Algorytmy sztucznej inteligencji coraz częściej wspomagają lekarzy w stawianiu diagnoz, przewidywaniu ryzyka chorób i rekomendowaniu terapii. Problem w tym, że najskuteczniejsze z tych modeli działają jak „czarne skrzynki” – podają wynik, ale nie potrafią powiedzieć, dlaczego go wybrały. Medycyna to nie algorytm rekomendacyjny Netflixa – tam błędna rekomendacja filmu oznacza nudny wieczór. W medycynie błędna decyzja AI lub ślepe zaufanie do niej to kwestia życia i śmierci, brak przejrzystości staje się barierą nie tylko technologiczną, lecz przede wszystkim etyczną i społeczną. Dlatego narodził się nurt XAI (Explainable AI – Wyjaśnialna Sztuczna Inteligencja).
Niniejszy tekst poddaje analizie, czym jest wyjaśnialna sztuczna inteligencja (XAI), dlaczego jej potrzebują zarówno lekarze, jak i pacjenci, jakie ramy prawne wymuszają transparentność, a na koniec przedstawione jest praktyczne rozwiązanie – dwupoziomowy interfejs wyjaśnień oparty na bibliotekach SHAP i LIME, który dostosowuje komunikat do odbiorcy: eksperta klinicznego lub pacjenta.
Współczesna medycyna wkracza w erę, w której algorytmy uczenia maszynowego potrafią rozpoznawać nowotwory na zdjęciach histopatologicznych, przewidywać ryzyko sepsy na oddziałach intensywnej terapii, a nawet rekomendować schematy chemioterapii. Eric Topol w swojej przełomowej książce Deep Medicine zarysował wizję, w której AI uwalnia lekarzy od rutynowych zadań i pozwala im wrócić do tego, co w medycynie najważniejsze – relacji z pacjentem. Jednocześnie Topol podkreślał, że aby ta wizja się urzeczywistniła, konieczne jest zaufanie – zarówno ze strony klinicystów, jak i pacjentów (Topol, 2019).
Tymczasem najskuteczniejsze modele – głębokie sieci neuronowe, modele gradientowe typu XGBoost, wielowarstwowe architektury transformerowe – są z natury nieprzejrzyste. Ich wewnętrzna logika, oparta na milionach parametrów, wymyka się ludzkiej intuicji. Powstaje fundamentalne pytanie: czy można ufać systemowi, którego rozumowania nie da się prześledzić?
Czarna skrzynka w gabinecie lekarskim – skala problemu
Pojęcie „czarnej skrzynki” (ang. black box) w kontekście AI opisuje model, który produkuje trafne prognozy, ale nie udostępnia czytelnej ścieżki prowadzącej od danych wejściowych do wyniku. W wielu dziedzinach – od rekomendacji filmów po targetowanie reklam – taka nieprzejrzystość jest akceptowalna. W medycynie nie jest.
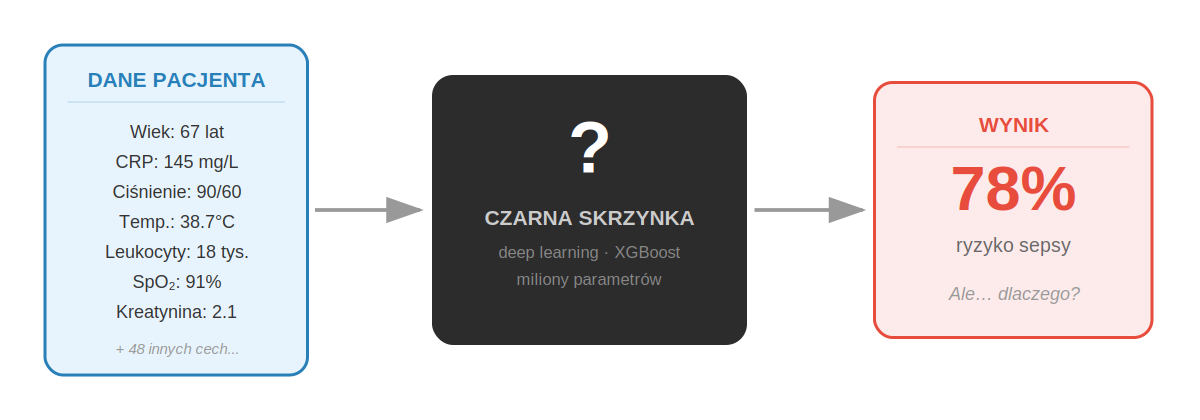
Ryc. 1. Problem „czarnej skrzynki” – model przyjmuje dane kliniczne pacjenta i generuje prognozę, ale nie udostępnia ścieżki rozumowania prowadzącej do wyniku.
Rosenbacke i współautorzy (2024) w systematycznym przeglądzie opublikowanym w JMIR AI wykazali, że brak wyjaśnień może zarówno obniżać, jak i – paradoksalnie – podwyższać zaufanie klinicystów do systemów AI. Ten drugi scenariusz wynika ze zjawiska zwanego błędem automatyzacji (ang. automation bias): gdy lekarz widzi konkretną liczbę wygenerowaną przez algorytm (np. „ryzyko rehospitalizacji: 78%”), sam fakt jej komputerowego pochodzenia nadaje jej aurę obiektywności i precyzji. Zapracowany klinicysta, pod presją czasu i z dziesiątkami pacjentów na dyżurze, może pomyśleć: „system to policzył, pewnie wie lepiej” – i zaakceptować wynik bez krytycznej weryfikacji. Paradoks polega na tym, że gdyby system podał wyjaśnienie (np. „ryzyko jest wysokie głównie z powodu podwyższonego CRP i niskiego ciśnienia”), lekarz mógłby to skonfrontować ze swoją wiedzą kliniczną i powiedzieć: „chwila, ale ten pacjent ma chronicznie niskie ciśnienie – to nie jest tu czynnik ryzyka”. Wyjaśnienie daje punkt zaczepienia do krytyki; jego brak sprawia, że nie ma czego kwestionować – zostaje tylko liczba i autorytet maszyny. Z kolei pierwszy scenariusz jest prostszy: lekarz, nie rozumiejąc podstaw rekomendacji, po prostu ją odrzuca i wraca do własnego osądu, ignorując potencjalnie wartościową podpowiedź algorytmu. Oba scenariusze – zarówno ślepe zaufanie, jak i całkowite odrzucenie – są nieskuteczne w leczeniu pacjenta (Rosenbacke i in., 2024).
Z perspektywy pacjenta problem przybiera inny wymiar. Wyobraźmy sobie, że system AI rekomenduje określoną terapię onkologiczną. Pacjent pyta lekarza: „Dlaczego akurat ten lek?”. Jeśli lekarz odpowiada: „Bo tak wskazał algorytm” – to nie jest wyjaśnienie. To przeniesienie odpowiedzialności na maszynę, która nie ponosi konsekwencji swoich błędów. Pacjent, w odróżnieniu od klinicysty, nie ma narzędzi ani wiedzy, by samodzielnie ocenić trafność rekomendacji – jest więc całkowicie zależny od jakości komunikatu, jaki otrzyma. Jeśli ten komunikat ogranicza się do „tak powiedział komputer”, pacjent traci zaufanie – nie tylko do systemu AI, ale i do samego lekarza, który nie potrafi uzasadnić własnej decyzji terapeutycznej.
Interpretowalność kontra wyjaśnialność – precyzja pojęć
W literaturze XAI funkcjonują dwa pokrewne, ale nie tożsame terminy. Interpretowalność (ang. interpretability) oznacza, że model jest z natury zrozumiały – jego struktura pozwala człowiekowi prześledzić, jak od danych wejściowych dochodzi do wyniku. Przykładem są drzewa decyzyjne, regresja logistyczna czy systemy regułowe. Wyjaśnialność (ang. explainability) dotyczy natomiast sytuacji, gdy złożony model (np. sieć neuronowa) jest uzupełniany o dodatkową warstwę – mechanizm wyjaśniający post hoc, dlaczego podjął daną decyzję.
Wyjaśnienia muszą być niedokładne. Nie mogą mieć doskonałej wierności wobec oryginalnego modelu. Gdyby wyjaśnienie było w pełni wierne temu, co model oblicza, zastąpiłoby sam model – i nie byłoby potrzebne.
– Cynthia Rudin, parafraza argumentu z Nature Machine Intelligence (2019)
Cynthia Rudin (2019) w głośnym artykule opublikowanym w Nature Machine Intelligence argumentowała, że w dziedzinach o wysokiej stawce – medycynie, wymiarze sprawiedliwości – powinniśmy w ogóle rezygnować z nieprzejrzystych modeli i stosować modele interpretowalne z natury. Jej zdaniem wyjaśnienia post hoc są z definicji niedoskonałe (Rudin, 2019).
Stanowisko Rudin jest intelektualnie przekonujące, ale w praktyce budzi kontrowersje. Modele interpretowalne z natury (np. regresja liniowa) często osiągają niższą dokładność od modeli złożonych, zwłaszcza przy dużych, wielowymiarowych zbiorach danych klinicznych. Metaanalizy wskazują, że modele interpretowalne wiążą się z utratą 5-7% AUC w porównaniu z modelami czarnoskrzynkowymi w zadaniach diagnostycznych. W onkologii czy kardiologii taka różnica może oznaczać nierozpoznane przypadki – a więc realne zagrożenie dla życia.
Dlatego bardziej pragmatyczne podejście zakłada kompromis: stosujemy najskuteczniejszy model, ale obudowujemy go solidną warstwą wyjaśnień. Tu wkraczają metody takie jak SHAP i LIME.
SHAP i LIME – dwa filary wyjaśnialnej AI
SHAP (SHapley Additive exPlanations) to metoda oparta na teorii gier, a konkretnie na wartościach Shapleya. Traktuje każdą cechę wejściową (np. wiek pacjenta, poziom glukozy, wyniki badań obrazowych) jako „gracza” w koalicyjnej grze, a wynik modelu jako „wypłatę”. SHAP oblicza marginalny wkład każdej cechy do konkretnej predykcji, dając zarówno wyjaśnienia lokalne (dla pojedynczego pacjenta), jak i globalne (dla całego modelu). Jego zaletą jest solidna podbudowa matematyczna i spójność – te same cechy w analogicznych sytuacjach otrzymują porównywalne wartości atrybukcji (Salih i in., 2025).
LIME (Local Interpretable Model-Agnostic Explanations) działa inaczej: buduje uproszczony, interpretowalny model (np. regresję liniową) w lokalnym otoczeniu konkretnego przypadku. Zaburza dane wejściowe, obserwuje, jak zmienia się predykcja, i na tej podstawie przybliża zachowanie „czarnej skrzynki” w pobliżu danego punktu. LIME jest szybszy obliczeniowo i daje intuicyjne wyjaśnienia, ale jego wadą jest niższa wierność (ang. fidelity) – lokalne przybliżenie nie zawsze dokładnie odwzorowuje logikę oryginalnego modelu (Salih i in., 2025).
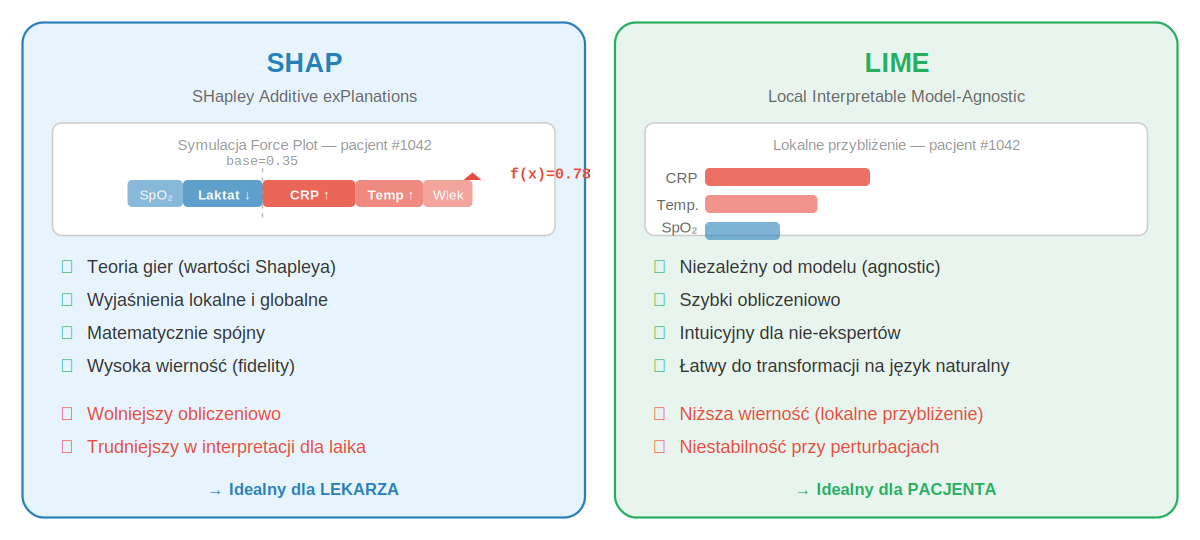
Ryc. 2. Porównanie metod SHAP i LIME – obie wyjaśniają tę samą predykcję (ryzyko sepsy = 78%), ale w odmienny sposób. SHAP jest idealny dla lekarza, LIME – dla pacjenta.
Ahmed i współautorzy (2024) w porównawczej analizie SHAP i LIME na danych dotyczących prognozowania cukrzycy wykazali, że oba narzędzia istotnie poprawiają zrozumiałość wyników przez lekarzy, ale różnią się w poziomie szczegółowości. SHAP wskazuje precyzyjne wartości wkładu poszczególnych cech, podczas gdy LIME oferuje bardziej uproszczony obraz – co może być zaletą w komunikacji z pacjentem (Ahmed i in., 2024).
Porównanie metod wyjaśnialnej AI w zastosowaniach medycznych
| Parametr | SHAP | LIME | Modele interpretowalne z natury |
| Podstawa teoretyczna | Teoria gier (wartości Shapleya) | Lokalne przybliżenie liniowe | Struktura modelu (np. drzewo decyzyjne) |
| Typ wyjaśnień | Lokalne + globalne (Salih i in., 2025) | Tylko lokalne (Salih i in., 2025) | Globalne (cała struktura widoczna) |
| Wierność (fidelity) | Wysoka (Ahmed i in., 2024) | Średnia – zależy od otoczenia lokalnego | Doskonała (model = wyjaśnienie) |
| Koszt obliczeniowy | Wysoki (zwłaszcza KernelSHAP) | Niski – idealne dla czasu rzeczywistego | Minimalny |
| Dokładność modelu bazowego | Dowolna (post hoc) | Dowolna (post hoc) | Niższa o 5-7% AUC (Rudin, 2019) |
Tabela 1. Porównanie trzech podejść do wyjaśnialności AI w medycynie. Opracowanie własne na podst. Salih i in. (2025), Ahmed i in. (2024), Rudin (2019).
Czego potrzebują klinicyści – perspektywa użytkownika
Tonekaboni i współautorzy (2019) przeprowadzili pionierskie badanie jakościowe wśród lekarzy oddziałów intensywnej terapii i izb przyjęć, pytając, jakich wyjaśnień oczekują od systemów AI. Wyniki były jednoznaczne: sama dokładność modelu nie wystarczy. Klinicyści chcą wiedzieć, jakie cechy napędzają konkretną predykcję, jaki jest poziom niepewności modelu, oraz jak model zachowywał się na podobnych przypadkach w przeszłości. Co istotne, lekarze stwierdzili, że potrzebują różnych typów wyjaśnień w różnych kontekstach – inne informacje są potrzebne przy triażu na izbie przyjęć, a inne przy planowaniu długoterminowej terapii (Tonekaboni i in., 2019).
Te wyniki mają fundamentalne znaczenie projektowe: nie istnieje jedno uniwersalne wyjaśnienie. System XAI musi być adaptacyjny – dostosowywać formę, głębokość i język komunikatu do odbiorcy i sytuacji klinicznej.
Pacjent jako pominięty odbiorca wyjaśnień
O ile literatura na temat XAI w medycynie koncentruje się głównie na klinicystach, pacjent – najważniejszy interesariusz – bywa pomijany. Tymczasem autonomia pacjenta, wyrażona m.in. w doktrynie świadomej zgody, wymaga, by osoba poddawana diagnostyce lub terapii rozumiała podstawy podejmowanych decyzji.
Systemy XAI adresowane do pacjentów muszą unikać żargonu statystycznego. Zamiast „wartość SHAP cechy hemoglobina = -0.34″ pacjent potrzebuje informacji typu: „System uwzględnił, że Pana/Pani poziom hemoglobiny jest niższy niż u większości osób w podobnym wieku i stanie zdrowia, co zwiększyło oszacowane ryzyko powikłań”. Zdolność systemu do personalizacji wyjaśnień – dostosowania ich do demografii, historii medycznej i poziomu wiedzy odbiorcy – jest kluczowym czynnikiem budowania zaufania.
Ramy prawne – EU AI Act i wymóg transparentności
Unijna ustawa o sztucznej inteligencji (AI Act, Regulation 2024/1689), która weszła w życie 1 sierpnia 2024 roku, wprowadziła klasyfikację systemów AI opartą na poziomie ryzyka. Na szczycie piramidy znajdują się systemy całkowicie zakazane – takie jak social scoring (algorytmiczne ocenianie obywateli na wzór chińskiego Systemu Zaufania Społecznego) czy systemy manipulacji poznawczej (np. AI celowo wykorzystujące uzależnienia lub targetujące dzieci). Niżej, w kategorii systemów wysokiego ryzyka, znalazły się systemy medyczne – w tym oprogramowanie diagnostyczne, narzędzia wspomagające decyzje kliniczne i systemy monitorowania pacjentów. Kategoria ta oznacza, że AI medyczne jest dozwolone i potrzebne, ale podlega najsurowszym wymogom: jakości danych, zarządzania ryzykiem, nadzoru ludzkiego i – co kluczowe – przejrzystości.
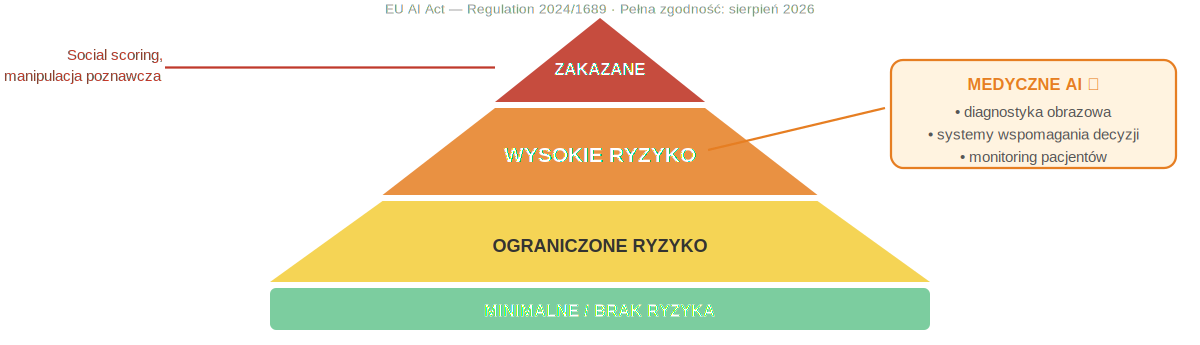
Ryc. 3. Piramida ryzyka w EU AI Act – systemy medyczne AI klasyfikowane jako systemy wysokiego ryzyka, podlegające najsurowszym wymogom transparentności. Na podst. Regulation (EU) 2024/1689.
Dostawcy systemów AI klasy medycznej są zobowiązani do dostarczania użytkownikom (szpitalom, lekarzom) wyczerpujących informacji o sposobie działania systemu, jego ograniczeniach i potencjalnych ryzykach. Pełna zgodność z wymogami dla systemów wysokiego ryzyka jest wymagana od sierpnia 2026 roku, co oznacza, że branża medtech ma niewiele czasu na wdrożenie mechanizmów wyjaśnialności.
To właśnie regulacja prawna może okazać się najsilniejszym katalizatorem adopcji XAI w medycynie – nie dlatego, że firmy chcą być transparentne, ale dlatego, że muszą.
Komponent praktyczny – dwupoziomowy interfejs wyjaśnień (DAEI)
Poniżej przedstawiona jest architektura praktycznego rozwiązania: dwupoziomowego interfejsu wyjaśnień (ang. Dual-Audience Explanation Interface, DAEI), który może towarzyszyć dowolnemu medycznemu systemowi predykcyjnemu. Kluczowym założeniem jest zasada human-in-the-loop – pacjent nigdy nie otrzymuje surowego wyniku algorytmu. Każda rekomendacja systemu AI trafia najpierw do lekarza, który ją weryfikuje, kontekstualizuje i dopiero wtedy decyduje, co i w jakiej formie przekazać pacjentowi.
Założenia projektowe
- Dwa tryby widoku: tryb ekspercki (dla lekarza) i tryb pacjenta.
- Wspólny silnik wyjaśnień: oparty na bibliotekach SHAP (wyjaśnienia globalne i lokalne) oraz LIME (szybkie lokalne przybliżenia).
- Adaptacja języka: automatyczna transformacja technicznego opisu na zrozumiały komunikat w języku naturalnym (NLG).
- Wskaźnik niepewności: każda predykcja opatrzona jest przedziałem ufności, prezentowanym graficznie.
- Human-in-the-loop: wynik generowany przez AI nie trafia bezpośrednio do pacjenta – lekarz pełni rolę bramki weryfikacyjnej, która zatwierdza, modyfikuje lub odrzuca rekomendację przed jej przekazaniem.
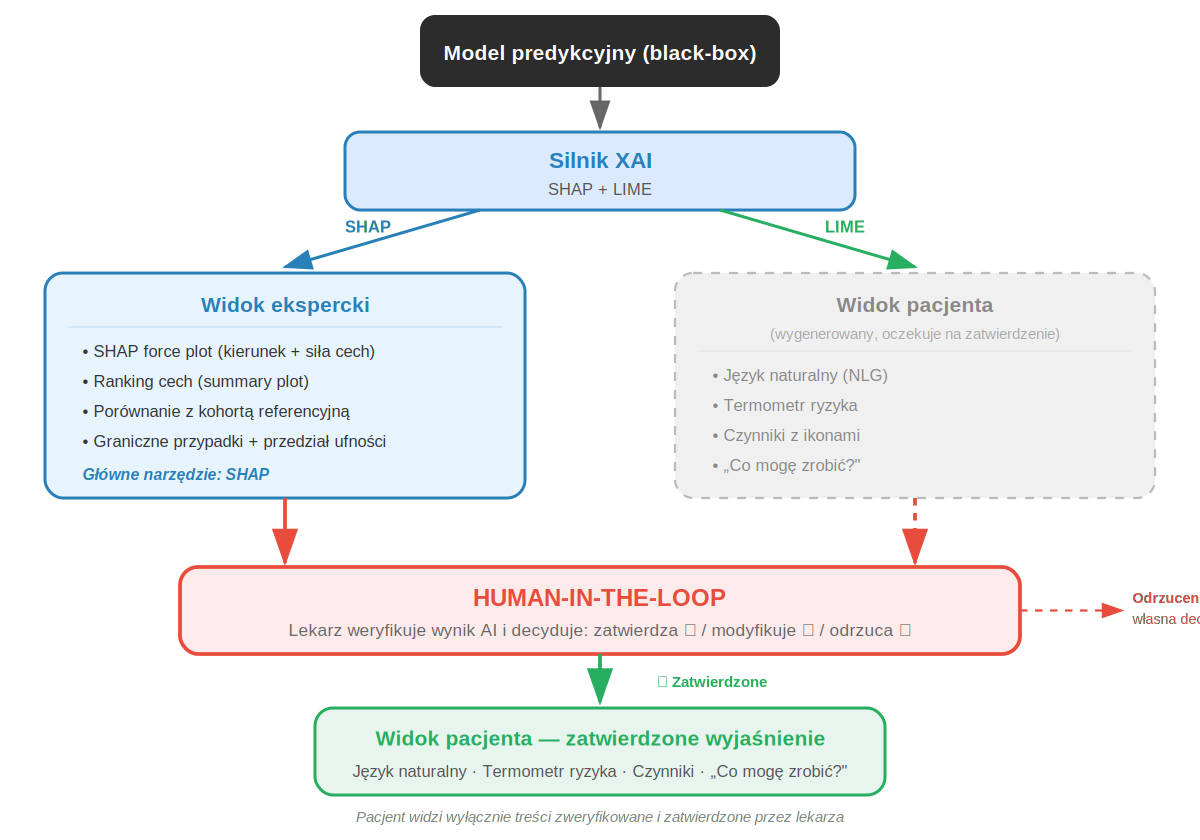
Ryc. 4. Architektura dwupoziomowego interfejsu wyjaśnień (DAEI) – wspólny silnik XAI generuje dwa odmienne widoki: techniczny dla klinicysty (oparty na SHAP) i uproszczony dla pacjenta (oparty na LIME z transformacją na język naturalny).
Widok ekspercki (lekarz)
Lekarz widzi:
- Wykres SHAP force plot: wizualizację kierunku i siły wpływu poszczególnych cech na predykcję (np. „podwyższony CRP pchał prognozę w kierunku sepsy, podczas gdy prawidłowy poziom laktatów obniżał to ryzyko”).
- Ranking cech (SHAP summary plot): globalny obraz najważniejszych predyktorów w modelu.
- Porównanie z kohortą referencyjną: „Wśród 120 pacjentów o podobnym profilu klinicznym, 73% rozwinęło ten stan w ciągu 48h”.
- Ostrzeżenie o granicznych przypadkach: jeśli pacjent leży blisko granicy decyzyjnej modelu, system jawnie to sygnalizuje.
- Panel decyzyjny: lekarz zatwierdza, modyfikuje lub odrzuca rekomendację AI, zanim cokolwiek zostanie przekazane pacjentowi. Może też dodać własny komentarz kliniczny, który uzupełni automatyczne wyjaśnienie.
Widok pacjenta
Pacjent widzi:
- Podsumowanie w języku naturalnym: „Na podstawie Pani wyników badań, historii chorobowej i grupy wiekowej lekarz, wspierany przez system analityczny, ocenił ryzyko powikłań jako podwyższone. Główne czynniki to poziom cukru we krwi oraz ciśnienie tętnicze.”
- Wizualizację „termometru ryzyka”: prosta grafika pokazująca, gdzie na skali niskie-średnie-wysokie ryzyko znajduje się pacjent.
- Listę czynników z ikonami: zamiast wartości liczbowych – intuicyjne ikony (strzałka w górę = czynnik zwiększający ryzyko, strzałka w dół = czynnik ochronny).
- Sekcję „Co mogę zrobić?”: jeśli model identyfikuje modyfikowalne czynniki ryzyka (np. nadwagę, palenie), system sugeruje działania profilaktyczne.
- Adnotację o nadzorze lekarskim: widoczna informacja, że wynik został zweryfikowany przez lekarza prowadzącego – nie jest to surowa odpowiedź algorytmu.

Ryc. 5. Prototyp widoku pacjenta – prosty „termometr ryzyka” z intuicyjnymi ikonami czynników i sugestiami działań profilaktycznych.
Dlaczego human-in-the-loop jest niezbędny?
Nawet najlepszy algorytm nie zna kontekstu, którego nie ma w danych – np. tego, że pacjent właśnie stracił bliską osobę i jego podwyższone ciśnienie ma podłoże emocjonalne, a nie patologiczne. Lekarz wnosi wiedzę kliniczną, doświadczenie i empatię, których żaden model nie posiada. Bez tej warstwy weryfikacji istnieje ryzyko, że pacjent otrzyma komunikat, który jest technicznie poprawny, ale klinicznie mylący lub psychologicznie szkodliwy – np. zawyżony poziom ryzyka wywołujący niepotrzebny lęk. Zasada human-in-the-loop gwarantuje, że AI pozostaje narzędziem wspierającym decyzję lekarza, a nie podejmującym ją za niego.
Dlaczego dwa narzędzia, a nie jedno?
SHAP i LIME pełnią komplementarne role. SHAP zapewnia matematyczną precyzję i spójność – jest niezbędny dla klinicystów, którzy muszą ufać wyjaśnieniom na poziomie technicznym. LIME oferuje prostotę i szybkość – idealną do generowania komunikatów dla pacjentów, gdzie liczy się przystępność, a nie szczegółowość. Połączenie obu metod w jednym interfejsie pozwala obsłużyć oba audytoria bez kompromisów.
Ograniczenia i otwarte wyzwania
Proponowane rozwiązanie nie jest pozbawione ograniczeń. Po pierwsze, transformacja wyjaśnień technicznych na język naturalny wymaga ostrożności – uproszczenie może prowadzić do zniekształcenia, a lekarz pełniący rolę bramki weryfikacyjnej nie zawsze będzie miał czas na szczegółową edycję komunikatu dla pacjenta, zwłaszcza w warunkach dyżurowych. Po drugie, generowanie wyjaśnień SHAP dla dużych modeli bywa kosztowne obliczeniowo, co utrudnia zastosowanie w systemach czasu rzeczywistego (np. monitoring na OIOM-ie). Po trzecie, sama zasada human-in-the-loop, choć kluczowa, wprowadza wąskie gardło – jeśli każda rekomendacja AI wymaga zatwierdzenia przez lekarza, system traci na szybkości, co w stanach nagłych może być problematyczne. Po czwarte, badania pokazują, że nawet dobrze zaprojektowane wyjaśnienia mogą paradoksalnie zwiększyć nadmierne zaufanie do AI, jeśli są zbyt przekonujące – klinicyści mogą z czasem zatwierdzać rekomendacje rutynowo, bez rzeczywistej weryfikacji, co sprawi, że bramka human-in-the-loop stanie się formalnością zamiast realnym filtrem (Rosenbacke i in., 2024).
Konieczne są dalsze badania z użytkownikami – zarówno randomizowane eksperymenty kliniczne porównujące decyzje lekarzy z wyjaśnieniami XAI i bez nich, jak i badania jakościowe nad tym, jak pacjenci faktycznie interpretują komunikaty zatwierdzone przez lekarza w porównaniu z surowym wynikiem algorytmu.
Konkluzja
Wyjaśnialna sztuczna inteligencja w medycynie nie jest luksusem – to wymóg etyczny, prawny i praktyczny. Regulacje takie jak EU AI Act formalizują to, co świat medyczny intuicyjnie rozumie od lat: decyzja dotycząca zdrowia człowieka musi być uzasadniona i zrozumiała. Jednocześnie nie istnieje jedno uniwersalne wyjaśnienie – lekarz i pacjent potrzebują różnych form, różnych języków i różnych poziomów szczegółowości.
Proponowany dwupoziomowy interfejs wyjaśnień, łączący precyzję SHAP z przystępnością LIME i zabezpieczony bramką human-in-the-loop, stanowi krok w kierunku systemów AI, które nie tylko trafnie prognozują, ale również budują zaufanie. Bo w medycynie ostatecznym kryterium nie jest AUC modelu – lecz to, czy lekarz może świadomie zweryfikować rekomendację algorytmu, a pacjent otrzymać wyjaśnienie, które pozwoli mu podjąć wspólną z lekarzem, przemyślaną decyzję.
Literatura
- Ahmed, S., Andersson, K., Kaiser, M. S. (2024). A Comparative Analysis of LIME and SHAP Interpreters for Diabetes Prediction. IEEE Access, 12. https://doi.org/10.1109/ACCESS.2024.3422319
- Rosenbacke, R., Melhus, Å., McKee, M., Stuckler, D. (2024). How Explainable Artificial Intelligence Can Increase or Decrease Clinicians’ Trust in AI Applications in Health Care: Systematic Review. JMIR AI, 3, e53207. https://doi.org/10.2196/53207
- Rudin, C. (2019). Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nature Machine Intelligence, 1(5), 206–215. https://doi.org/10.1038/s42256-019-0048-x
- Salih, A. M., Raisi-Estabragh, Z., Galazzo, I. B., Radeva, P., Petersen, S. E., Lekadir, K., Menegaz, G. (2025). A Perspective on Explainable Artificial Intelligence Methods: SHAP and LIME. Advanced Intelligent Systems, 7, 2400304. https://doi.org/10.1002/aisy.202400304
- Tonekaboni, S., Joshi, S., McCradden, M. D., Goldenberg, A. (2019). What Clinicians Want: Contextualizing Explainable Machine Learning for Clinical End Use. Proceedings of the 4th Machine Learning for Healthcare Conference (PMLR), 106, 359–380.
- Topol, E. J. (2019). Deep Medicine: How Artificial Intelligence Can Make Healthcare Human Again. Basic Books.
- (WEB1) Regulation (EU) 2024/1689 — European Artificial Intelligence Act. https://eur-lex.europa.eu/eli/reg/2024/1689/oj