego na wyjaśnialności są tzw. karty modeli (Model Cards). W przeciwieństwie do metod takich jak LIME, SHAP czy Grad-CAM, nie odnoszą się one do pojedynczych predykcji, lecz do modelu jako całości. Ich celem jest dostarczenie uporządkowanej informacji o tym, do czego model został zaprojektowany, na jakich danych był trenowany oraz jakie są jego znane ograniczenia.
Można powiedzieć, że karty modeli rozszerzają ideę wyjaśnialności z poziomu „dlaczego ta konkretna decyzja została podjęta” na poziom „kiedy temu systemowi w ogóle warto ufać”. Zawierają one informacje o warunkach, w których model działa poprawnie, a także o sytuacjach, w których jego zastosowanie może prowadzić do błędnych wniosków. Dzięki temu użytkownik nie musi polegać wyłącznie na obserwacji pojedynczych predykcji, ale otrzymuje szerszy kontekst działania systemu.
Takie podejście wpisuje się w ideę skalibrowanego zaufania. Zamiast zakładać, że system AI jest zawsze wiarygodny lub zawsze niepewny, użytkownik otrzymuje narzędzia pozwalające ocenić jego przydatność w konkretnym kontekście. W ten sposób karty modeli pełnią rolę „metawyjaśnienia” – nie tłumaczą decyzji, lecz pomagają zrozumieć granice ich interpretacji i zastosowania.
Cena wyjaśnialności
Budowanie bardziej przejrzystych systemów nie jest darmowe. Wyjaśnialność ma swoją cenę – zarówno w sensie obliczeniowym, finansowym, jak i organizacyjnym.
Jednym z najpopularniejszych narzędzi Explainable AI jest SHAP. W przypadku dużych sieci neuronowych wygenerowanie pełnego wyjaśnienia może być nawet kilkadziesiąt lub kilkaset razy bardziej czasochłonne niż samo wykonanie predykcji.
Przykładowo:
- wykonanie predykcji może trwać około 20 ms,
- obliczenie wartości SHAP może wymagać od 1 do 5 sekund.
W systemach czasu rzeczywistego takie opóźnienia mogą być nieakceptowalne. Oznacza to, że wyjaśnienia często nie są generowane dla wszystkich przypadków, lecz jedynie dla wybranych decyzji lub podczas późniejszych audytów.
Koszt wyjaśnialności nie ogranicza się jednak do dodatkowych obliczeń. Konieczne jest również:
- przechowywanie historii predykcji,
- monitorowanie modeli,
- przeprowadzanie audytów,
- ponowne trenowanie modeli,
- angażowanie ekspertów dziedzinowych,
- utrzymywanie infrastruktury umożliwiającej analizę działania systemu.
W przypadku dużych modeli językowych sam proces RLHF wymaga zatrudnienia licznych zespołów oceniających odpowiedzi oraz przeprowadzenia dodatkowych etapów treningu, których koszt może być liczony w milionach dolarów.
Istnieje również mniej oczywisty koszt związany z samym wyborem architektury modelu. Przez wiele lat zakładano istnienie prostego kompromisu:
większa dokładność oznacza mniejszą interpretowalność.
W praktyce zależność ta nie jest tak jednoznaczna, jednak w wielu zastosowaniach wybór bardziej przejrzystego modelu może oznaczać rezygnację z części skuteczności. Z drugiej strony zastosowanie najbardziej zaawansowanych sieci neuronowych może wymagać późniejszego korzystania z kosztownych metod wyjaśniania post hoc.
Pojawia się więc swoisty „trójkąt kompromisu”, obejmujący:
- skuteczność,
- interpretowalność,
- koszt obliczeniowy.
Poprawa jednego z tych elementów często odbywa się kosztem pozostałych.
W zastosowaniach przemysłowych dochodzą jeszcze wymagania związane z bezpieczeństwem, zgodnością z regulacjami oraz odpowiedzialnością prawną. W rezultacie całkowity koszt budowy godnego zaufania systemu AI jest zwykle znacznie większy niż koszt samego wytrenowania modelu.
Coraz więcej badaczy podkreśla więc, że pytanie nie brzmi już:
„Czy warto poświęcić trochę dokładności dla większej interpretowalności?”
Znacznie ważniejsze staje się pytanie:
„Jaki poziom wyjaśnialności jest wystarczający w danym zastosowaniu i czy korzyści uzasadniają związane z nim koszty?”
Podsumowanie
Rosnąca rola sztucznej inteligencji sprawia, że kwestia zaufania staje się równie ważna jak sama skuteczność modeli.
Explainable AI, Human-in-the-Loop, monitorowanie modeli oraz rozwój standardów etycznych stanowią próbę pogodzenia trzech często konkurujących ze sobą wartości: przejrzystości, rzetelności oraz wydajności obliczeniowej.
Nie istnieje jednak rozwiązanie idealne. Większa interpretowalność oznacza zwykle wyższe koszty i większe wymagania obliczeniowe, a udział człowieka ogranicza skalowalność systemów.
Przyszłość sztucznej inteligencji prawdopodobnie nie będzie polegała na całkowitym zastąpieniu człowieka, lecz na tworzeniu systemów współpracy człowieka i maszyny. Ostatecznie bowiem zaufanie do AI nie wynika wyłącznie z jej skuteczności, ale również z możliwości zrozumienia, kontrolowania i rozliczania podejmowanych przez nią decyzji.
Co istotne, celem współczesnych badań nie jest maksymalizacja zaufania do systemów AI, lecz budowanie tzw. skalibrowanego zaufania (calibrated trust). Oznacza ono, że użytkownicy powinni ufać modelom wtedy, gdy ich działanie jest wiarygodne i dobrze udokumentowane, a jednocześnie zachowywać ostrożność w sytuacjach niepewnych lub obarczonych większym ryzykiem. W tym sensie sukces sztucznej inteligencji będzie zależał nie tylko od tego, jak trafne będą jej predykcje, ale również od tego, czy ludzie będą potrafili korzystać z niej w sposób świadomy i krytyczny.
Literatura
- Ribeiro M. T., Singh S., Guestrin C., „Why Should I Trust You?”: Explaining the Predictions of Any Classifier, KDD, 2016.
- Lundberg S. M., Lee S.-I., A Unified Approach to Interpreting Model Predictions, NeurIPS, 2017.
- Petkovic D., It is not Accuracy vs Explainability – We Need Both for Trustworthy AI Systems, 2022.
- Evite P. M., Svetlova E., Bucur D., Trade-offs in Financial AI: Explainability in a Trilemma with Accuracy and Compliance, 2026.
- Mitchell M., Wu S., Zaldivar A., Barnes P., Vasserman L., Hutchinson B., Spitzer E., Raji I. D., Gebru T., Model Cards for Model Reporting, FAT, 2019.*
- Lee J. D., See K. A., Trust in Automation: Designing for Appropriate Reliance, Human Factors, 2004.