Demokracja coraz częściej rozgrywa się nie tylko w parlamentach, studiach telewizyjnych i lokalach wyborczych, ale także w strumieniach danych: postach, komentarzach, reakcjach, hasztagach i rekomendacjach algorytmów. Big data oraz analiza sentymentu mogą pomagać badaczom lepiej rozumieć nastroje społeczne, polaryzację i dynamikę konfliktów politycznych. Jednocześnie te same narzędzia mogą służyć mikrotargetowaniu, manipulacji informacją, automatyzacji propagandy i naruszaniu prywatności obywateli. Główna teza tego artykułu brzmi: analiza danych politycznych nie jest z definicji antydemokratyczna, ale bez przejrzystości, kontroli społecznej i ograniczeń etycznych może przesunąć demokrację w stronę systemu zarządzania emocjami wyborców.
Wstęp: demokracja jako system informacji
W klasycznym ujęciu demokracja opiera się na debacie publicznej, pluralizmie opinii, wolnych wyborach i świadomym obywatelu. W praktyce zawsze była jednak także systemem przepływu informacji. Partie polityczne próbowały rozpoznawać nastroje społeczne, media selekcjonowały tematy, sondażownie mierzyły preferencje wyborców, a kampanie wyborcze testowały hasła, plakaty i wystąpienia liderów. Nowość współczesnej sytuacji polega na skali, prędkości i automatyzacji tego procesu.
Dziś miliony obywateli codziennie zostawiają cyfrowe ślady: lajki na Facebooku, komentarze na TikToku, reposty na X, reakcje pod transmisjami live, wyszukiwania w Google, dane lokalizacyjne i historię kliknięć. Z punktu widzenia nauk społecznych jest to ogromne archiwum emocji, konfliktów, lęków i aspiracji. Z punktu widzenia kampanii politycznych — potencjalna mapa podatności wyborców. Z punktu widzenia etyki — pole bardzo poważnych napięć.
Zeynep Tufekci już w 2014 roku pisała o „polityce obliczeniowej”, wskazując, że big data, indywidualizowane targetowanie, modele predykcyjne i eksperymenty prowadzone w czasie rzeczywistym zmieniają sposób działania kampanii politycznych (Tufekci, 2014). Jej diagnoza okazała się wyjątkowo trafna. Polityka coraz mniej przypomina jedną debatę publiczną, a coraz bardziej wiele równoległych, spersonalizowanych przekazów kierowanych do różnych segmentów społeczeństwa.
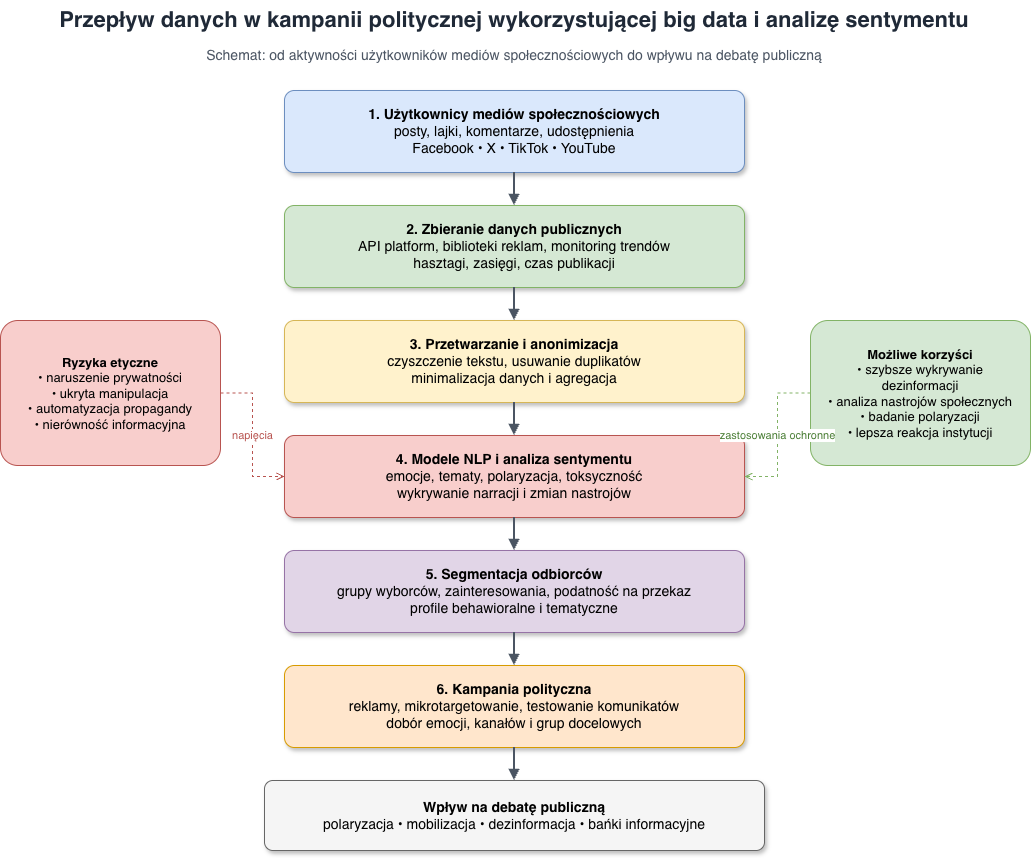
Rys. 1. Uproszczony przepływ danych w kampanii politycznej wykorzystującej big data i analizę sentymentu. Opracowanie własne na podstawie: Tufekci (2014), Barocas i Nissenbaum (2014), Woolley i Howard (2017).
Big data w polityce: od sondażu do ciągłego monitoringu
Czym jest big data w kontekście demokracji?
Big data w analizie politycznej oznacza wykorzystanie bardzo dużych, różnorodnych i szybko zmieniających się zbiorów danych do badania zachowań, opinii i emocji obywateli. W przeciwieństwie do tradycyjnego sondażu, który obejmuje ograniczoną próbę respondentów i konkretne pytania, analiza danych z mediów społecznościowych może obejmować miliony wypowiedzi pojawiających się spontanicznie, często w czasie rzeczywistym.
Dane te mogą pochodzić z wielu źródeł: publicznych postów na X, komentarzy na Facebooku, filmów i opisów na TikToku, forów internetowych, serwisów informacyjnych, newsletterów, reklam politycznych czy zbiorów udostępnianych przez platformy. W praktyce największą wartość mają nie pojedyncze wypowiedzi, ale wzorce: nagłe wzrosty zainteresowania tematem, zmiana tonu dyskusji, sieci kont wzajemnie wzmacniających przekaz, powtarzalne narracje lub emocjonalne reakcje na decyzje polityczne.
Co można dzięki temu badać?
Analiza big data może być użyteczna w badaniu demokracji na kilka sposobów. Po pierwsze, pozwala obserwować dynamikę sporów politycznych: które tematy eskalują, jakie grupy je podchwytują, kiedy konflikt przenosi się z marginesu do głównego nurtu. Po drugie, umożliwia analizę polaryzacji: czy użytkownicy rozmawiają ponad podziałami, czy raczej zamykają się w ideologicznych wspólnotach. Po trzecie, pozwala badać wpływ wydarzeń zewnętrznych — kryzysów migracyjnych, pandemii, wojny, inflacji — na emocje społeczne.
Przykładem może być analiza reakcji na debatę wyborczą. Tradycyjny komentarz medialny powie, który polityk „wypadł lepiej”. Analiza danych może natomiast pokazać, że jeden fragment debaty wywołał wzrost gniewu wśród zwolenników jednej partii, a inny został przejęty przez sieć kont rozpowszechniających memy. Taka analiza nie zastępuje interpretacji politologicznej, ale dostarcza materiału empirycznego, którego wcześniej nie było.
Analiza sentymentu: mierzenie emocji w debacie publicznej
Jak działają modele NLP?
Analiza sentymentu to technika przetwarzania języka naturalnego, której celem jest rozpoznanie emocjonalnego tonu wypowiedzi. Najprostsze modele klasyfikują tekst jako pozytywny, negatywny lub neutralny. Bardziej zaawansowane próbują wykrywać konkretne emocje: gniew, strach, pogardę, nadzieję, entuzjazm, smutek lub ironię.
W polityce analiza sentymentu może dotyczyć na przykład komentarzy pod wystąpieniem premiera, postów o konkretnym projekcie ustawy albo reakcji na spot kampanijny. Modele NLP mogą wykrywać, czy narracja wokół danego tematu staje się bardziej agresywna, czy rośnie poziom lęku, czy konkretne hasło wywołuje pozytywne skojarzenia. W badaniach nad mediami społecznościowymi analiza sentymentu jest często łączona z analizą sieciową, wykrywaniem tematów i klasyfikacją kont podejrzewanych o automatyzację.
Badania z ostatnich lat pokazują, że analiza sentymentu i uczenie maszynowe są coraz częściej wykorzystywane do badania polaryzacji politycznej na platformach takich jak Twitter/X. Przykładowo badanie dotyczące wyborów prezydenckich w Meksyku analizowało nastroje i polaryzację użytkowników Twittera, wskazując, że metody uczenia maszynowego mogą ujawniać strukturę konfliktu politycznego widoczną w danych społecznościowych (Valle-Cruz, 2024).
Ograniczenia analizy sentymentu
Problem polega na tym, że emocje polityczne są trudne do jednoznacznego zaklasyfikowania. Zdanie „świetnie, znowu podnieśli podatki” formalnie zawiera pozytywne słowo „świetnie”, ale sens wypowiedzi jest ironiczny. Podobnie memy, skróty, slang, kontekst lokalny i kody środowiskowe mogą wprowadzać modele w błąd. W polskiej debacie politycznej dodatkową trudnością są neologizmy, celowe przekręcanie nazwisk, emocjonalne etykiety i wieloznaczne hasła.
Dlatego analiza sentymentu nie powinna być traktowana jako obiektywny „termometr społeczeństwa”. Jest raczej narzędziem przybliżonego pomiaru, które wymaga walidacji, kontroli błędów i interpretacji jakościowej. W przeciwnym razie można pomylić głośność określonej grupy z opinią większości. To szczególnie niebezpieczne w polityce, gdzie błędna interpretacja danych może stać się podstawą realnych decyzji kampanijnych lub medialnych.
Algorytmy rekomendacyjne i bańki informacyjne
Platformy nie są neutralnym placem debaty
Facebook, X, TikTok i YouTube nie pokazują użytkownikom treści w sposób losowy ani czysto chronologiczny. O tym, co zobaczymy, decydują algorytmy rekomendacyjne optymalizowane najczęściej pod kątem zaangażowania: kliknięć, czasu oglądania, komentarzy, reakcji i udostępnień. Polityka idealnie pasuje do tego mechanizmu, ponieważ generuje silne emocje. Gniew, oburzenie i lęk zatrzymują uwagę użytkownika skuteczniej niż spokojna, ekspercka analiza.
W literaturze pojawia się tu pojęcie „bańki informacyjnej” lub „komory echa”. Eli Pariser spopularyzował tezę, że personalizacja treści może ograniczać kontakt z odmiennymi poglądami. Badanie Facebooka opublikowane przez Bakshy’ego, Messinga i Adamic pokazywało bardziej złożony obraz: zarówno algorytm, jak i wybory samych użytkowników wpływają na ograniczenie kontaktu z treściami przeciwnego obozu (Bakshy, Messing & Adamic, 2015). To ważne, bo spór nie brzmi: „czy winny jest człowiek, czy algorytm?”, lecz raczej: jak zachowania użytkowników i logika platform wzajemnie się wzmacniają.
Polaryzacja jako produkt uboczny modelu biznesowego
Pew Research Center wskazywał, że algorytmiczne kategoryzowanie może pogłębiać podziały społeczne, ponieważ użytkownicy są coraz częściej kierowani do treści zgodnych z wcześniejszymi preferencjami (Pew Research Center, 2017). Nie oznacza to, że każda rekomendacja polityczna jest manipulacją. Oznacza jednak, że system nastawiony na maksymalizację zaangażowania może premiować treści skrajne, konfliktowe i upraszczające rzeczywistość.
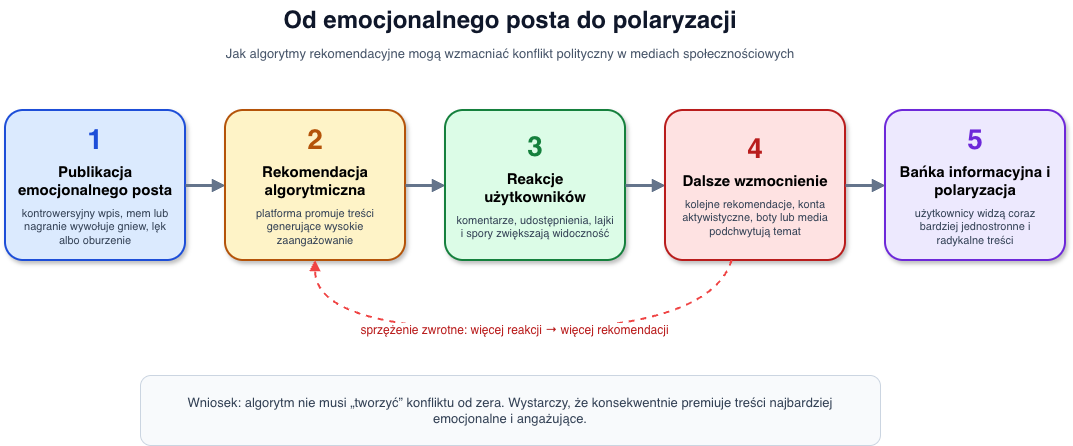
Rys. 2. Schemat wzmacniania polaryzacji przez logikę rekomendacji. Opracowanie własne.
Mikrotargetowanie polityczne: demokracja wielu prywatnych przekazów
Cambridge Analytica jako punkt zwrotny
Najbardziej znanym przykładem nadużycia danych politycznych pozostaje afera Cambridge Analytica. Dane milionów użytkowników Facebooka zostały pozyskane przez aplikację badawczą i wykorzystane do budowania profili psychologicznych oraz targetowania przekazów politycznych. Facebook później informował, że sprawa mogła dotyczyć nawet 87 milionów profili. Znaczenie tej afery nie polega wyłącznie na tym, czy Cambridge Analytica faktycznie „wygrała wybory” Donaldowi Trumpowi albo przesądziła o Brexicie. Badacze i dziennikarze spierają się o realną skuteczność psychograficznego targetowania. Ważniejsze jest coś innego: skandal pokazał, że dane obywateli mogą zostać przekształcone w narzędzie politycznego wpływu bez świadomej zgody i bez publicznej kontroli.
To właśnie tu pojawia się zasadniczy problem etyczny. W tradycyjnej kampanii wyborczej plakat na ulicy albo debata telewizyjna są widoczne dla wszystkich. Można je skrytykować, porównać, sprawdzić. Mikrotargetowana reklama polityczna jest często prywatna: jedna grupa widzi przekaz o bezpieczeństwie, inna o podatkach, jeszcze inna o zagrożeniu kulturowym. Wspólna sfera publiczna rozpada się na tysiące spersonalizowanych komunikatów.

Obrazek 1. Przesłuchanie CEO Facebooka w sprawie afery Cambridge Analytica. Źródło: tenor.com.
Argumenty za i przeciw mikrotargetowaniu
Zwolennicy mikrotargetowania twierdzą, że pozwala ono lepiej dopasować przekaz do realnych potrzeb obywateli. Młodzi rodzice mogą dostać informacje o żłobkach, przedsiębiorcy o podatkach, studenci o mieszkalnictwie, a mieszkańcy mniejszych miejscowości o transporcie publicznym. Z tej perspektywy personalizacja zwiększa efektywność komunikacji politycznej i może ułatwiać obywatelowi dotarcie do informacji, które faktycznie go dotyczą.
Przeciwnicy odpowiadają, że ta sama technika może służyć ukrywaniu sprzecznych obietnic, eksploatowaniu lęków i zniechęcaniu wybranych grup do udziału w wyborach. Problemem nie jest więc samo segmentowanie odbiorców, lecz brak przejrzystości, asymetria wiedzy i możliwość testowania manipulacyjnych komunikatów bez społecznego nadzoru.
| Obszar | Potencjalna korzyść | Ryzyko demokratyczne |
|---|---|---|
| Analiza sentymentu | Szybkie rozpoznanie nastrojów społecznych | Redukcja obywateli do emocjonalnych wskaźników |
| Mikrotargetowanie | Dopasowanie informacji do grup odbiorców | Ukryta manipulacja i niespójne obietnice |
| Algorytmy rekomendacyjne | Łatwiejszy dostęp do interesujących treści | Bańki informacyjne i radykalizacja |
| Wykrywanie botów | Ochrona debaty przed sztucznym wpływem | Ryzyko błędnego oznaczania autentycznych użytkowników |
| Monitoring dezinformacji | Wczesne ostrzeganie społeczeństwa | Niebezpieczeństwo nadmiernej kontroli wypowiedzi |
Dezinformacja, boty i sztuczne wzmacnianie konfliktu
Współczesna manipulacja informacyjna nie musi polegać na przekonaniu wszystkich do jednej fałszywej tezy. Często wystarczy zalać debatę sprzecznymi narracjami, osłabić zaufanie do instytucji i sprawić, że obywatele przestaną wierzyć w możliwość ustalenia faktów. To szczególnie niebezpieczne w okresach wyborczych, podczas kryzysów bezpieczeństwa lub protestów społecznych.
Oxford Internet Institute badał zjawisko propagandy obliczeniowej, czyli wykorzystywania botów, automatyzacji i zorganizowanych kampanii w mediach społecznościowych do manipulowania opinią publiczną. Raport zespołu Woolleya i Howarda obejmował wiele państw, platform i sytuacji politycznych, pokazując, że problem nie dotyczy wyłącznie jednego kraju czy jednej kampanii (Woolley & Howard, 2017). Takie działania mogą tworzyć fałszywe wrażenie społecznego poparcia, przyspieszać rozprzestrzenianie dezinformacji i zwiększać agresję w dyskusjach publicznych.
Również NATO Strategic Communications Centre of Excellence zwracało uwagę na skalę manipulacji w mediach społecznościowych i trudności z rozpoznawaniem sztucznego ruchu. Nie oznacza to, że każdy konflikt polityczny jest „sterowany przez boty”, ale pokazuje, że infrastruktura sztucznego wpływu istnieje i może być wykorzystywana w sposób masowy.
Film 1. Krótkie wyjaśnienie, jak boty mogą manipulować dyskusją w mediach społecznościowych. Źródło: BBC / YouTube.
Prywatność obywateli: od zgody do przewidywania zachowań
Jednym z najważniejszych problemów etycznych jest prywatność. W klasycznym modelu ochrony danych zakładano, że użytkownik może wyrazić zgodę na przetwarzanie informacji, a dane można zanonimizować. Barocas i Nissenbaum argumentowali jednak, że big data obchodzi tradycyjne zabezpieczenia prywatności: nawet jeśli pojedyncze dane są anonimowe, ich łączenie może umożliwiać profilowanie, przewidywanie i klasyfikowanie ludzi (Barocas & Nissenbaum, 2014).
W polityce to szczególnie wrażliwe. Preferencje wyborcze, lęki społeczne, poglądy religijne, stosunek do migracji, orientacja światopoglądowa czy reakcje na wojnę mogą zostać użyte do kształtowania przekazu. Nawet jeśli użytkownik nie ujawnił wprost swoich poglądów, model może je przewidywać na podstawie zachowań. To przesuwa demokrację z przestrzeni argumentacji do przestrzeni predykcji.
Demokracja potrzebuje danych, aby rozumieć społeczeństwo, ale nie może pozwolić, by społeczeństwo zostało zredukowane do zestawu podatności behawioralnych. Obywatel nie jest wyłącznie rekordem w bazie, segmentem reklamowym ani prawdopodobieństwem kliknięcia. Jest uczestnikiem wspólnoty politycznej, który powinien wiedzieć, kto próbuje na niego wpływać, za pomocą jakich danych i w jakim celu.
Komponent krytyczny: dwa spojrzenia na analizę danych politycznych
Stanowisko optymistyczne: więcej danych, lepsza demokracja
Pierwsze stanowisko można nazwać technokratyczno-optymistycznym. Zakłada ono, że analiza danych może zwiększyć responsywność instytucji publicznych. Jeśli rząd, samorząd lub organizacja społeczna szybciej zauważy narastające problemy, może szybciej reagować. Analiza sentymentu może pomóc wykryć niezadowolenie z usług publicznych, obawy przed reformą albo dezinformację zagrażającą bezpieczeństwu. W tym sensie big data może uzupełnić demokrację przedstawicielską o bardziej ciągłe „słuchanie społeczeństwa”.
Jest w tym racja. Nie należy odrzucać technologii tylko dlatego, że bywa nadużywana. Wykrywanie botów, mapowanie dezinformacji czy analiza polaryzacji mogą wzmacniać odporność demokracji. Problem polega jednak na tym, kto posiada dane, kto definiuje kategorie analizy i kto kontroluje wyniki. Ta sama technika, która służy obywatelskiej kontroli debaty, może zostać wykorzystana przez partię polityczną do testowania przekazów opartych na lęku.
Stanowisko krytyczne: demokracja jako rynek manipulacji
Drugie stanowisko jest bardziej pesymistyczne. Według niego platformy społecznościowe przekształciły debatę publiczną w rynek uwagi, na którym wygrywa treść najbardziej angażująca, a nie najbardziej prawdziwa. Allcott i Gentzkow analizowali problem fake newsów w wyborach prezydenckich w USA w 2016 roku, wskazując, że fałszywe informacje rozpowszechniane w mediach społecznościowych stały się istotnym elementem debaty o jakości wyborów (Allcott & Gentzkow, 2017).
Z tej perspektywy demokracja nie zostaje zniszczona jednym aktem cenzury, lecz stopniowo osłabiana przez chaos informacyjny, profilowanie i emocjonalne przeciążenie obywateli. Jeśli każdy widzi inną wersję kampanii, jeśli boty udają społeczne poparcie, jeśli algorytmy wzmacniają gniew, a reklamy polityczne są niewidoczne dla opinii publicznej, to wyborca formalnie nadal głosuje swobodnie, ale środowisko informacyjne, w którym podejmuje decyzję, jest głęboko przetworzone.
Nasza ocena: nie sama technologia, lecz asymetria władzy
Naszym zdaniem kluczowy problem nie polega na tym, że polityka korzysta z danych. Partie zawsze badały opinię publiczną. Różnica polega na asymetrii. Obywatel widzi pojedynczy post, reklamę albo film. Platforma i kampania widzą jego historię zachowań, segment podobnych użytkowników, przewidywane emocje i prawdopodobieństwo reakcji. To nierównowaga poznawcza.
Dlatego najważniejsze pytanie etyczne brzmi: czy obywatel ma realną możliwość zrozumienia i zakwestionowania procesu wpływu? Jeśli nie, analiza danych politycznych staje się narzędziem władzy ukrytej za interfejsem aplikacji. W demokratycznym państwie nie chodzi tylko o to, by obywatel mógł oddać głos, ale również o to, by jego decyzja nie była wynikiem niewidzialnego eksperymentu behawioralnego.
Regulacje: próba odzyskania przejrzystości
Unia Europejska próbuje odpowiedzieć na te problemy poprzez regulacje dotyczące platform cyfrowych i reklamy politycznej. Digital Services Act wprowadza obowiązki dotyczące przejrzystości platform, mechanizmów zgłaszania nielegalnych treści oraz dostępu badaczy do danych platformowych. Z kolei rozporządzenie UE 2024/900 dotyczące przejrzystości i targetowania reklamy politycznej ma przeciwdziałać niejasnym praktykom targetowania, manipulacji informacyjnej i zagranicznym ingerencjom. Komisja Europejska wskazuje, że nowe zasady dotyczące reklamy politycznej zaczęły obowiązywać 10 października 2025 roku, a ich celem jest między innymi zwiększenie jawności sponsorów, kosztów i metod targetowania reklam politycznych (European Commission, 2025).
To ważny kierunek, choć regulacje nie rozwiązują wszystkiego. Platformy mogą ograniczać reklamy polityczne zamiast zwiększać przejrzystość, a manipulacja może przenosić się z oficjalnych reklam do influencerów, grup zamkniętych, memów i treści generowanych przez AI. W 2025 roku Meta zapowiedziała wycofanie reklam politycznych, wyborczych i społecznych w Unii Europejskiej, argumentując to trudnościami operacyjnymi i niepewnością prawną związaną z nowymi przepisami. Ten przykład pokazuje, że regulacja platform staje się realnym polem konfliktu między państwami, biznesem technologicznym i aktorami politycznymi.
Literatura
- Allcott, H., & Gentzkow, M. (2017). Social media and fake news in the 2016 election. Journal of Economic Perspectives, 31(2), 211–236. https://www.aeaweb.org/articles?id=10.1257/jep.31.2.211
- Bakshy, E., Messing, S., & Adamic, L. A. (2015). Exposure to ideologically diverse news and opinion on Facebook. Science, 348(6239), 1130–1132. https://www.science.org/doi/10.1126/science.aaa1160
- Barocas, S., & Nissenbaum, H. (2014). Big data’s end run around anonymity and consent. In J. Lane, V. Stodden, S. Bender, & H. Nissenbaum (Eds.), Privacy, Big Data, and the Public Good. Cambridge University Press. https://nissenbaum.tech.cornell.edu/papers/Big%20Datas%20End%20Run%20Around%20Procedural%20Protections.pdf
- European Commission. (2025). Transparency and targeting of political advertising. https://commission.europa.eu/strategy-and-policy/policies/justice-and-fundamental-rights/democracy-eu-citizenship-anti-corruption/democracy-and-electoral-rights/transparency-and-targeting-political-advertising_en
- European Commission. (2025). FAQs: DSA data access for researchers. https://algorithmic-transparency.ec.europa.eu/news/faqs-dsa-data-access-researchers-2025-07-03_en
- Meta. (2025). Ending political, electoral and social issue advertising in the EU. https://about.fb.com/news/2025/07/ending-political-electoral-and-social-issue-advertising-in-the-eu/
- NATO Strategic Communications Centre of Excellence. (2022). Social media manipulation 2021/2022. https://stratcomcoe.org/publications/download/Social-media-manipulation-2021_2022-F.pdf
- Pew Research Center. (2017). Theme 5: Algorithmic categorizations deepen divides. https://www.pewresearch.org/internet/2017/02/08/theme-5-algorithmic-categorizations-deepen-divides/
- Tufekci, Z. (2014). Engineering the public: Big data, surveillance and computational politics. First Monday, 19(7). https://firstmonday.org/ojs/index.php/fm/article/view/4901/4097
- Valle-Cruz, D. (2024). Unveiling political polarization on Twitter: Machine learning and sentiment analysis in political discourse. eJournal of eDemocracy and Open Government. https://jedem.org/index.php/jedem/article/view/846
- Woolley, S. C., & Howard, P. N. (2017). Computational propaganda worldwide: Executive summary. Oxford Internet Institute. https://demtech.oii.ox.ac.uk/research/posts/computational-propaganda-worldwide-executive-summary/